对于OkHttp的缓存策略其实就是在下一次请求的时候能节省更加的时间,从而可以更快的展示出数据,那在Okhttp如何使用缓存呢?其实很简单,如下:

配置一个Cache既可,其中接收两个参数:一个是缓存的文件,一个是缓存文件的最大大小,所以下面分析一下这个Cache类的一些细节:

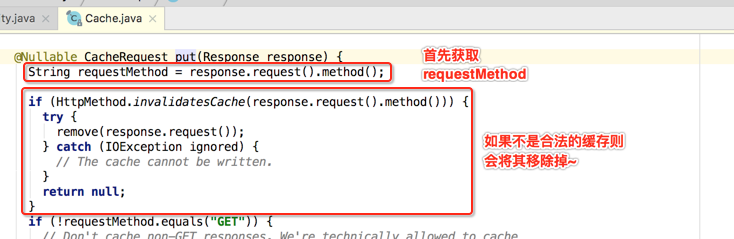
put方法【写入Response到缓存】:
纵观这个put方法,发现有一个非常引人注目的地方,如下:

另外还需要知晓一点,就是OkHttp维护了一个缓存清理的线程池,来对缓存的自动清理与管理,下面具体来分析一下该put方法的实现细节:

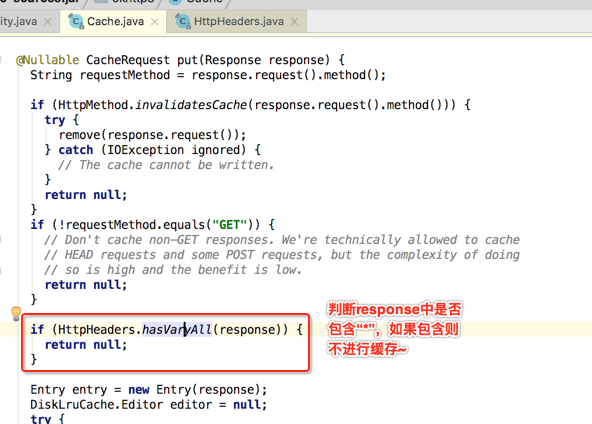
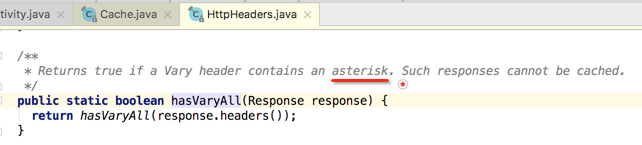
当所有过滤条件都通过之后,接下来就会生成一个Entry对象,这也是即将要被缓存的对象,如下:
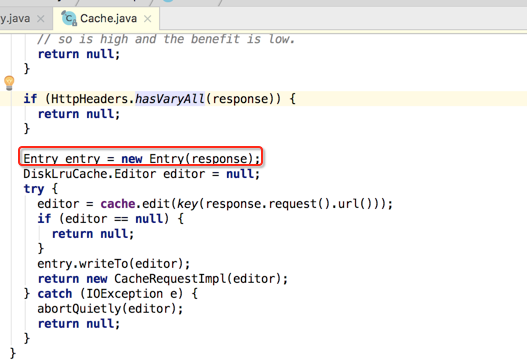
那这个Entry是个什么类呢,打开一看其实里面包含了响应的一些信息,如下:


有了要缓存的对象之后, 接下来就是将它通过LRUCache算法将其缓存,如下:
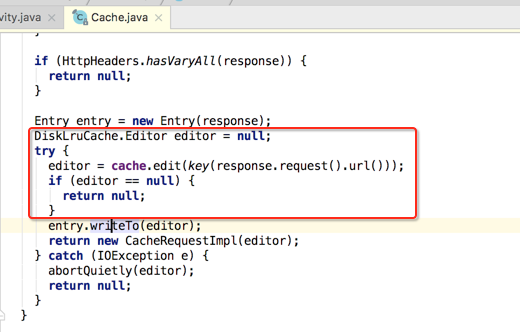
其中cache为:

另外会根据请求的url来生成key进行缓存:


接下来则开始写到磁盘上:

其写入的细节为:

这里大致了解一下,另外有一个疑问对于Response的body部份貌似看到缓存呀,看下Entry对象的成员变量:

其实在return这句上,如下:
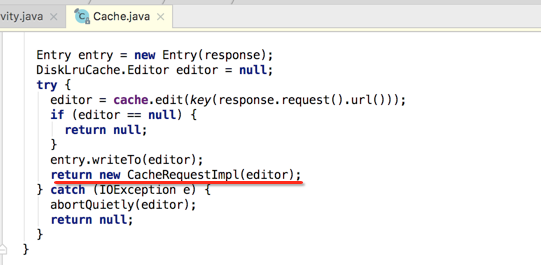
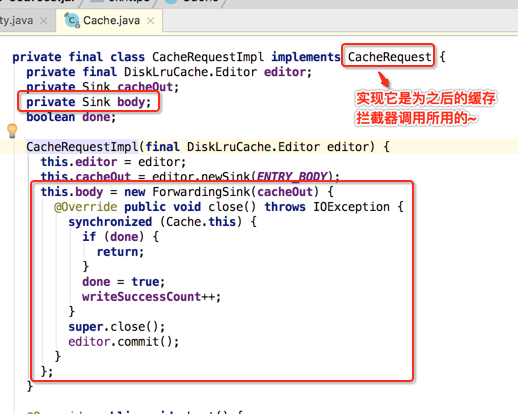
get方法【从缓存中读出Response】:

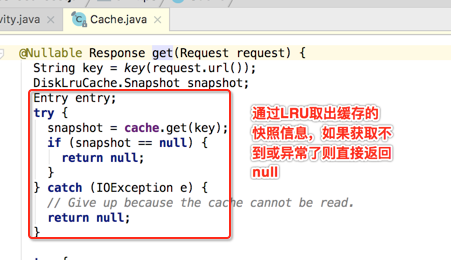

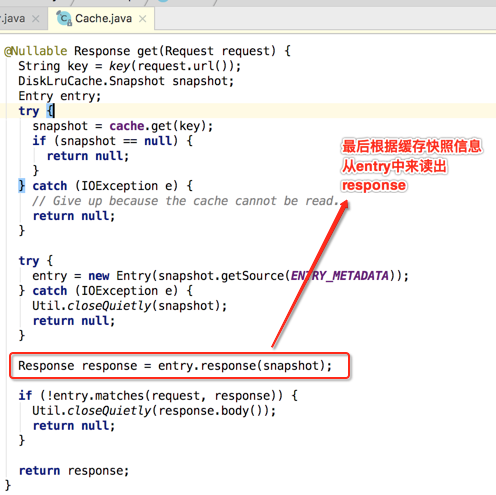
那获取Response的细节是怎么样的呢?

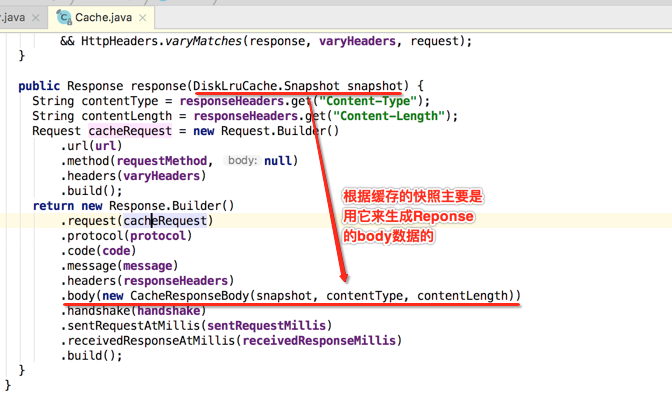
最后还有一步就会判断Request和Response的合法性,如下:


如果不能匹配则此缓存无效返回null,否则直接返回从缓存中读到的Response对象。
当了解了缓存的put和get方法的细节之后,就可以分析OkHttp的缓存拦截器了,这个下次再探究!