自定义协程作用域:
在之前我们接触到了协程作用域,那如何自定义一下这个协程作用域呢?这里先看一下这块的理论说明:
"除去不同的协程构建器所提供的协程作用域(coroutine scope)外,我们还可以通过coroutineScope builder来声明自己的协程作用域。该构造器会创建一个协程作用域,并且会等待所有启动的子协程全部完成后自身才会完成。runBlocking与coroutineScope之间的主要差别在于,coroutineScope在等待所有子协程完成其任务时并不会阻塞当前的线程,而runBlocking会阻塞当前线程。"
那咱们来用程序实践一下:

然后接下来咱们来自定义一下协程作用域:

那结果是啥呢?下面运行一下:

下面来分析一下整个打印的逻辑:








其中可以简单看一下coroutineScope()函数的定义:

轻量级协程与线程执行比对分析:
对于协程的效果跟线程其实差不多,但是它们俩其实还是存在本质的区别的,总的来说协程是轻量级的,而线程是重量级的。所以下面来做下实验来看一下它们两者的区别:
先来看下协程的效果,这里创建N个协程然后输出个字母,当然我们可以用for循环来创建多个,这里采用Kotlin的方式来实现一下:

可以使用它,先来看一下它的定义:

看一下它的大致实现就秒懂了:

好,下面来写一下:

运行一下:

比较容易,接下来咱们换成线程来实现同样的效果,如下:

接下来运行一下:

嗯,貌似协程跟线程在目前的这个程序上看不出啥区别,好,接下来区别就来了,我们将创建个数从100改为5000,各自执行一下,先来执行协程:


嗯,木问题,接下来再来看线程:

运行:

区别就出来啦!!!由于协程是用户态,没有个数的上限,而线程是内核态的,它需要依赖于系统,是有上限的,另外由于线程有切换的开销,所以在有些情况会能看到线程的执行速度要比协程要慢,当然在我电脑上木有看出来,验证出来的结论就是协程是轻量级的,而线程是重要级的。
接下来得看一下repeat()函数的一个细节,这个细节可能比较难理解,但是理解了之后能够让我们更加正确的用Kotlin的思维去编写代码,先来看一下它的参数定义:

那这个难理解的东东就来啦,看一下我们是怎么来调用的:

为了好理解,将其写得明显一些:
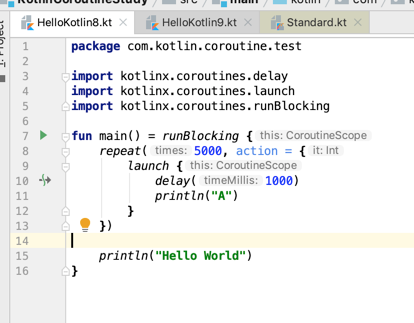
那不很顺其自然么?但是!!!细看一下,很明显我们的lauch函数木有接收参数了呀,我们没有给它传递任何的参数嘛,而我们看到的repeat()的第二个参数的Lambda表达式是要求要能接收一个参数呢,那怎么我们就能传lauch()函数给repeat()的第二个参数呢?是不是确实比较难理解?所以接下来把这个细节搞定了,细节决定成败!!
接下来咱们在lauch体中来加一句代码可能就立马能让这个不太可理解的东东成为可理解:

运行时:
说明咱们的repeat()中的索引确实是传递给了咱们的launch函数了嘛,也就符合了repeat的第二个参数的要求了,这个细节非常之隐晦的,也就是这个参数我们从写代码上是不用去显示的来写的,这也是Koltin的Lambda表达式的一个灵活之处,跟Java的Lambda是不可能做到这点的。
既然话题已经转到这个了,下面再写一个示例来对这个参数问题在Kotlin的Lambda表达式的写法做一个专门剖析,以便之后再遇到这种问题就可以彻底清楚了,如下:

接下来调用一下,看一下kotlin的神奇之处:

好,接下来再来调用第二个函数:
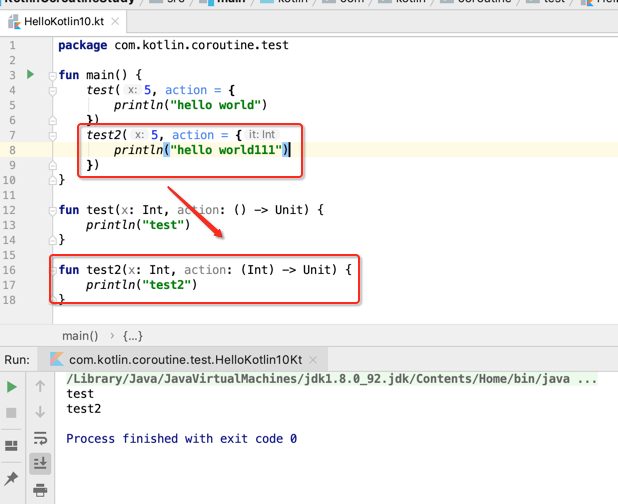
有木有发现大路:

这也是Kotlin跟Java不一样的地方,也就是如果只有一个参数时在写Lambda表达式是可以省略的,接下来我们来把这个隐含的参数打出来:

这个细节非常之小,可能不一定每个人都能去研究它,但是研究透了之后其实也就是让我们更好的能使用Kotlin的一个基石。