1 基本信息
Beautiful Soup是用于处理解析页面信息的
具体的说, Beautiful Soup库是解析, 遍历, 维护"标签树"的功能库
安装方法
pip install beautifulsoup4
最基本的使用
import requests
from bs4 import BeautifulSoup
r = requests.get("http://www.baidu.com")
soup = BeautifulSoup(r.content, 'html.parser')
print(soup.prettify())
2 基本元素
Beautiful Soup处理的内容文档一般是HTML页面
HTML页面是标签对形成的
这些标签对最终会形成标签树, 这些标签树实际上是Beautiful Soup类
也就是 HTML文档<---->标签树<---->Beautiful Soup类
Beautiful Soup的解析器

最主要的还是是用 html.parser解析器
Beautiful Soup类的基本元素

使用方法如下:
1) Tag标签
使用方法
BS对象.标签名字
soup.a
soup.title
其中如果该标签在页面存在多个, 那么只返回第一个
2) name
使用方法
BS对象.标签名字.name
3) attrs
使用方法
其中attrs获得的是一个字典类型的值
通过属性名字得到的就是列表类型
BS对象.标签名字.attrs
BS对象.标签名字.attrs['某个属性的名字']
soup.a.sttrs
soup.a.attrs['class']
4) NavigableString
表示的是标签内非属性的字符串, 使用如下
其中string如果该标签内存在别的标签嵌套, 获得的就是嵌套内部的string
因此, NavigableString可以跨越多个层次
BS对象.标签名字.string
5) Comment
标签内注释部分
获取方法和NavigableString相同, 都是通过string来获得
3 标签树的遍历
遍历分为 下行遍历, 上行遍历, 平行遍历
上行遍历的主要有: contents, children, descendants
其中contens获得的是标签的所有内容
children或的是contents的具体的列表, 其中' '会被当做一个元素
descendants和children都是生成器, descendants会逐步往下遍历打印出所有子孙节点
上行遍历主要有: parent, parents
parent获得的是父亲节点, 获得的父亲节点包括该节点内的所有内容, 是一个很丰富的节点
parents是一个生成器, 倒数第二个是<html>标签. 最后一个是整个文档
平行遍历主要有: next_sibling, previous_sibling, next_siblings, previous_siblings
注意: 平行是指的在一个父节点下的子节点间的
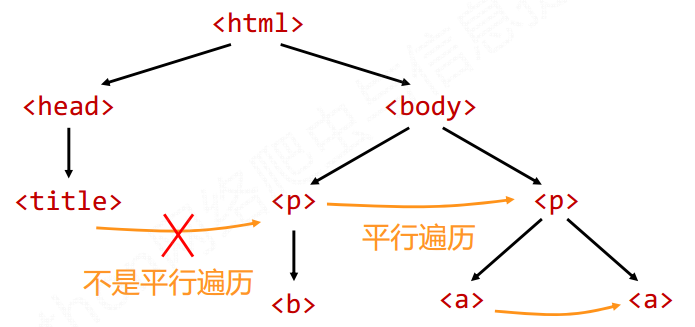
其中next_sibling和previous_sibling是返回下一个或者上一个平行节点标签
next_siblings和previous_siblings是返回生成器类型
4 信息和组织方法
主要主流的有三种, XML, JSON, YAML
XML的主要形式
<person>
<firstName>Tian</firstName>
<lastName>Song</lastName>
<address>
<streetAddr>中关村南大街5号</streetAddr>
<city>北京市</city>
<zipcode>100081</zipcode>
</address>
<prof>Computer System</prof><prof>Security</prof>
</person>
JSON的主要形式
{
“firstName” : “Tian” ,
“lastName” : “Song” ,
“address” : {
“streetAddr” : “中关村南大街5号” ,
“city” : “北京市” ,
“zipcode” : “100081”
} ,
“prof” : [ “Computer System” , “Security” ]
}
YANL的主要形式
firstName : Tian
lastName : Song
address :
streetAddr : 中关村南大街5号
city : 北京市
zipcode : 100081
prof :
‐Computer System
‐Security
三种类型的对比
XML: 可扩展性好, 但是繁琐, 主要用于网络传递信息
JSON: 信息有类型, 适合程序处理, 没有注释, 主要用于移动应用云端和节点的通信
YAML: 无类型, 信息比例高, 可读性好, 各类系统的配置文件
5 基于bs4的HTML的查找
最基本find_all()方法的解析
BS对象.fand_all(name, attrs, recursive, string, **kwargs)
name: 是对标签名称的检索, 返回一个list类型,
如果需要对多个标签查询, 可以组成一个list传给name
name=True 表示显示当前BS对象的 所有标签信息
还可以用正则表达式来匹配名字
attrs: 对标签属性值的检索
可以直接传入参数
也可是使用键值对的方式
recursive: 是否符子孙全部检索, 默认为True
如果赋值为False的话, 就是从当前对象的子节点进行查找
string: 对字符串信息检索
由于find_all()方法是十分常用, 所以有一个简写形式
标签.fand_all() 简写为: 标签()
soup.find_all() 简写为: soup()
扩展方法

6 基于BS库的爬虫实例
实例一: 爬取大学排名
爬取地址: http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html
实现对大学排名的信息的爬取
查看该HTML页面发现, 多有的排名信息都是<tbody>下的子节点
该子节点下的每一个<tr>就是一个排名信息
由于在find_all()的过程中可能出现查找的不是一个标签, 所以需要一个判断是否为标签的判断
具体实例如下
import requests
from bs4 import BeautifulSoup
import bs4
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def fillUnivList(ulist, html):
soup = BeautifulSoup(html, "html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
tds = tr('td')
ulist.append([tds[0].string, tds[1].string, tds[2].string])
def printUnivList(ulist, num):
tplt = "{0:^10} {1:{3}^10} {2:^10}"
print(tplt.format("排名","学校名称","总分",chr(12288)))
for i in range(num):
u=ulist[i]
print(tplt.format(u[0],u[1],u[2],chr(12288)))
def main():
uinfo = []
url = 'http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html'
html = getHTMLText(url)
fillUnivList(uinfo, html)
printUnivList(uinfo, 20) # 20 univs
main()
实例二: 爬取PAT乙类的试题列表
具体代码如下
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
__author__ = 'weihuchao'
import requests
from bs4 import BeautifulSoup
import bs4
def getPAT(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
print("获取PAT失败")
def getUrlList(ulist, content):
soup = BeautifulSoup(content, "html.parser")
for tr in soup.find("table").children:
if isinstance(tr, bs4.element.Tag):
if tr.name == "tr":
tds = tr('td')
href = "https://www.patest.cn"
name = ""
seq = tds[0].string
try:
href += tds[1].contents[0].attrs['href']
name += tds[1].string
except:
pass
ulist.append([seq, name, href])
def printUrlList(ulist):
tplt = "{0:^2} {1:{3}^30} {2:^50}"
print(tplt.format("编号","试题名称","地址",chr(12288)))
for i in ulist:
print(tplt.format(i[0], i[1], i[2], chr(12288)))
def main():
ulist = []
url = "https://www.patest.cn/contests/pat-b-practise"
content = getPAT(url)
getUrlList(ulist, content)
printUrlList(ulist)
if __name__ == "__main__":
main()