如果理解的有问题,欢迎大家指正。
https://www.cnblogs.com/webglcn/p/10587708.html
jdk7的hashmap 由数组和链表组成,存在几个问题:
当key的hash碰撞频率高,导致链表内的数据过多,影响查询效率, 时间复杂度为O(n)
不同的key经过hash运算,结果落到同一个table的元素中,元素内部是链表结构,新增的数据会直接插入到链表的结尾。当查询的时候,首先通过hash找到元素在hashmap中的table位置,然后遍历链表找到元素,遍历的时间复杂度为O(n).
多线程并发操作hashmap,导致链表查询死循环。
并发扩容时,同时执行transfer方法,如果原始链表相邻的两个元素,扩容后仍是相邻的两个元素,由于采用了头插入,会造成两个元素形成互为首尾,形成死循环。举例如下。
初始状态hashmap 的初始大小为 2^n (n=1), hashmap的size是2, 插入两个元素3和7
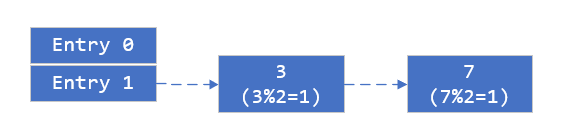
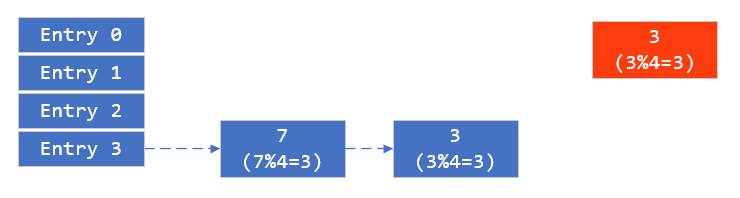
两个线程对hashmap进行扩容(调用transfer), 假设线程一执行到获取第一个元素3,CPU调度到第二个线程, 第二个线程完成了全部的扩容操作,由于扩容采用了头插法,元素7插入到元素3之前,并作为链表的第一个元素。此时状态为
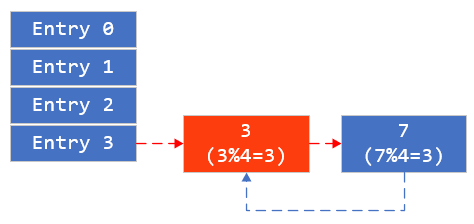
线程一采用头插法,形成死循环
参考文献
http://www.cnblogs.com/dongguacai/p/5599100.html