关于NDK这个分类在N年前就已经创建了,但是一直木有系统的记录其学习过程,当然也没真正学会NDK的技术真谛,所以一直也是自己的一个遗憾,而如今对于Android程序员的要求也是越来越高,对于NDK也是应对高级职称时被很多公司所看中的,如今像热修复之类的也或多或少会用到一个NDK的东东,所以今天起下决定要来弥补这一门空缺的技术,而且是从浅到深一点点来记录,等坚持到彻底掌握之后再回过头来我想这些点滴也是一笔非常非常宝贵的财富,一定要坚持!!!!
为了学得更加扎实,语言关C、C++必须得过,说实话前几年也认真学习过它们,但是!太久时间木有用过了,也遗忘得差不多了,所以先来一个语言的整体的复习,虽说枯燥,但是这也是为NDK更加深入的学习打下良好的基石,下面开始:
基本数据类型:
这里采用的开发工具为CLion,比较轻巧又好用,而且因为它是Jet Brains出品的,而Android Studio也是它出品,所以对于里面的操作可以说是无缝连接,话不多说直接新建一个C工程:

环境一切正常,接下来看一下C语言中的基本数据类型,对于它分为两种:
1、signed 有符号的类型,也就是支持正负号的。
2、unsigned 无符号的类型,也就是没有负号,取值从0开始。

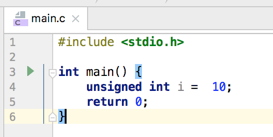
对于上面声明的这个整形变量默认就是有符号的,如果想声明成无符号的则在int前面加unsigned关键字既可:
那思考一下:有符号和无符号的数据类型有啥区别呢?其实就是取值范围不一样,下面看一张对照表:
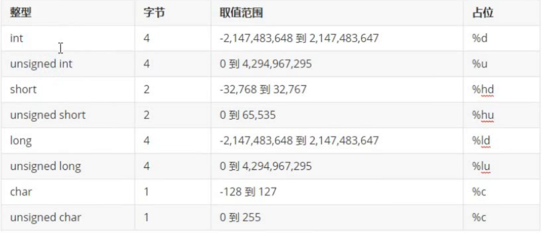
基本跟java基本数据类型差不多,C中的基本整形数据类型为:int 、short、long、char。其中发现上面int 和 long在C中占的字节数是一样的,都是占4个字节,这个有别于java,在java中long是占8个字节嘛,下面可以用sizeof()来打印一下其类型的长度:
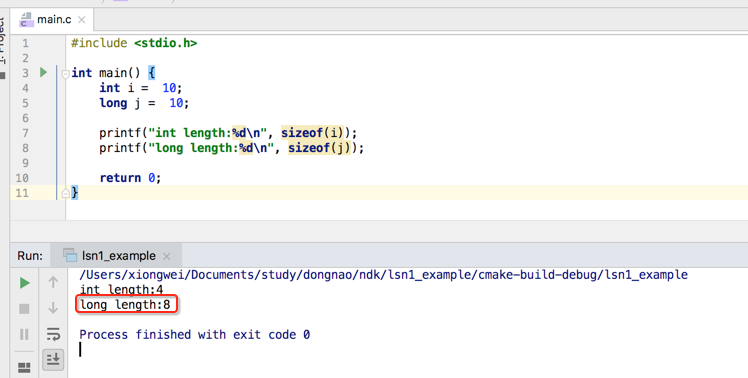
呃,那图中的说得不对呀,对于这个其实是随编译器而异的,下面来总结一下不同编译器下的基本数据类型所占的字节数:
16位编译器
char :1个字节
char*(即指针变量): 2个字节
short int : 2个字节
int: 2个字节
unsigned int : 2个字节
float: 4个字节
double: 8个字节
long: 4个字节
long long: 8个字节
unsigned long: 4个字节
32位编译器
char :1个字节
char*(即指针变量): 4个字节(32位的寻址空间是2^32, 即32个bit,也就是4个字节。同理64位编译器)
short int : 2个字节
int: 4个字节
unsigned int : 4个字节
float: 4个字节
double: 8个字节
long: 4个字节
long long: 8个字节
unsigned long: 4个字节
64位编译器
char :1个字节
char*(即指针变量): 8个字节
short int : 2个字节
int: 4个字节
unsigned int : 4个字节
float: 4个字节
double: 8个字节
long: 8个字节
long long: 8个字节
unsigned long: 8个字节
另外对于数据类型还有类似的这种写法:

其实long int = long;在标准中规定int至少要和short一样长,long至少要和int一样长。
在实际中可能会用一个更加清晰的数据类型,如:

其实用的就是定义好的宏,具体来看一下它的定义就明白了:

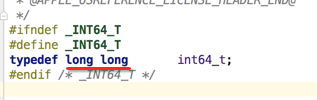
这种写法是被推荐的,因为会比较清晰。
基数数据类型除了上面的整型之外,还有浮点型,具体如下表:

另外需要注意:在C中并没有专门的boolean类型,而是:非0既true、非null为true;

输出格式化:
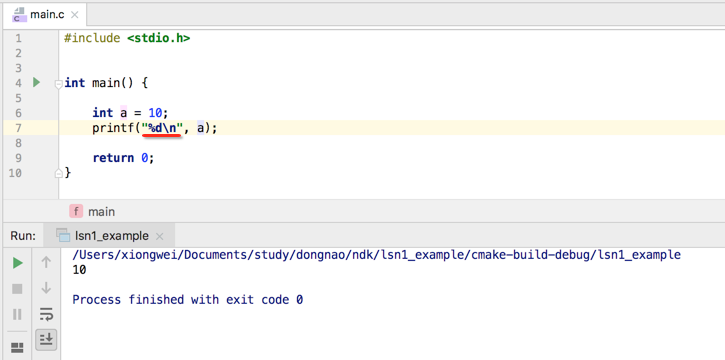
对于C的输出函数print()函数是不能直接来打印变量的,如下:

必须要写一个格式化占位符参数,其实跟java中的String.format()的用法类似,如:
而其中的“%d”表示输出整型变量,那对于其它数据类型其输出占位符又如何写呢,其它之前的表格中已经有说明,如下:


虽说"%d"可以输出所有的整型,但是还是用上图中对应的输出会更加精准。
另外sprintf()这个函数在实际当中也非常常用,比如要打印某个目录下的按规律生成的文件,比如:
这时就可以采用该函数了,下面模拟一下:
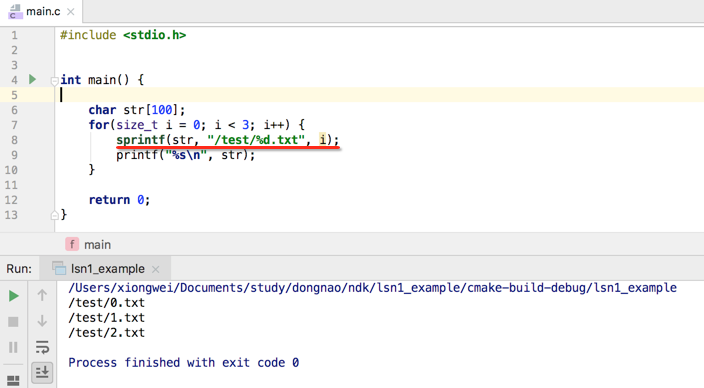
也就是將2、3参数格式化的字符复制到str当中。
数组与内存布局:
在C中声明数组必须指定长度,或者声明与赋值写在一起,如下:
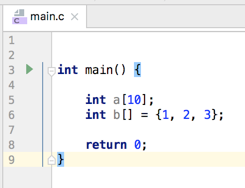
另外它是在栈上分配内存的,而栈上的内存是有限制的,在mac上可以使用“ulimit -a”来查看其最大栈内存:
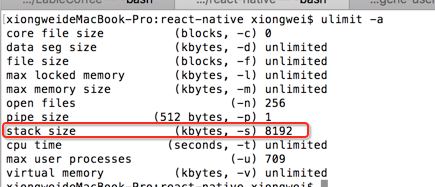
也可以直接用“ulimit -s”来只看栈大小:

也就是最大栈的大小是8192K,但是需要注意:并不是我们程序也能申请这么大的栈内存的,因为像程序的一个函数参数,返回值等也是存放在栈中的。另外栈内存出了作用域就会自动释放掉,所以不需要手动去回收的。
前面说了栈大小不是特别大,那如果对于要的内存超过栈大小的该怎么办呢,当然就是在堆中进行申请喽,此时就存在以下几种堆中申请内存的一些函数,下面来说明下:
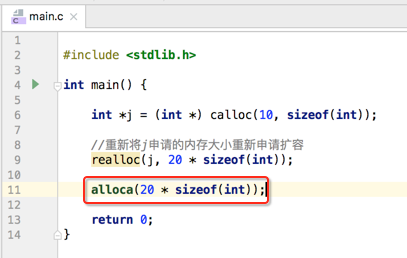
- malloc:在堆中申请内存但不会对其申请的内存进行初始化,如在堆中申请1MB的内存:
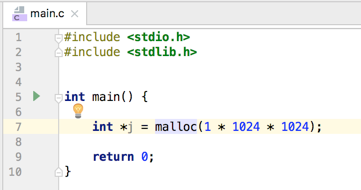
另外还需要注意:由于申请的内存还没初始化,所以一般在malloc申请内存之后会使用memset保存其申请的内存是一片纯白的,而不是用了之前的脏数据,因为申请内存有可能会重用之前的内存,具体用法如下:
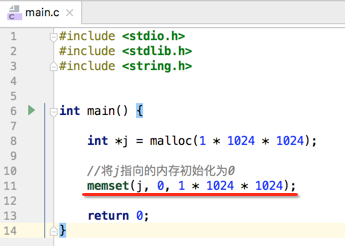
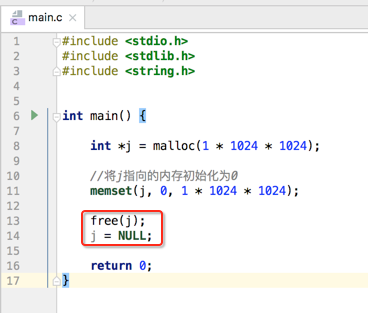
还有一点需要注意:堆中申请的内存是不会自动释放的,需要手动去释放,如下:
- calloc():申请内存并将内存初始化为null,具体用法:
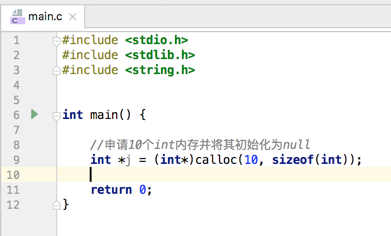
其实它就等价于:
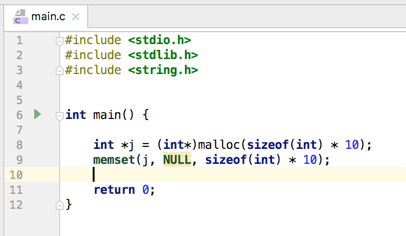
-
realloc():重新对malloc申请的内存大小进行调整,如下:

那什么场景会用到它呢,这里举一个TCP传输粘包问题,比如发送“1,2,3,4,5,6”数据,而接收的时候可能分几次才能接收完,比如是先接收到了“1,2,3”,之后再接收到了“4,5”,最后接收了“6”,至此才将数据接收完,那此时的缓冲区char首先申请的是3个字节,于是乎“1、2、3”刚好接收满了,但此时还不是一个完整的数据包,所以还得接着等“4,5,6”,当接收到了“4、5”了,就需要对缓冲区进行扩容用以存放这两个字节了,同样的最后接收到了"6",则继续再要对缓存冲再扩容一个字节。 当然直接申请一个足够大的缓存区不就不用扩容了么,这是因为数据包的大小是无法确定的,这里只是为了说明问题举了个简单的粟子而已。
- alloca():向栈中申请内存,了解一下既可,用得比较少。用法如下: