(注意本部分的概述是为了后边更容易学习理解 但这个并不是关键)
计算机的主要功能是数据运算
目的:合理组织数据、高效率地实施数据运算
数据是信息的载体、数据的基本单位是数据元素
数据对象是具有相同类型的数据元素的集合
一个数据元素可以分成很多歌数据项(可称为元素节点或者属性等)
例如在一个学生表单中:一条记录为数据元素 而该学生的姓名就是数据项
数据结构是相互之间存在一种或者多种关系的数据源的集合
数据逻辑结构: 数据元素之间的逻辑关系
数据存储结构:数据元素及逻辑关系在计算机存储器内的表示
数据运算:
- 定义是基于逻辑结构(运算的功能) 常见运算 :检索 插入 删除 更新 排序等
- 实现是基于存储结构
例子:
一个学生表
逻辑结果(元素之间的逻辑关系):
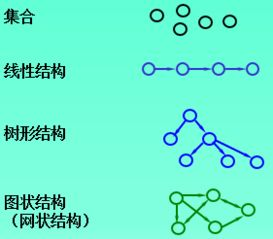
集合(关系松散)
线性结构:一对一关系
树形结构:一对多
图形结构:多对多 也称为网状结构
逻辑结构可以用多种方式描述这里二元组描述最常见:
S=(D,R)
D={d|1<i<n}
R={r|1<j<m}
D 是元素集合 R为D->D之间的关系集合
<a,b> 有向关系 a为b的前驱元素b为a的后继元素 没有后继元素的元素为终端元素 反过来则为开始元素 处于中间的为内部元素
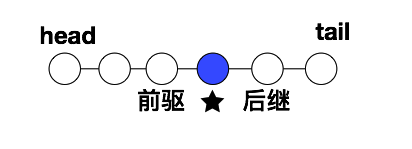
也可使用逻辑结构图表示逻辑关系(可以看出下面的逻辑结构图表示的是一个树形结构 一个元素(树节点)有多个后继元素(分支或者树叶))

存储结构:(存储表示、物理结构)
数据逻辑在计算机存储器当中的表示
一个数据逻辑可以使用多种存储结构:可根据问题规模和运算种类等因素适当选择
简要阐述:
顺序结构
物理存储上一级数据逻辑上均相邻的元素(将数据的逻辑结构直接映射到存储结构)
特点:节省存储空间 逻辑关系没有占用任何额外的空间
可实现元素的随机存储:时间复杂度:O(1)
缺点:不便于修改 删除 插入 (需要移动一系列元素)
链式存储:
无需占用一整片空间 但每个节点需要额外的空间保存前后驱节点元素的地址 逻辑相邻 但 存储结构不相邻
有点:便于修改 插入 删除 仅仅改结点的指针域即可
缺点:不可随机存取 需要额外的空间存储逻辑关系 (空间利用低)
索引存储:
索引表用于存储关键字和对应地址:通过二分查找索引表找到关键字,然后通过对应地址在数据表中找到该记录的数据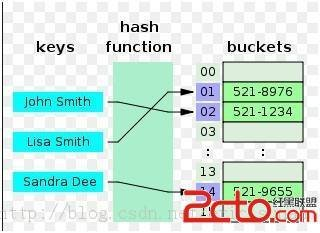
优点:查找效率高
缺点:需要建立索引表 增加时间空间开销
哈希(散列)存储结构:
通过哈希函数用关键字求得存储地址:
优点:查找速度快
适用于对数据能够进行快速查找插入的场合 采用该方法的关键是选择好的哈希函数 和处理冲突的方法
数据运算:包括运算的功能 和在存储结构上运算的实现 选择好的存储结构可以提高运算的效率
下面看一个例子:
#include<iostream> #include<stdio.h> #include<string.h> using namespace std; int main(){ const char *str; str="helloworld"; char pstr[]="thank you!"; char *p = pstr; int len = strlen(pstr); cout<<endl; for(int i=0;i<len;i++){ cout<<*(p+i)<<" "; } cout<<endl; int l = strlen(str); for(int i=0;i<l;i++){ cout<<*(str+i)<<" "; } cout<<endl; cout<<"直接输出"<<endl; cout<<p<<endl; cout<<str; return 0; }
可能遇到的问题:
warning:deprecated conversion from string constant to 'char *'[-Wwrite-strings]
char *背后的含义是:给我个字符串,我要修改它。 而理论上,我们传给函数的字面常量是没法被修改的。 所以说,比较合理的办法是把参数类型修改为const char *。 这个类型说背后的含义是:给我个字符串,我只要读取它。
字符数组和字符串区别
这一切看起来和字符数组是多么地相似,它们都可以使用%s输出整个字符串,都可以使用*或[ ]获取单个字符,这两种表示字符串的方式是不是就没有区别了呢? 有!它们最根本的区别是在内存中的存储区域不一样,字符数组存储在全局数据区或栈区,第二种形式的字符串存储在常量区。全局数据区和栈区的字符串(也包括其他数据)有读取和写入的权限,而常量区的字符串(也包括其他数据)只有读取权限,没有写入权限。
#include<iostream> #include<stdio.h> #include<iostream> #include<stdlib.h> #include<malloc.h> #include<cstring> using namespace std; int main(){ int a=12; char *p; p =(char*)&a; //p=&a; *p='a'; //cout<<p<<""<<endl; //cout<<&a; cout<<(char*)(&a)<<endl; cout<<&a<<endl; cout<<*(&a)<<endl; *(&a)=98; cout<<*p; char s[]={'1','2','1','2'}; char *p1=s; cout<<p1; //malloc分配内存空间返回内存地址 先转换成字符型指针 用来标明该地址保存的内容时字符型 读取时以字符型读取 char *pp = (char *)malloc(10*sizeof(char)); cout<<pp<<endl;
//pp指向是字符的首地址 在读取或者插入时指导找到结束字符�才会停止所以可以直接使用该指针赋值 strcpy(pp,"asdasd"); cout<<"=========="<<endl; cout<<pp; cout<<*pp;
//销毁内存 用malloc函数分配的空间是不能被系统自动释放的,必须显式用free释放 这个称谓销毁 p所分配的内存在程序结束后仍然被占用 可能导致内存泄漏 free(pp); return 0; }
前内容回顾--结构体:
#include<iostream> using namespace std; struct teacher{ int a; const char *name; }; union tag{ int age; }; int main(){
//t变量所分配的内存大小为所有成员占用的内存空间之和 teacher t; union tag n; t.a=1; t.name="sdfsdf"; cout<<t.a; cout<<*(t.name); return 0; }
算法是指令的有限序列
算法设计应该满足以下:
正确性、可使用性、可读性、健壮性、高效与低存储量需求
#include<iostream> using namespace std; int func(int &rst,int *arr,int size){ if(!size){ return 0; } for(int i=0;i<size;i++){ #include<iostream> using namespace std; int func(int &rst,int *arr,int size){ if(!size){ return 0; } for(int i=0;i<size;i++){ rst+=*(arr+i); } return 1; } int main(){ int arr[]={1,2,1,23,1}; int rst = 0; if(func(rst,arr,5)){ cout<<rst; }else{ cout<<"情书"; } return 0; }
算法分析:计算机资源主要包括计算时间和内存空间 也就是算法的时间和空间复杂度
通常有两种衡量算法效率的方法:事后统计法、事前分析估算法 提倡使用事前分析估算效率(事后缺点:必须执行,存在其他因素掩盖算法本质)
影响算法执行时间:本身机器、使用的编程语言、代码本身问题
主要影响:问题规模
一个算法由:控制、分支、顺序、循环组成
一个语句的执行次数称为频率 一个算法的所有语句的频率之和T(n)与算法的执行时间成正比 可以将T(n)看出执行时间当问题规模趋向于无穷大时,T(n)的数量级称为时间复杂度,简称为时间复杂度,记为:T(n) = O(f(n))
如何统计一个程序执行时间:
#include<iostream> #include<time.h> using namespace std; int func(int &rst,int *arr,int size){ if(!size){ return 0; } for(int i=0;i<size;i++){ rst+=*(arr+i); } return 1; } int main(){ double time_Start = (double)clock(); //放置测试代码 double time_Finish = (double)clock(); //结束时间 cout<<(time_Finish-time_Start)/CLOCKS_PER_SEC<<"秒钟"; return 0; }

例题:
T(n) = 5n^3+3n-100 T(n)=O(n^3) 因为c=lim|T(n)|/|n^3|=5; T(n)=O(n^3) 因为c=lim|T(n)|/|n^4|=5/n当n趋向于无穷大时 c也趋向于0
通常时间复杂度如下:
O(1)<O(log^(1/2))<O(n)<O(nlog^(1/2))<<O(n^2)<O(n^3)<O(2^n)//这个得懂点数学相关了
若T1 和 T2为程序段p1 和p2 的执行时间则先执行p1再执行p2
时间复杂度:T1+T2 = O(MAX(f(n),g(n)))
乘法规则:T1*T2 = O(f(n)*g(n))
每个简单语句:赋值语句、输入输出语句、他们的执行时间和问题规模无关,对应执行时间复杂度为O(1)
for(int i=0;i<n;i++)//执行n+1 for(int j=0;j<n;j++){//执行n*(n+1) c[i][j]=0;//执行n*n for(int k=0;k<n;k++){//执行n*n*(n+1) c[i][j]=c[i][j]+a[i][k]*b[k][j];//执行n*n*n } } T(n)=2n^3+3*n^2+2*n+1=O(n^3)
空间复杂度是对一个是算法在运行过程中临时占用的存储空间大小的量度