前言
什么是LRU算法,就是一种缓存淘汰策略。
计算机的缓存容量有限,如果缓存满了就要删除一些内容,给新内容腾位置。但问题是,删除哪些内容呢?我们肯定希望删掉哪些没什么用的缓存,而把有用的数据继续留在缓存里,方便之后继续使用。那么,什么样的数据,我们判定为「有用的」的数据呢?
LRU 缓存淘汰算法就是一种常用策略。LRU 的全称是 Least Recently Used,也就是说我们认为最近使用过的数据应该是是「有用的」,很久都没用过的数据应该是无用的,内存满了就优先删那些很久没用过的数据。
LRU缓存机制对应Leetcode 146。
运用你所掌握的数据结构,设计和实现一个 LRU (最近最少使用) 缓存机制。它应该支持以下操作: 获取数据 get 和 写入数据 put 。
获取数据 get(key) - 如果关键字 (key) 存在于缓存中,则获取关键字的值(总是正数),否则返回 -1。
写入数据 put(key, value) - 如果关键字已经存在,则变更其数据值;如果关键字不存在,则插入该组「关键字/值」。当缓存容量达到上限时,它应该在写入新数据之前删除最久未使用的数据值,从而为新的数据值留出空间。
你是否可以在 O(1) 时间复杂度内完成这两种操作?
示例:
LRUCache cache = new LRUCache( 2 /* 缓存容量 */ );
cache.put(1, 1);
cache.put(2, 2);
cache.get(1); // 返回 1
cache.put(3, 3); // 该操作会使得关键字 2 作废
cache.get(2); // 返回 -1 (未找到)
cache.put(4, 4); // 该操作会使得关键字 1 作废
cache.get(1); // 返回 -1 (未找到)
cache.get(3); // 返回 3
cache.get(4); // 返回 4
get操作: 有找到 返回值,并且将它置为"最近使用",没有找到 返回 -1
put操作:存在值 更新并且将它置为"最近使用",不存在值 容量够,增加,放在"最近使用"。容量不够 删除使用频次最少的 增加放在"最近使用"
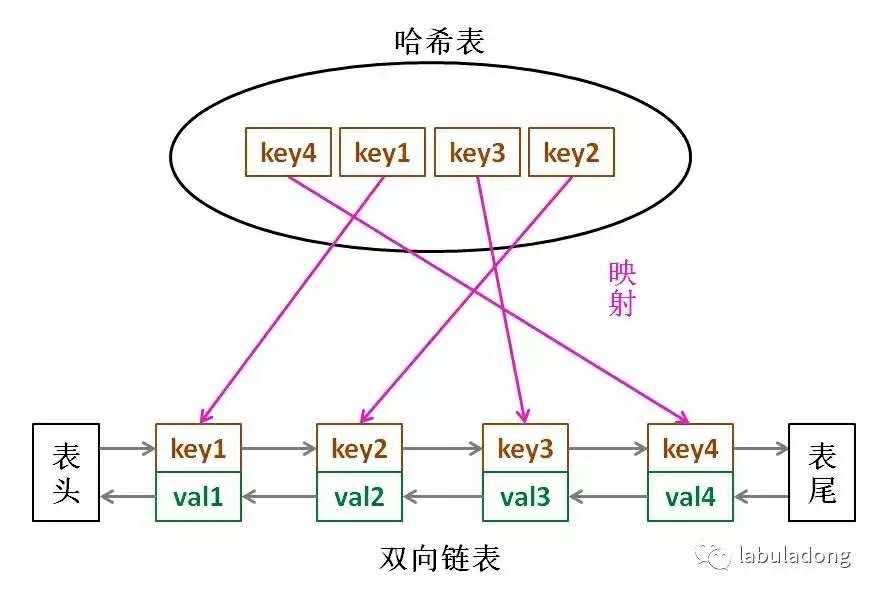
使用队列可以将刚使用的放在队列头,这样队列尾就是最近没使用的,淘汰的话先淘汰队列尾的,最近使用的放在队列头。单纯的队列是不行的,需要双向链表,比如我们想把中间的值提出来,想将这个值的前继节点和后继节点进行相连。
但是get操作无法O(1)get到操作,队列中只能遍历查找值。如果更快get到值可以使用HashMap的数据结构。
将两种数据结构相结合成哈希链表,如下图所示
代码实现
public class LRUCache {
private Map<Integer, LRUNode> map;
private DoubleList doubleList;
// 当前存储的数量
int capacity;
public LRUCache(int capacity) {
this.capacity = capacity;
map = new HashMap();
doubleList = new DoubleList();
}
// 有找到 返回值,并且将它置为最新使用
// 没有找到 返回 -1
public int get(int key) {
LRUNode lruNode = map.get(key);
if (lruNode == null) {
return -1;
} else {
put(key, lruNode.val);
return lruNode.val;
}
}
// 存在值 更新并且将它置为最新使用
// 不存在值 容量够,增加
// 容量不够 删除使用频次最少的 增加放在最近使用
public void put(int key, int value) {
LRUNode lruNode = map.get(key);
LRUNode toAddNode = new LRUNode(key, value);
if (lruNode != null) {
doubleList.delNode(lruNode);
doubleList.addFirst(toAddNode);
// 更新map 中存储的value
map.put(key, toAddNode);
} else {
if (doubleList.getListSize() == capacity) {
LRUNode last = doubleList.removeLast();
// LRUNode 中记录key 便于此处从map中删除指定key
map.remove(last.key);
}
doubleList.addFirst(toAddNode);
map.put(key, toAddNode);
}
}
class LRUNode {
int key;
int val;
LRUNode pre, next;
public LRUNode(int key, int val) {
this.key = key;
this.val = val;
}
}
class DoubleList {
/**
* 头尾虚节点 便于插入 和淘汰
*/
private LRUNode head, tail;
private int size;
public DoubleList() {
head = new LRUNode(0, 0);
tail = new LRUNode(0, 0);
head.next = tail;
tail.pre = head;
size = 0;
}
/**
* 往双向链表头部插入
*
* @param node
*/
public void addFirst(LRUNode node) {
node.next = head.next;
node.pre = head;
head.next.pre = node;
head.next = node;
size++;
}
/**
* 删除链表中x 节点 x一定存在
*
* @param x
*/
public void delNode(LRUNode x) {
x.pre.next = x.next;
x.next.pre = x.pre;
size--;
}
/**
* 删除结尾节点 返回该节点
*
* @return
*/
public LRUNode removeLast() {
if (tail.pre == head) {
return null;
}
LRUNode removeNode = tail.pre;
delNode(removeNode);
return removeNode;
}
/**
* 返回链表长度
*
* @return
*/
public int getListSize() {
return size;
}
}
}
很容易犯错的一点是:处理链表节点的同时不要忘了更新哈希表中对节点的映射。