之前在csdn上面看到了这篇博客关于讲HashMap得,感觉讲的还挺细致的,就拿出来分享下,顺便总结下。
HashMap连接:https://blog.csdn.net/QXJQQQ/article/details/78317385
在说HashMap之前,先简单说下Hash函数,毕竟HashMap1.7得底层对key得下标位置计算也是运用了Hash函数。index=H(key)。Hash函数得构造方法也是有很多种:(1)直接定制法 (2)数字分析法 (3)平方取中法 (4)折叠法 (5)除留余数法。 除留余数法是最常用得,这里我就不一一说明了,具体得可以看上面得Hash参考链接。不过折叠法还是蛮有意思得。比如key=123 456 789,我们可以存储在6 15 24,取末三位,存在524的位置。
Hash冲突: 两个元素,经过Hash算法后,得到了同一个位置,这就是冲突。所以Hash算法得涉及也是蛮重要得,涉及得好与坏,决定了你冲突得概率得高与低。既然存在Hash冲突,那也相对应存在解决方法,如:开放定址法(发生冲突,继续寻找下一块未被占用的存储地址),再散列函数法,链地址法,而HashMap即是采用了链地址法,也就是数组+链表的方式。
接下来就总结下HashMap得put原理

上面我说到了Hash函数得涉及得好与坏,决定了冲突概率,而HashMap里面得Hash设计采用了异或,移位等运算,对key的hashcode进一步进行计算以及二进制位的调整等来保证最终获取的存储位置尽量分布均匀
final int hash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
得到hash值之后,进一步确认key得下标位置
/**
* 返回数组下标
*/
static int indexFor(int h, int length) {
return h & (length-1);
}

通过以上的代码能够得知,当发生哈希冲突,并且size大于阙值的时候,需要进行数组扩容,扩容时需要新建一个长度为之前数据2倍的新的数组,然后将当前的Entry数组中的元素全部传输过去,扩容后的数组的长度是之前的2倍,所以扩容相对来说是个耗资源的操作。
下面再说下get原理
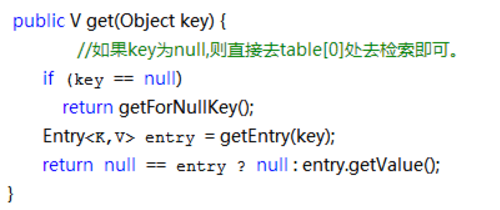
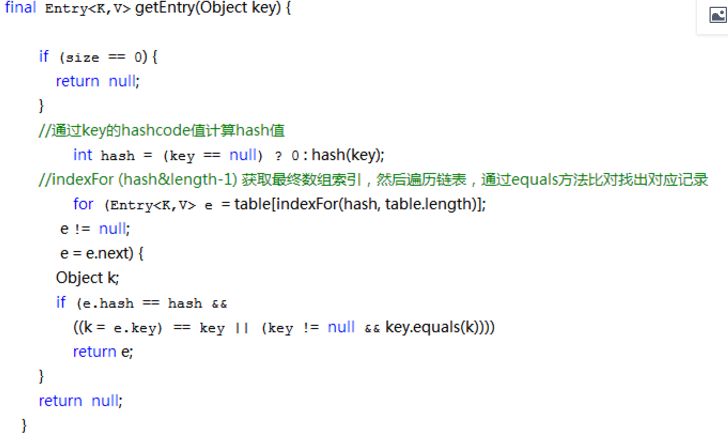
总结:(1)对于存取元素,都是会根据key得到hash值,然后结合indexFor方法,找到对应得具体下标位置。
(2)put:遍历链表,如果位置上存在相同得key,则将value替换成新得,并且返回oldValue。 get:遍历链表,寻找key,找到则返回。
jdk1.8HashMap
我就不细说了,推荐一篇解析jdk1.8HashMap原理不错得连接:https://www.cnblogs.com/xiaoxi/p/7233201.html