正则表达式基础
1、元字符

2、限定符

3、字符类
要想匹配包含某些字符可以使用[],如“[a-z0-9A-Z]”
4、排查字符
可以使用[^a-zA-Z]
5、选择字符
可以通过(|)来实现,如匹配身份证号码:(^d{15}$)|(^d{18}$)|(^d{17})(d|X|x)$
6、转义字符
正则表达式中的转义字符()和python中的大同小异,都是将特殊字符(如“,”?""等)变为普通的字符。举一个IP地址的实例,用正则表达式匹配诸如“127.0.0.1”这样格式的IP地址。
[1-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}
7、分组
(six|four)th,用来匹配sixth或是fourth.
对如上ip地址匹配语句可以优化为:[1-9]{1,3}(.[0-9]{1,3}){3}
使用re模块实现正则表达式操作
1、使用match()方法进行匹配
match()方法用于从字符串的开始进行匹配,如果在起始位置配置成功,则返回Match对象,否则返回None,语法格式如下:
re.match(pattern,string,[flags])
参数说明:
pattern:表示模式字符串,由要匹配的正则表达式转换而来
string:表示要匹配的字符串
flags:可选参数,表示标志位,用于控制匹配方式,如是否区分字母大小写,常用标志如下:

例如,匹配字符串是否以“mr_”开头,不区分字母大小写,代码如下

match对象中包含了匹配值的位置和匹配数据。其中,要获取匹配值的起始位置可以使用match对象的start()方法;要获取匹配值的结束位置可以使用end()方法;通过span()方法可以返回匹配位置的元组;通过string属性可以获取要匹配的字符串。如下代码


2、使用search()方法进行匹配
search()方法用于在整个字符串中搜索第一个匹配的值,如果匹配成功,则返回match对象,否则返回None,语法格式如下:
re.search(pattern,string,[flags])
参数说明:
pattern:表示模式字符串,由要匹配的正则表达式转换而来
string:表示要匹配的字符串。
flags:可选参数,表示标志位,用于控制匹配方式,如是否区分字母大小写。
例如:搜索第一个以“mr_”开头的字符串,不区分字母大小写,代码如下:

3、使用findall()方法进行匹配
findall()方法用于在整个字符串中搜索所有符合正则表达式的字符串,并以列表的形式返回。如果匹配成功,则返回包含匹配结构的列表,否则返回空列表。语法格式:
re.findall(pattern,string,[flags])
参数说明:
pattern:表示模式字符串,由要匹配的正则表达式转换而来
string:表示要匹配的字符串。
flags:可选参数,表示标志位,用于控制匹配方式,如是否区分字母大小写。
例如:搜索以"mr_"开头的字符串,代码如下:

如果在指定的模式字符串中,包含分组,则返回与分组匹配的文本列表。例如

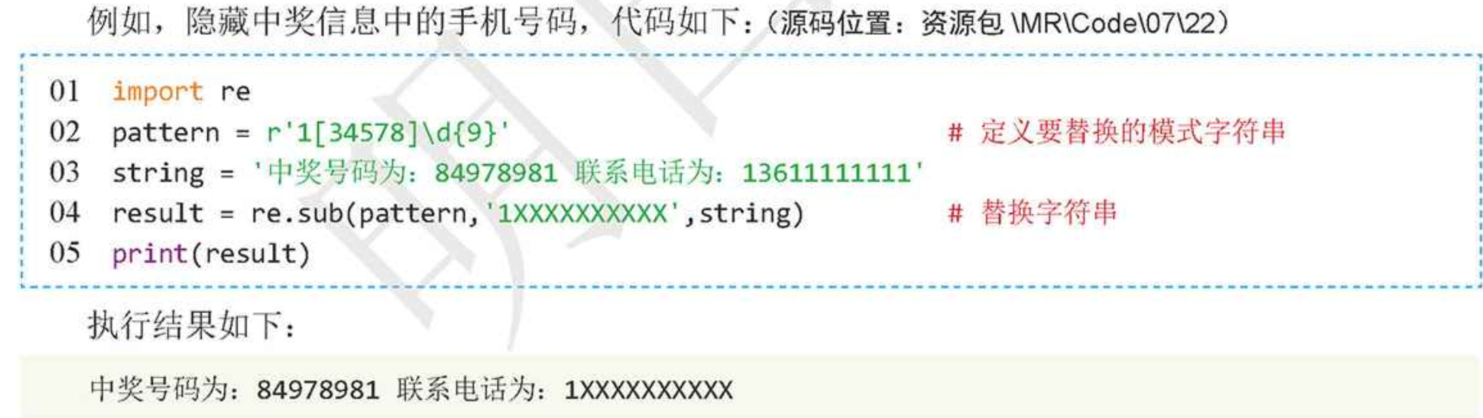
4、替换字符串
sub()方法用于实现字符串替换,语法格式如下:
re.sub(pattern,repl,string,count,flags)
参数说明:
pattern:表示模式字符串,由要匹配的正则表达式转换而来
repl:表示替换的字符串
string:表示要被查找替换的原始字符串
count:可选参数,表示模式匹配后替换的最大次数,默认值为0,表示替换所有的匹配。
flags:可选参数,表示标志位,用于控制匹配方式,如是否区分字母大小写。
5、使用正则表达式分割字符串
split()方法用于实现根据正则表达式分割字符串,并以列表的形式返回,其作用与字符串对象的split()方法类似,所不同的就是分割字符由模式字符串指定。语法格式如下:
re.split(pattern,string,[maxsplit],[flags])
