在上次花了几个篇幅对Collector收集器的javadoc进行了详细的解读,其涉及到的文章有:
- http://www.cnblogs.com/webor2006/p/8311074.html
- http://www.cnblogs.com/webor2006/p/8318066.html
- http://www.cnblogs.com/webor2006/p/8324390.html
而系统有一个对它的具体实现则是在Collectors类中有一个CollectorImpl:

为了加深对Collector收集器的理解,咱们这次自定义一个自己的收集器,而不采用系统写好的,在自定义之前,先来回顾一下收集器的一些要点:
1、泛型参数的意义:
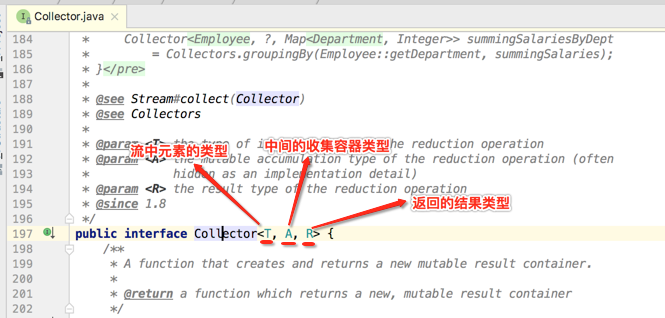
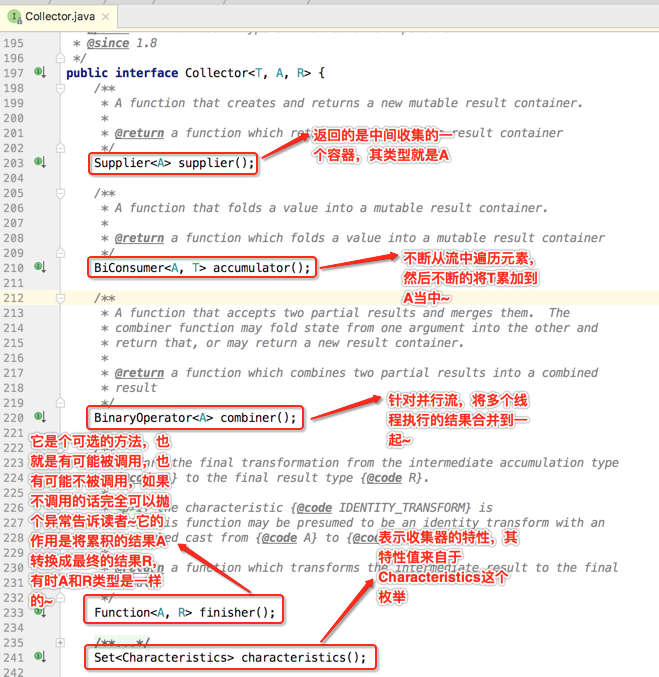
2、核心方法的意义:
其中包含五个重要的方法,具体如下:
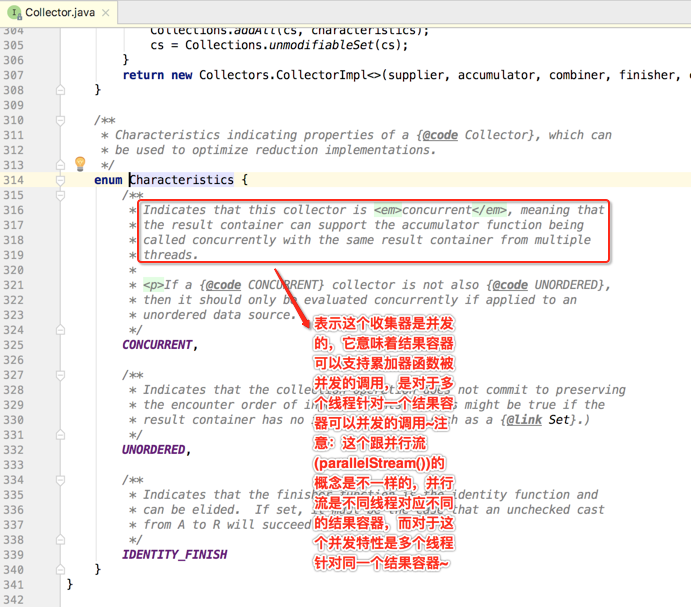
其中对于Characteristics这个枚举里面的值再说明一下,之后会用代码来进行进一步说明:



好了~~复习了这些细节之后,下面就开始编码,咱们对Set数据进行收集,如下:
接着来定义三个泛型参数,下面一个个来定义,首先是流中元素的类型,咱们用T来表示,如下:
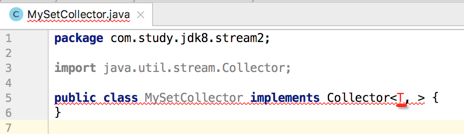
第二个参数则是中间累加的结果容器,很显然是Set<T>,如下:

最后一个参数则是最终结果的类型,咱们最终结果类型跟中间结果容器类型是一样的,都是Set,所以:
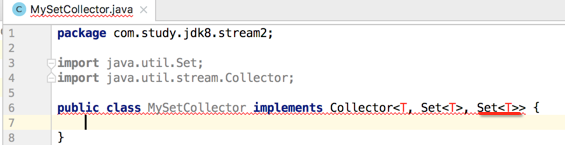
很显然目前的T还是标红的,是因为咱们还得在它上面定义一下,如下:
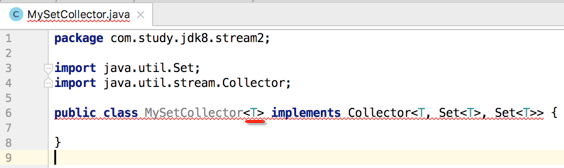
接下来将接口中的方法都得实现一下,如下:


接下来一个个方法具体实现:
supplier():
首先先在这方法中打印一下日志,待之后看一下整个调用过程:
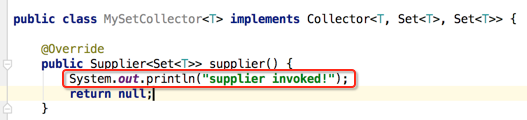
那接下来就是看如何实现呢?它的作用是生成一个存放中间结果的空的容器,看下它的返回值是:Supplier<Set<T>>,不传参数,返回一个Set<T>,这里咱们用HashSet,那可以采用方法引用,如下:

accumulator():
还是先打印日志便于运行观察:

该方法的主要作用是进行中间结果的不断累加,看一下它的返回类型BiConsumer<Set<T>, T>,接收两个参数,不返回值,注意一下这两个参数的顺序:第一个参数为不断增加的结果容器,第二个参数流中遍历的下一个元素,当然就是不断将第二个参数往第一个参数中累加,所以下面先用Lambda表达式的方式来实现一下:
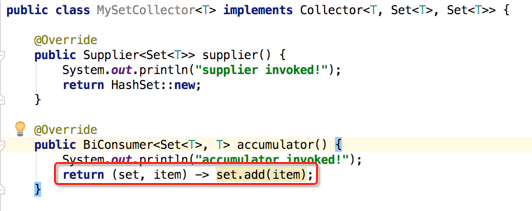
这时还是可以用方法引用:
对于这个方法引用,其第一个参数是调用累加的那个中间结果容器,而第二个参数则是遍历的下一个元素。
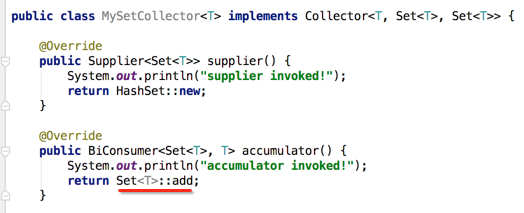
那如果将这个Set换成HashSet呢?
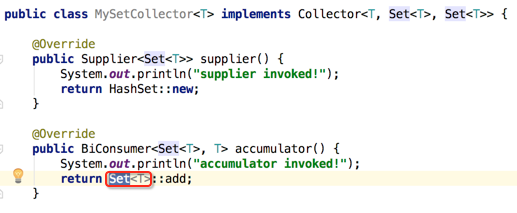

咱们先看替换完之后能不能编译:
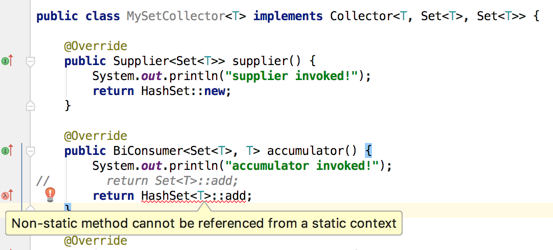
IDE提示貌似也没道出所有然来,很是奇怪,既然HashSet是Set的直接实现类,为啥就不行了呢?其实原因是这样:
假如这个HashSet替换完了是允许的,那假如咱们在supplier()函数中将HashSet改为TreeSet呢?那明显accumulator()方法的具体实现也得进行修改,而如果是面向接口那改了supplier()的具体实现完全不影响accumulator()的实现,所以说这个实现需要注意。
combiner():
同样先打印日志:

而此方法的作用就是将两个部分结果进行合并,所以可以这样实现:

finisher():
首先也打印日志:
它的作用其实就是将中间累加的结果容器转换成最终的结果,而对于咱们这边的场景其最终结果类型也就是中间结果类型,所以直接将累加的中间结果容器返回既可,如下:

插个小细节,还可以用Function提供的一个静态方式来取而代之,之前咱们也介绍过:
所以:
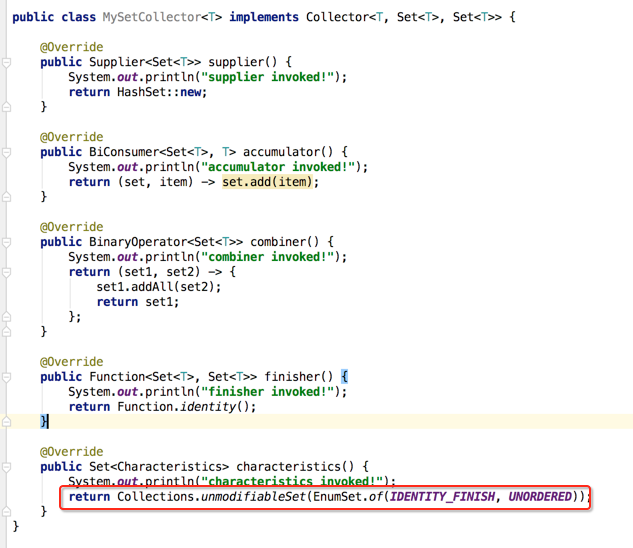
characteristics():
同样先增加日志:

它主要是决定收集器的一些特性的,那这里返回一个无序特性,如下:
那这里面实现中涉及到的代码其实是参照Collectors类中的,如下:

至此,咱们自定义的收集器就已经定义好啦,接下来咱们来使用一下它,将定义的List转换成Set,具体如下:

看一下此时它返回的数据类型:
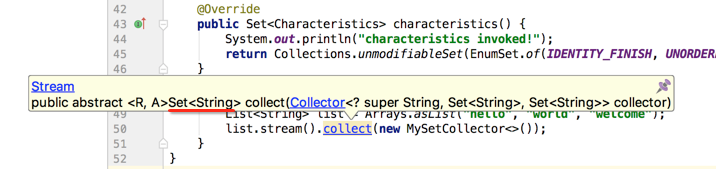
所以咱们用它来接收一下,并打印出结果:
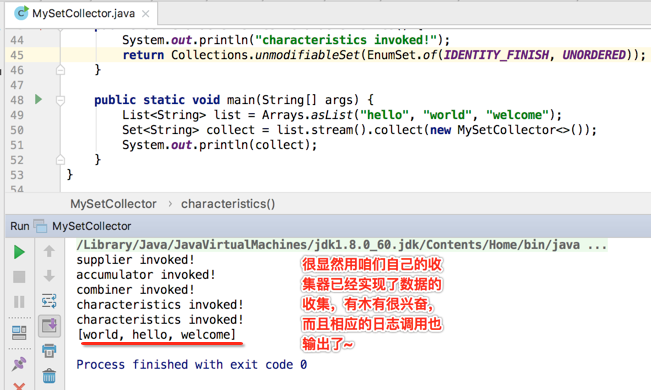
如果再增加一个重复的元素当然会被过滤掉,因为Set是会去重滴:

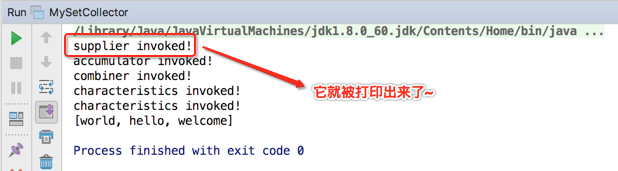
从日志打印的记录中发现,居然finisher()方法木要有被调用,这也是在开篇回顾Collector重要方法时提到了,它有时能调用,有时是不会调用的,当中间的结果容器的类型跟最终结果的类型是一致的话,其实该方法直接抛个异常就行了,不用实现,而咱们写的这种情况刚好就属于这种:

关于最终打印的日志输出,它的执行流程为啥是这样的呢?下面从stream.collect()的源码中找寻答案,如下:
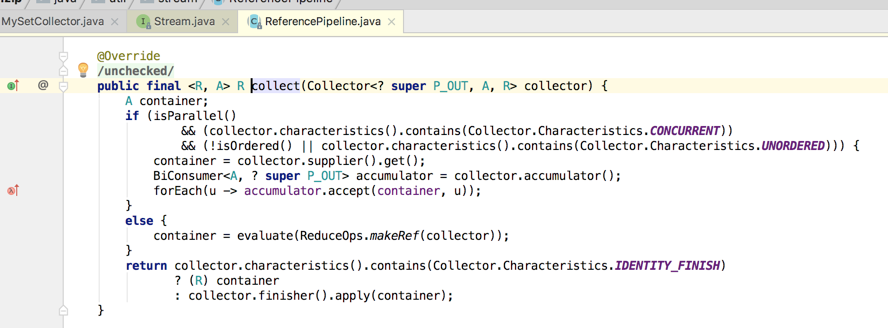
接下来只分析关键代码,因为主要是为了寻找为啥最终的输出顺序是这样的问题,先来看一下该方法的实现:
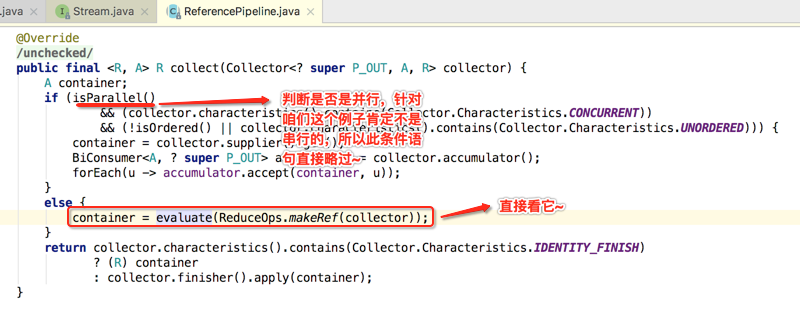
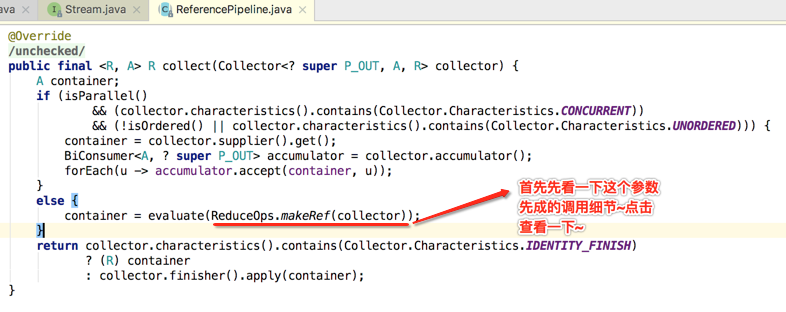
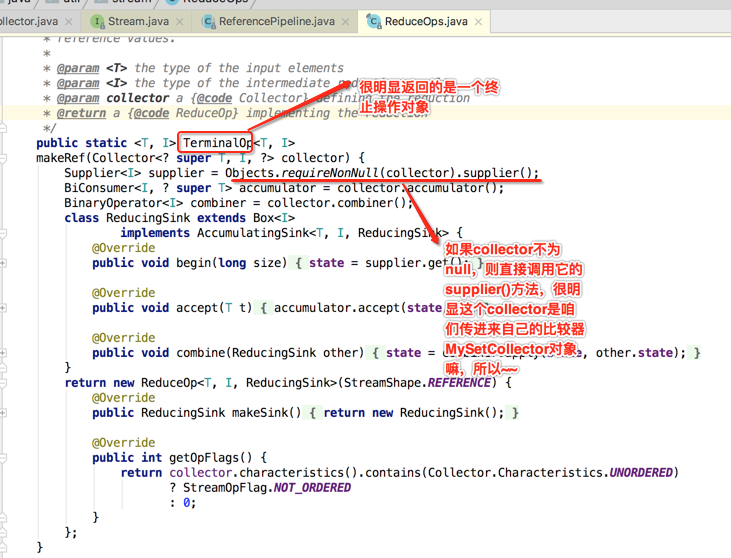

接着继续回到ReduceOps.makeRef()方法往下看:

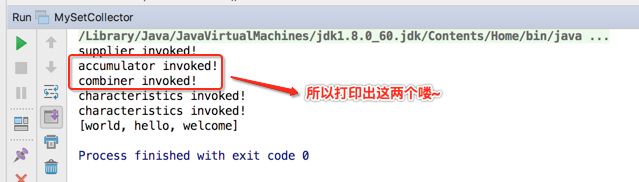
所以这三句话的调用就是在初始化时被调用的,但是!!!有一点需要注意,只是回调函数调用了,但是函数式接口并没有调用,如何理解,比如说:
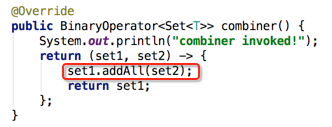
如果BinaryOperator函数式接口被调用的话,其Lambda表达式肯定会被执行,最终执行合并操作,这里说的函数式接口没调用是指并非真正的去执行了合并操作了,其实目前只是获取了函数式接口的实例而已,咱们再来体会下:

接着再来分析一下为啥这个被打印了两次,如下:
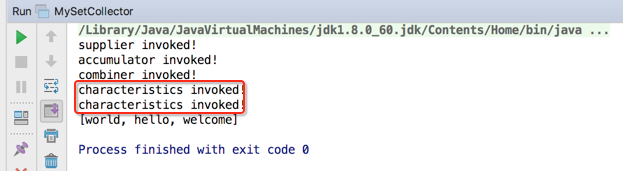
其实是在下面两处被调用的:
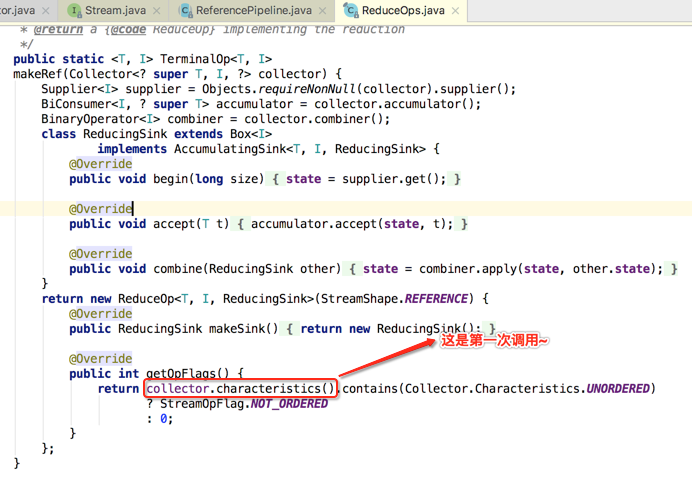
接着得回到它的上一级调用来看:
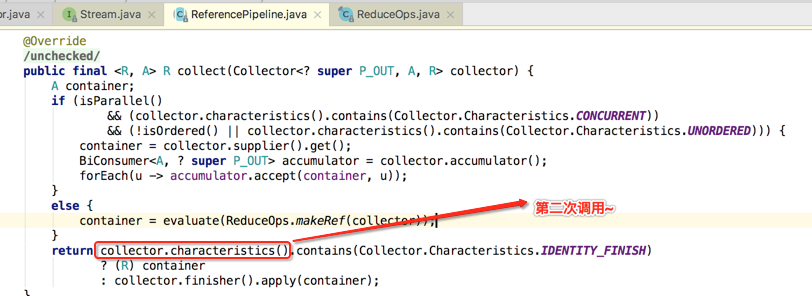
另外为啥finisher()方法木有被调用呢?其实也就是在刚才分析的代码处就可以明白了:
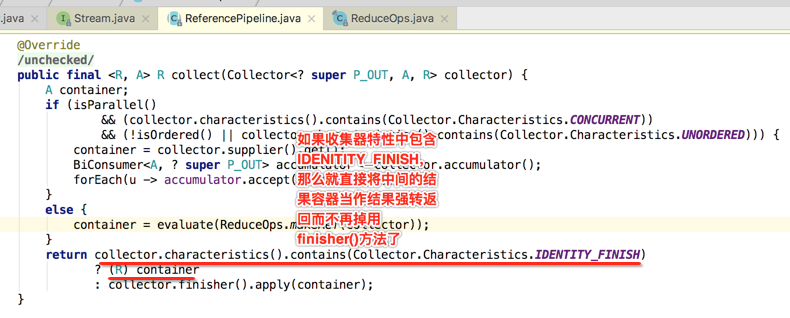

所以通过这个实现就能解释为啥咱们的finisher()方法木有掉用啦,原因就是由于咱们给收集器增加了如下特性:
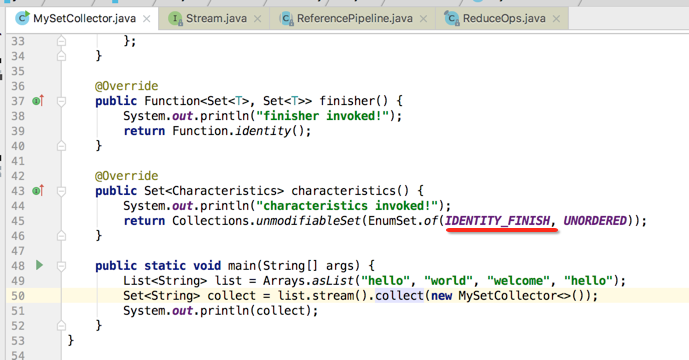
那接下来做个实验,将这个特性去掉,看是否这次能执行finisher()?

基于此咱们再来看一下系统收集器实现中的一个细节:
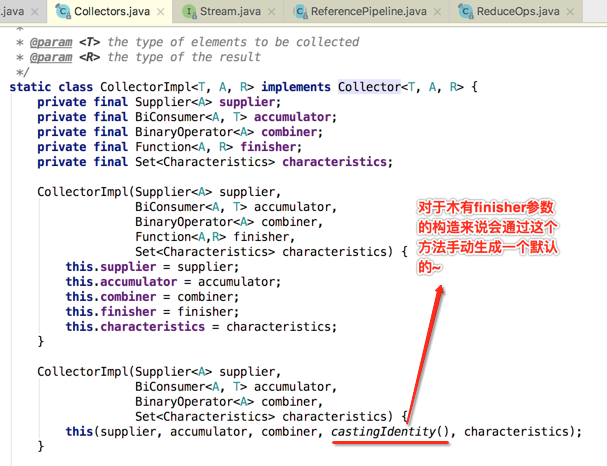
看一下它的具体实现,豁然开朗:
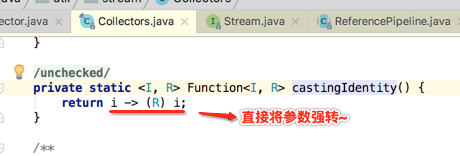
实际开发中可能自定义收集器的场景比较少,但是!!如果你研究清楚了如何自己来写一个收集器,那可以帮助我们更加自信的应用收集器的任何东东,也就是有了底层的支持才能走出咱们的自信,所以学会自定义还是非常有意义的~