原文地址,转载请注明出处: http://blog.csdn.net/qq_34021712/article/details/72026313 ©王赛超
准备工作:(1个master,2个slave)
- redis-3.x安装好,具体步骤看前边的博客
- 安装出来的bin复制4份,命名bin,bin1,bin2,sentinel
- redis.conf和sentinel.conf各四份,具体如图
目录结构

master(slave同)

哨兵,三分sentinel配置文件
1.Redis主从配置
修改每一个redis的bin*目录下的redis.conf
bind 192.168.1.103 #修改为自己对应的服务器ip,实际应用中都会分配专门的ip,自己测试用可以注释掉或者改成0.0.0.0表示允许所有连接
port 6379 #依次修改为 6379 6380 6381端口
###可选项
pidfile /var/run/redis_6379.pid #依次修改为其对应的端口号,可以忽略,让其默认
daemonize yes #允许后台运行
appendonly yes #根据需求是否开启
repl-diskless-sync no #yes:主从复制采用网络传输,不传输rdb文件,默认:no
requirepass xxxx #从机和哨兵连接自身的密码,默认不需要密码 主机时有效
masterauth xxxx #从机和哨兵连接主机时的密码 从机和哨兵时有效
设置主从
修改redis.conf文件,这里将6379端口设置为master所以不需要做任何操作,只需要修改6380端口和6381端口就可以了
slaveof 127.0.0.1 6379
连接redis的master节点,查看主从状态
[root@localhost bin]# ./redis-cli -p 6379 -h 192.168.1.103 #连接redis服务
192.168.1.103:6379> INFO replication #查看当前节点的信息
# Replication
role:master #master
connected_slaves:2 #slave节点的个数
slave0:ip=192.168.1.103,port=6380,state=online,offset=1443,lag=1 #slave节点的信息
slave1:ip=192.168.1.103,port=6381,state=online,offset=1443,lag=1#slave节点的信息
master_repl_offset:1443
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:2
repl_backlog_histlen:1442
测试主备是否好用
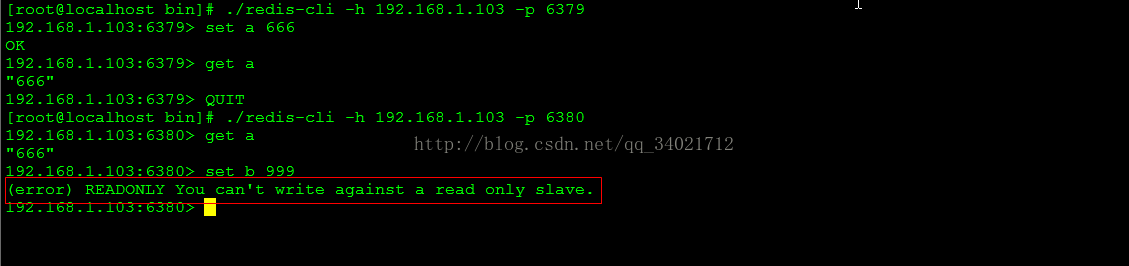
2.Redis读写分离
2.1:根据上图可以看出slave只有读的权限,不能写,如果想要slave开启写的操作需要修改redis.conf文件
slave-read-only yes #修改为yes 表示slave可写
2.2:复制的过程原理
1)、当从库和主库建立MS关系后,会向主数据库发送SYNC命令;
2)、主库接收到SYNC命令后会开始在后台保存快照(RDB持久化过程),并将期间接收到的写命令缓存起来;
3)、当快照完成后,主Redis会将快照文件和所有缓存的写命令发送给从Redis;
4)、从Redis接收到后,会载入快照文件并且执行收到的缓存的命令;
5)、之后,主Redis每当接收到写命令时就会将命令发送从Redis,从而保证数据的一致;
2.3:开启无磁盘复制
通过前面的复制过程我们了解到,主库接收到SYNC的命令时会执行RDB过程,即使在配置文件中禁用RDB持久化也会生成,那么如果主库所在的服务器磁盘IO性能较差,那么这个复制过程就会出现瓶颈,庆幸的是,Redis在2.8.18版本开始实现了无磁盘复制功能
原理:
Redis在与从数据库进行复制初始化时将不会将快照存储到磁盘,而是直接通过网络发送给从数据库,避免了IO性能差问题。
开启无磁盘复制:repl-diskless-sync yes(默认是no不开启)
3.redis的哨兵(sentinel)配置
3.1:如果redis的主从架构中出现宕机怎么办?
如果在主从复制架构中出现宕机的情况,需要分情况看:
1)、从Redis宕机
a)这个相对而言比较简单,在Redis中从库重新启动后会自动加入到主从架构中,自动完成同步数据;
b)如果从库在断开期间,主库的变化不大,从库有做持久化的前提下,再次启动后,会实现增量复制。
2、主Redis宕机
a)这个相对而言就会复杂一些,需要以下2步才能完成
i.第一步,在从数据库中执行SLAVEOF NO ONE命令,断开主从关系并且提升为主库继续服务;
ii.第二步,将主库重新启动后,执行SLAVEOF命令,将其设置为其他库的从库,这时数据就能更新回来;
这个手动完成恢复的过程其实是比较麻烦的并且容易出错,有没有好办法解决呢?当前有的,Redis提供的哨兵(sentinel)的功能。
3.2:哨兵模式原理
Redis提供了sentinel(哨兵)机制,通过sentinel模式启动redis后,自动监控master/slave的运行状态,基本原理是:心跳机制+投票裁决
每个sentinel会向其它sentinal、master、slave定时发送消息,以确认对方是否“活”着,如果发现对方在指定时间(可配置)内未回应,则暂时认为对方已挂(所谓的“主观认为宕机” Subjective Down,简称SDOWN)。
若"哨兵群"中的多数sentinel,都报告某一master没响应,系统才认为该master"彻底死亡"(即:客观上的真正down机,Objective
Down,简称ODOWN),通过一定的vote算法,从剩下的slave节点中,选一台提升为master,然后自动修改相关配置。
3.3:哨兵模式的配置
1)、去./sentinel/下配置哨兵:sentinel-1.conf,内容如下
- port 26379 #另外两个哨兵26380 26381
- dir /tmp #默认即可
- sentinel monitor master 127.0.0.1 6379 2 #监听master, 2 表示只要有两个或两个以上哨兵判定master挂了,那么就执行替换任务
- sentinel down-after-milliseconds master 30000
- sentinel parallel-syncs master 1
- sentinel failover-timeout master 180000
- logfile "/var/log/sentinel_log.log"
2)、配置文件的说明
1. port :当前Sentinel服务运行的端口
2. dir : Sentinel服务运行时使用的临时文件夹
3.sentinel monitor master 192.168.110.101 6379
2:Sentinel去监视一个名为master的主redis实例,这个主实例的IP地址为本机地址192.168.1.103,端口号为6379,而将这个主实例判断为失效至少需要1个
Sentinel进程的同意,只要同意Sentinel的数量不达标,自动failover就不会执行
4.sentinel down-after-milliseconds master
30000:指定了Sentinel认为Redis实例已经失效所需的毫秒数。当实例超过该时间没有返回PING,或者直接返回错误,那么Sentinel将这个实例标记为主观下线。只有一个
Sentinel进程将实例标记为主观下线并不一定会引起实例的自动故障迁移:只有在足够数量的Sentinel都将一个实例标记为主观下线之后,实例才会被标记为客观下线,这时自动故障迁移才会执行
5.sentinel parallel-syncs master 1:指定了在执行故障转移时,最多可以有多少个从Redis实例在同步新的主实例,在从Redis实例较多的情况下这个数字越小,同步的时间越长,完成故障转移所需的时间就越长
6.sentinel failover-timeout master 180000:如果在该时间(ms)内未能完成failover操作,则认为该failover失败
3.4启动哨兵和master、slave

3.5测试master宕机
先用客户端干掉6379:#./reids-cli -h 127.0.0.1 -p 6379 shutdown
日志打印:部分省略
1861:X 13 May 04:16:15.632 # +sdown master master 192.168.1.103 6379 #检测到master服务已经宕机
1861:X 13 May 04:16:15.632 # +try-failover master master 192.168.1.103 6379 #开始恢复故障
1861:X 13 May 04:16:15.640 # +vote-for-leader 6de45c32109f5cf472c3130c38a537188d352c12 1 #投票选举哨兵leader
1861:X 13 May 04:16:15.640 # +elected-leader master master 192.168.1.103 6379 #选中leader
1861:X 13 May 04:16:15.640 # +failover-state-select-slave master master 192.168.1.103 6379 #选中其中的一个slave当做master
1861:X 13 May 04:16:15.725 # +selected-slave slave 192.168.1.103:6380
192.168.1.103 6380 @ master 192.168.1.103 6379 #这里选中的是6380slave
1861:X 13 May 04:16:15.725 * +failover-state-send-slaveof-noone slave
192.168.1.103:6380 192.168.1.103 6380 @ master 192.168.1.103 6379
#发送slaveof no one命令
1861:X 13 May 04:16:15.788 * +failover-state-wait-promotion slave
192.168.1.103:6380 192.168.1.103 6380 @ master 192.168.1.103 6379
#等待升级master
1861:X 13 May 04:16:16.117 # +promoted-slave slave 192.168.1.103:6380
192.168.1.103 6380 @ master 192.168.1.103 6379 #升级6380为master
1861:X 13 May 04:16:16.117 # +failover-state-reconf-slaves master master 192.168.1.103 6379
1861:X 13 May 04:16:16.181 * +slave-reconf-sent slave 192.168.1.103:6381 192.168.1.103 6381 @ master 192.168.1.103 6379
1861:X 13 May 04:16:17.123 * +slave-reconf-inprog slave 192.168.1.103:6381 192.168.1.103 6381 @ master 192.168.1.103 6379
1861:X 13 May 04:16:18.182 * +slave-reconf-done slave 192.168.1.103:6381 192.168.1.103 6381 @ master 192.168.1.103 6379
1861:X 13 May 04:16:18.243 # +failover-end master master 192.168.1.103 6379 #故障恢复完成
1861:X 13 May 04:16:18.244 * +slave slave 192.168.1.103:6381 192.168.1.103 6381 @ master 192.168.1.103 6380 #添加6381为6380的从库
结果:
用客户端打开:# ./redis-cli -h 127.0.0.1 -p 6380
xxxxx> info replication
role:master
slave: 1
...
结果表示:6379已经挂了,6380上位。
恢复6379:把rdb文件从别处复制到6379,然后修改配置文件,作为6380的奴隶,最后启动