1、and或or
v= 1 and 3 and 2 print(v) 2 v= 1 and 3 and 0 print(v) 0 v = 1 or 2 or 0 print(v) 1 v = 1 and 2 or 0 print(v) 2
Python中的and从左到右计算表达式,若所有的值均为真,则返回最后一个值,若存在假,返回第一个假值
or也是从左到右计算表达式,返回第一个为真的值
2、GIL锁
全局解释器锁,同一时刻只能有一个线程访问CPU,锁的是线程,线程本身可以在同一时间使用多个CPU,Cpython解释器防止在解释代码的过程中产生数据不安全问题。
3、is和==的区别
Python中包含三个基本元素:ID(身份标识),type(数据类型),value(值)
其中ID用来唯一标识一个对象,type标识对象类型,value标识对象的一个值
is判断的是a对象是否就是b对象,是通过ID来判断
==判断的是a对象的值是否和b对象的值相等,是通过value来判断,,所以is 就是判断两个对象的id是否相同, 而 == 判断的则是内容是否相同。
4、 Python中的可变对象和不可变对象
不可变对象:对象所指向的内存中的值不能被改变,当改变这个变量的时候,原来指向的内存中的值不变,变量不再指向原来的值,而是开辟一块新的内存,变量指向新的内存。
通俗来讲变量值改变,id值也改变,例如:
a = 'hello' print(id(a)) a = a+'hi' print(id(a)) 1579546360552 1579547940488
数值类型int 、float、 字符串str 、元祖tuple、boole 都是不可变对象
可变对象:对象指向的内存中的值会改变,当更改这个变量的时候,还是指向原来内存中的值,并且在原来的内存值进行原地修改,并没有开辟新的内存。
dic = {
'name':'alex',
'age':18
}
print(id(dic))
dic['hobby']='lanqiu '
print(id(dic))
1579542439176
1579542439176
列表list、集合set、字典dict都是可变对象
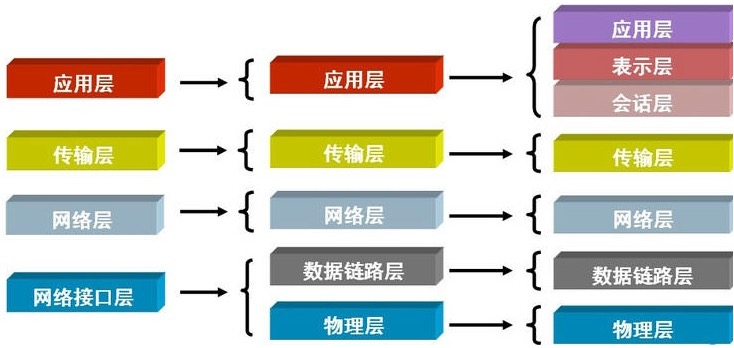
5、osi七层协议复习总结
6、TCP与UDP的复习总结
TCP:传输控制协议,是一种面向连接的、可靠地字节流服务,当客户端与服务端交换数据时,首先要建立起一个TCP链接,之后才传输数据,TCP提供超市重传,丢弃重复数据,检查数据,流量控制等功能。保证数据从一段传到另一端。
UDP:用户数据包协议,是一个简单的面向数据包的传输层协议,尽最大努力交付报文。传输速度比较快,容易丢包。
7、阻塞IO,非阻塞IO
IO的操作分为两步,等待数据准备和将数据从操作系统内核拷贝至内存,阻塞IO是指一直等待数据准备好拿到数据。非阻塞IO是指当用户进程发出read操作时,如果kernel中的数据还没有准备好,那么它并不会block用户进程,而是立刻返回一个error。从用户进程角度讲 ,它发起一个read操作后,并不需要等待,而是马上就得到了一个结果。用户进程判断结果是一个error时,它就知道数据还没有准备好,于是它可以再次发送read操作。一旦kernel中的数据准备好了,并且又再次收到了用户进程的system call,那么它马上就将数据拷贝到了用户内存,然后返回。
8、同步和异步
所谓同步就是一个任务的完成需要依赖另外一个任务时,只有等待被依赖的任务完成后,依赖的任务才能算完成,这是一种可靠的任务序列。要么成功都成功,失败都失败,两个任务的状态可以保持一致。
所谓异步是不需要等待被依赖的任务完成,只是通知被依赖的任务要完成什么工作,依赖的任务也立即执行,只要自己完成了整个任务就算完成了。至于被依赖的任务最终是否真正完成,依赖它的任务无法确定,所以它是不可靠的任务序列。
9、一行代码实现九九乘法表
for i in range(1,10):
for j in range(1,i+1):
print('{}*{}={}'.format(j,i,i*j) ,end=' ')
print('
',end='')
ret ='
'.join([ ' '.join(['{}*{}={}'.format(y,x,x*y) for y in range(1,x+1) ]) for x in range(1,10) ])
print(ret)
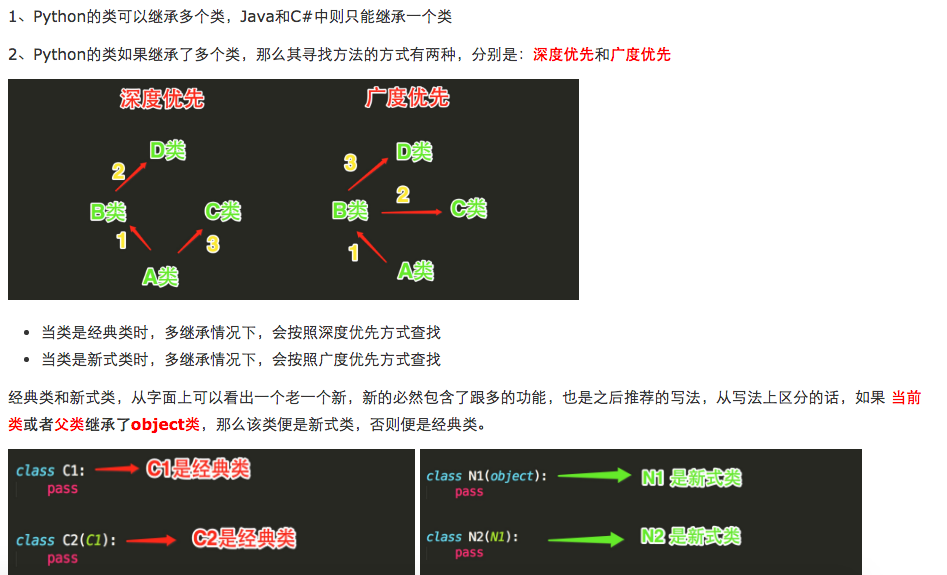
10、类的继承
11、*args和**kwargs
*args可以传递任意数量的的位置参数,以元组的形式存储
**kwargs可以传递任意数量的关键字参数,以字典的形式存储
*args和**kwargs可以同时定义在函数中,但必须*args放在**kwargs前面
def foo(*args,**kwargs):
print('*args',*args,)
print('args',args)
print('kwargs',kwargs)
foo(1,x=1,**{'name':'dog'})
结果
*args 1
args (1,)
kwargs {'x': 1, 'name': 'dog'}
12 、lambda函数
lambda函数比较方便,匿名函数,一般用来给filter,map这样的函数式编程服务,作为回调函数传递给某些应用,比如消息处理
13、装饰器
def outer(func,*args):
def inner(*args):
print('先洗苹果')
ret = func()
print('吃完了')
return ret
return inner
@outer
def eat():
print('吃苹果')
eat()
装饰器的本质:装饰器 = 高阶函数 + 函数嵌套 + 闭包
高阶函数:把函数当做参数传给另外一个函数,返回值中包含函数。
装饰器的功能:就是在不改变原函数的调用方式的情况下,在这个函数的前后加上扩展功能
14、作用域
1、作用域即范围:全局范围(内置名称空间和全局名称空间属于该范围):全局存活,全局有效 局部范围(局部名称空间属于该范围):临时存活,局部有效
2、作用域关系是在函数定义阶段就已经固定的,与函数调用的位置无关
3、查看作用域 :globals()全局变量,locals()局部变量
当 Python 遇到一个变量的话他会按照这样的顺序进行搜索:
本地作用域(Local)→当前作用域被嵌入的本地作用域(Enclosing locals)→全局/模块作用域(Global)→内置作用域(Built-in)
15、闭包函数
定义:如果在一个内部函数里,对在外部作用域(但不是在全局作用域)的变量进行引用,那么内部函数就被认为是闭包
创建一个闭包必须满足以下几点:
- 必须有一个内嵌函数
- 内嵌函数必须引用外部函数中的变量
- 外部函数的返回值必须是内嵌函数
def foo():
name = 'foo'
def inner():
print(name)
return inner
ret = foo()
ret()
16、cookies和session的区别
cookie的由来 :由于http请求是没有状态的,每次请求都是独立的。
什么是cookie:就是服务端设置然后保存在浏览器上的字符串、键值对
服务端控制着响应,在想盈利可以让浏览器在本地保存cookie键值对,下一次请求时携带这个cookie值。
cookie的应用:1、登录,七天免登录。2、记录用户浏览器习惯。3.简单的投票限制。
session是保存在字典里的键值对,必须依赖于cookie。
优势,相对于cookie安全,存数据多,但是占用资源。
17、Django中的MTV分别代表什么:
M代表什么model(模型):负责业务对象和数据对象
T代表Template(模板):负责如何把页面展示给用户
V代表Views(视图):负责业务逻辑,并在适当的时候调用model和template
18、什么是同源策略
同源策略是一种约定,它是浏览器最核心也是最基本的安全功能,如果缺少同源策略,则浏览器的正常功能都会受到影响,可以说web是构建在同源策略基础之上的,浏览器只是针对同源策略的一种实现。
所谓同源是指,域名,协议,端口相同。
19、jsonp
jsonp是json用来跨域的一个东西,原理是通过script标签的跨域特性来绕过同源策略
jsonp一定是GET请求
20、ajax常用的参数
URL:发送请求的地址
data:发送到服务器的数据,当前ajax请求要携带的数据,是一个json的object对象,ajax方法就会默认地把它编码成某种格式
processdata:生命当前data数据是否进行转码或者预处理,默认为True
contentType:默认值“application/x-www-form-urlencoded”,发送请求至服务器时内容编码类型,用来指明当前请求的数据编码格式,如果想以其他方式提交数据,即向服务器发送一个json字符串traditional:一般默认为True,一般是我们的data数据有数组时会用到 :data:{a:22,b:33,c:["x","y"]},traditional为false会对数据进行深层次迭代;
21、csrf
{% csrf_token %}
Django中内置了一个专门处理csrf问题的中间件
1、在render返回页面的时候,在页面塞了一个隐藏的input标签,
2、在提交post数据的时候,进行校验,如果校验不通过就拒绝这次请求。
22、数据库mysql知识点
mysql是基于一个socket编写的C/S架构的软件
视图:用户创建的一张虚拟表,用户只需要使用其名称即可获取结果,只可以做查询用。
触发器:对某张表进行增删改查时,对操作前后自定义操作。
存储过程:为了完成特定功能的sql语句集,进过编译后存储在数据库中,用户通过制定存储过程的名字并制定参数来调用存储过程。
存储过程的优点:
a、用于替代程序写sql语句,实现程序与sql的解耦
b、基于网络传输,传别名的数据量小,而直接传sql的数据量大
事务:事务用于将某些操作的多个SQL作为原子性操作,一旦有某一个出现错误,即可回滚到原来的状态,从而保证数据库数据的完整性
mysql的数据基本类型:
a、数值类型:整数类型,浮点型,位类型,
b、日期类型
c、字符串类型:char类型(固定长度),varchar类型(可变长度)
d、枚举类型(enum)和集合类型(set)
枚举类型(enum):单选,只能在给定的范围选一个值
集合类型(set) :多选,在给定的范围内选一个或者一个以上的值
22、生成器、迭代器和可迭代对象区别和应用?
生成器:1. 列表生成式的[ ]改为( ) 2. 函数中包含yield 3.生成器可以节省内存 4.生成器就是迭代器的一种
迭代器:可迭代对象执行obj.__iter__()得到的结果就是迭代器对象
为何要有迭代器?
对于序列类型:字符串、列表、元组,我们可以使用索引的方式迭代取出其包含的元素。但对于字典、集合、文件等类型是没有索引的,若还想取出其内部包含的元素,则必须找出一种不依赖于索引的迭代方式,这就是迭代器
可迭代对象:可迭代对象指的是内置有__iter__方法的对象
23、with 上下文机制原理?
上下文管理器是可以在with语句中使用,拥有__enter__和__exit__方法的对象。
# coding:utf-8
class Foo():
def __enter__(self):
print('开始了')
def __exit__(self, exc_type, exc_val, exc_tb):
print('结束了')
obj = Foo()
with obj:
print('我在中间')
24、staticmethod、classmethod,property
@property属性方法,仅有一个self参数,调用时不用加()。
@classmethod把一个方法变成类方法,不需要依托任何对象,当一个方法只使用了累的静态方法是,就给这个方法加上,默认传cls参数
@staticmethod在完全面向对象的过程中,如果一个函数既和对象没有关系,也和类没有关系,那么就用@staticmethod,将这个函数变成一个静态方法。类方法和静态方法都是类调用,类方法有一个默认参数cls,代表这个类,静态方法没有默认参数,就像函数一样。
class Foo():
@classmethod
def eat(cls):
print('吃屎')
@property
def play(self):
print('打篮球')
@staticmethod
def get():
print('name is dog')
Foo.eat()
Foo.get()
obj = Foo()
obj.play