一、Confluence的备份、恢复
1)Confluence的备份
管理员账号登录Confluence,点击右上角的"一般配置"-"每日备份管理",如下图(默认配置):

默认每天会自动备份一个zip打包的数据,存放在服务器的/var/atlassian/application-data/confluence/backups路径下。还可以点击"编辑"进行自定义。
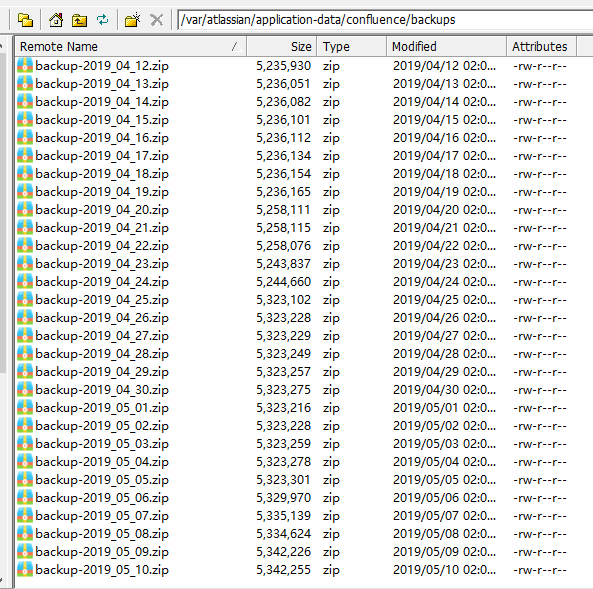
上面这是默认的整个Confluence的备份,默认每天2点左右都会整体备份一次!恢复或迁移的时候,可以直接用这里的zip打包数据进行恢复。除此之外,还可以点击"一般配置"-"备份与还原"里面的备份进行手动备份。
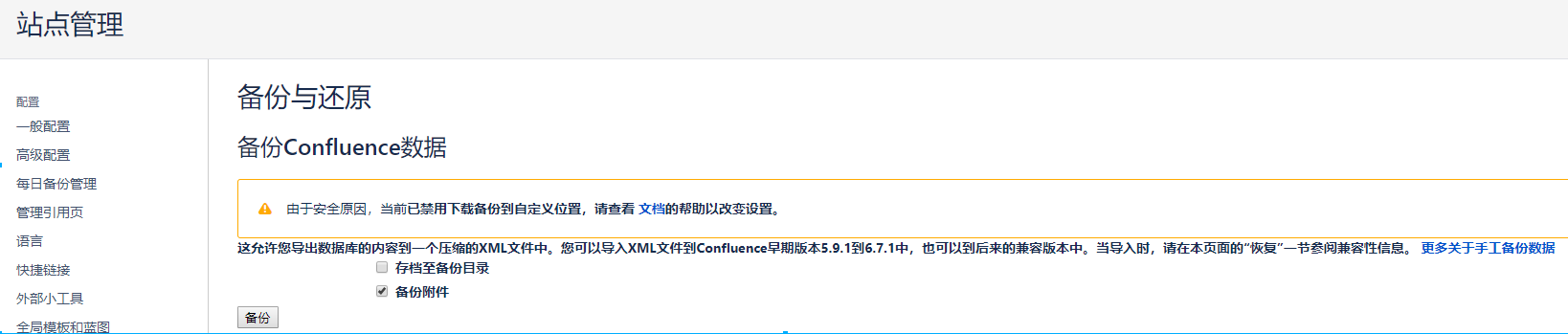
数据备份目录:/var/atlassian/application-data/confluence/backups ("站点管理"->"每日备份管理")
附件所在目录:/var/atlassian/application-data/confluence/attachments 注意附件数据要手动备份,可以写shell脚本定时备份。
除了上面的Confluence整体备份,还可以选择针对某个空间进行手动导出、导入的方式进行备份和恢复,这个一般是在迁移的时候用到。具体做法如下:
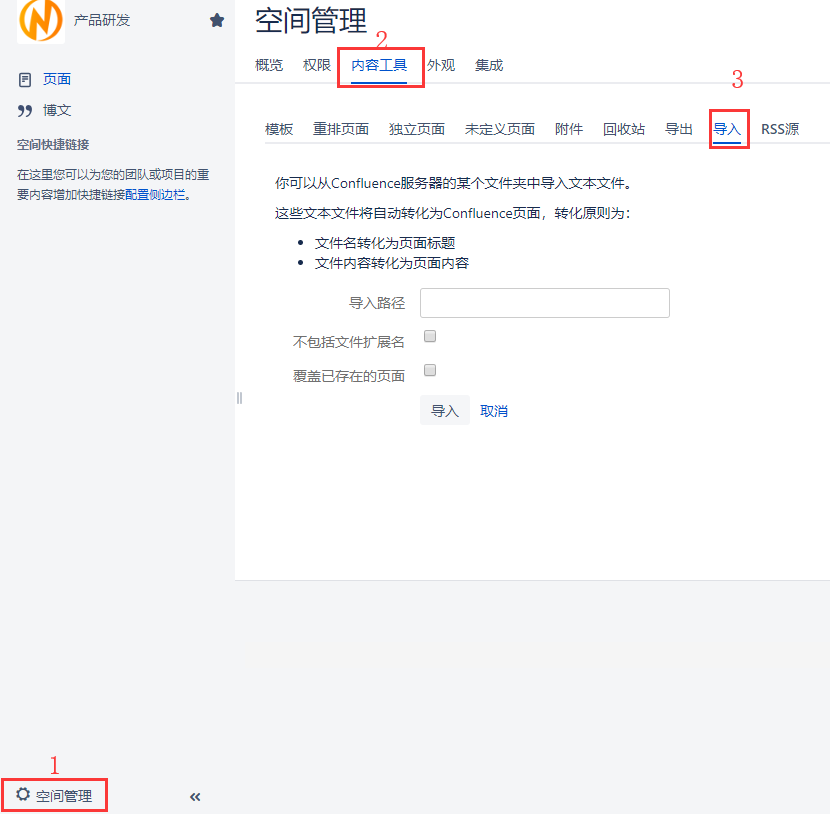
点开某个空间后,依次点击左下角的"空间管理"-"概览"-"内容工具"-"导出"(选择xml格式)

导出的文件一般会放在服务器的/var/atlassian/application-data/confluence/temp/路径下。

2)Confluence的恢复
可以点击"一般配置"-"备份与还原"里面的恢复进行数据恢复。可以将上面整体备份在/var/atlassian/application-data/confluence/backups里面的数据然后点击"上传和恢复"即可进行数据恢复。

当备份数据比较大时,可以将备份数据拷贝到/var/atlassian/application-data/confluence/restore路径下,从Confluence主目录中进行恢复。如下:

注意:针对某个空间的备份:
- 如果此空间不存在,则可以如同上面方法恢复数据:即将备份在/var/atlassian/application-data/confluence/temp/里面的数据拿到本地,然后点击"上传和恢复"即可进行数据恢复。
- 如果此空间已存在,则就不能使用上面方法,否则会报错"空间标识DATA已存在,请首先删除该空间,然后继续完成还原"。此种情况下,如果不删除该空间,则正确的数据恢复的方法是:点开该空间,分别点击左下角的"空间管理"-"概览"-"内容工具"-"导入",然后将服务器上备份数据的路径/var/atlassian/application-data/confluence/temp/ 填写到"导入路径",进行导入操作即可。
二、Jira、Confluence迁移/备份
先安装Jira, 后安装Confluence, 用Confluence去主动对接Jira.
首次迁移的时候, 需要注意下面几点:
第一步:
在新服务器上安装Jira环境。
第二步:
将老机器的jira库恢复到新机器的jira库中(新机器的jira库不要删除,在此jira库基础上进行导入)。
在导入老的jira库前, 一定要提前备份新服务器的jira库!
数据导入后,一定要重启Jira服务!然后尝试用老环境的jira用户登录新环境的jira,确保原用户能成功登录新的Jira环境(说明用户导入成功)。
第三步:
将老机器jira的备份数据(包括附件数据)逐个恢复到新机器的Jira环境里。
第四步:
在新服务器上安装Confluence环境,安装过程中,一定要记得对接新的Jira环境!对接后,使用原来的confluence账号应该是能成功登录新的Confluence。因为老账号已经通过jira导入到新环境中.
第五步:
将老机器的Confluence库恢复到新机器的Confluence库里(新机器的Confluence库不要删除,在此Confluence库基础上进行导入即可)。
导入前一定要备份新机器的Confluence库! 导入成功后, 要记得重启Confluence服务。
第六步:
将老Confluence的备份数据(包括附件数据)逐个恢复到新的Confluence环境里(如果整体恢复有错误,可以按照空间的备份数据一个个进行恢复)
需要注意:
如果是备机器, 备机器在第一次安装环境时, 备机器的jira/confluence需要按照上面的步骤跟主机器进行第一次数据同步;
后续过段时间,主机器的jira/confluence陆续又有新账号和新数据产生, 需要再次进行数据同步, 切记:
1) 备份备机器的jira库;
2) 将主机器的jira数据库导出来,并导入到备机器的jira库里(新机器的jira库不要删除,在此jira库基础上进行导入);
3) 数据导入后, 重启备机器的jira服务, 确保使用主机器新增的账号能成功登录备机器的jira环境, 说明用户导入成功;
4) 接着在备机器的confluence环境里, 主动进行跟jira的账号同步! 确保备机器的jira/confluence的账号先成功同步过来!
5) 最后再依次进行主机器jira/confluence应用数据到备机器的同步操作!
账号同步的坑很多, 稍不注意, 就会导致confluence账号登录不上的情况. 所以,后续同步时, 最好只是同步jira/confluence的备份数据;
每次在主机器新建账号的时候, 最好也在备机器创建一次,这样先确保主备环境的账号同步!