XML 文档对象模型定义访问和操作XML文档的标准方法。
DOM 将 XML 文档作为一个树形结构,而树叶被定义为节点。
XML DOM 把 XML 文档视为一种树结构。这种树结构被称为节点树。
可通过这棵树访问所有节点。可以修改或删除它们的内容,也可以创建新的元素。
XML DOM 定义了访问和处理 XML 文档的标准方法。
XML DOM 是 XML Document Object Model 的缩写,即 XML 文档对象模型。
xml每个成分都是节点、
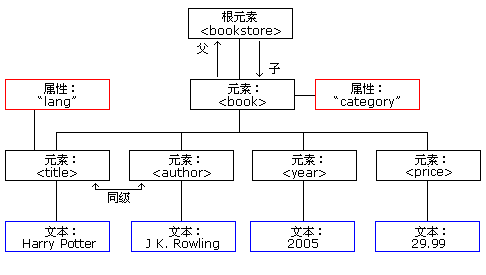
根据 DOM,XML 文档中的每个成分都是一个节点。
DOM 是这样规定的:
- 整个文档是一个文档节点
- 每个 XML 标签是一个元素节点
- 包含在 XML 元素中的文本是文本节点
- 每一个 XML 属性是一个属性节点
- 注释属于注释节点
看一个例子
<?xml version="1.0" encoding="ISO-8859-1"?> <bookstore> <book category="children"> <title lang="en">Harry Potter</title> <author>J K. Rowling</author> <year>2005</year> <price>29.99</price> </book> <book category="cooking"> <title lang="en">Everyday Italian</title> <author>Giada De Laurentiis</author> <year>2005</year> <price>30.00</price> </book> <book category="web"> <title lang="en">Learning XML</title> <author>Erik T. Ray</author> <year>2003</year> <price>39.95</price> </book> <book category="web"> <title lang="en">XQuery Kick Start</title> <author>James McGovern</author> <author>Per Bothner</author> <author>Kurt Cagle</author> <author>James Linn</author> <author>Vaidyanathan Nagarajan</author> <year>2003</year> <price>49.99</price> </book> </bookstore>
第一个 <book> 节点有四个节点:<title>, <author>, <year> 以及 <price>,其中每个节点都包含一个文本节点,"Harry Potter", "J K. Rowling", "2005" 以及 "29.99"。
注意文本存储在文本几点当中
在这个例子中:<year>2005</year>,元素节点 <year>,拥有一个值为 "2005" 的文本节点。
"2005" 不是 <year> 元素的值!
在上面的 XML 中,<title> 元素是 <book> 元素的第一个子节点,而 <price> 元素是 <book> 元素的最后一个子节点。
此外,<book> 元素是 <title>、<author>、<year> 以及 <price> 元素的父节点。
浏览器都内建了供读取和操作 XML 的 XML 解析器。
解析器把 XML 读入内存,并把它转换为可被 JavaScript 访问的 XML DOM 对象。
所有的解析器都含有遍历 XML 树、访问、插入及删除节点的函数。
js
xmlDoc=new ActiveXObject("Microsoft.XMLDOM");//微软的 XML 解析器
/*
xmlDoc= document.implementation.createDocument("","",null); //在 Firefox 及其他浏览器中的 XML 解析器
*/
xmlDoc.async="false"; xmlDoc.load("books.xml"); //loadXML() 方法用于加载字符串(文本),而 load() 用于加载文件。
- 第一行创建空的微软 XML 文档对象
- 第二行关闭异步加载,这样可确保在文档完整加载之前,解析器不会继续执行脚本
- 第三行告知解析器加载名为 "books.xml" 的文档
Internet Explorer 使用 loadXML() 方法来解析 XML 字符串,而其他浏览器使用 DOMParser 对象。
例如:
parser=new DOMParser(); xmlDoc=parser.parseFromString(txt,"text/xml");
- 第一行创建一个空的 XML 文档对象
- 第二行告知解析器加载名为 txt 的字符串
跨浏览器例子
try //Internet Explorer { xmlDoc=new ActiveXObject("Microsoft.XMLDOM"); } catch(e) { try //Firefox, Mozilla, Opera, etc. { xmlDoc=document.implementation.createDocument("","",null); } catch(e) {alert(e.message)} } try { xmlDoc.async=false; xmlDoc.load("books.xml"); document.write("xmlDoc is loaded, ready for use"); } catch(e) {alert(e.message)
出于安全方面的原因,现代的浏览器不允许跨域的访问。
这意味着,网页以及它试图加载的 XML 文件,都必须位于相同的服务器上。
假如你打算在自己的网页上使用上面的例子,则必须把 XML 文件放到自己的服务器上。否则,xmlDoc.load() 将产生错误 "Access is denied"。
XML DOM 含有遍历 XML 树以及访问、插入、删除节点的方法(函数)。
然后,在访问并处理 XML 文档之前,必须把它载入 XML DOM 对象。
一些典型的 DOM 属性:
- x.nodeName - x 的名称
- x.nodeValue - x 的值
- x.parentNode - x 的父节点
- x.childNodes - x 的子节点
- x.attributes - x 的属性节点
注释:在上面的列表中,x 是一个节点对象。
- x.getElementsByTagName(name) - 获取带有指定标签名称的所有元素
- x.appendChild(node) - 向 x 插入子节点
- x.removeChild(node) - 从 x 删除子节点
注释:在上面的列表中,x 是一个节点对象。
三个重要的 XML DOM 节点属性是:
- nodeName
- nodeValue
- nodeType
nodeName 属性规定节点的名称。
- nodeName 是只读的
- 元素节点的 nodeName 与标签名相同
- 属性节点的 nodeName 是属性的名称
- 文本节点的 nodeName 永远是 #text
- 文档节点的 nodeName 永远是 #document
nodeValue 属性规定节点的值。
- 元素节点的 nodeValue 是 undefined
- 文本节点的 nodeValue 是文本自身
- 属性节点的 nodeValue 是属性的值
例子

<?php $doc = new DOMDocument('1.0','utf-8'); $content = file_get_contents('http://feed.cnblogs.com/blog/u/530411/rss'); $doc->loadXML($content); $ts = $doc->getElementsByTagName('entry'); $arr=array(); ///*获取内容 原文链接 作者姓名 摘要 修改时间*/ foreach ($ts as $value) { //链接 $writer= '作者'.$value->getElementsByTagName('author')->item(0)->childNodes->item(1)->nodeValue.'<br/>'; $import='文章摘要'.$value->getElementsByTagName('content')->item(0)->textContent.'<br/>'; $pushtime='发布时间'.$value->getElementsByTagName('published')->item(0)->textContent; $arr[]=array( 'writer'=>$writer, 'import'=>$import, 'pushtime'=>$pushtime ); } print_r($arr);

在 XML DOM 中,节点的关系被定义为节点的属性:
- parentNode
- childNodes
- firstChild
- lastChild
- nextSibling
- previousSibling
节点操作:
获取属性值
txt=xmlDoc.getElementsByTagName("title")[0].getAttribute("lang");
在 DOM 中,每种成分都是节点。元素节点没有文本值。
元素节点的文本存储在子节点中。该节点称为文本节点。
获取元素文本的方法,就是获取这个子节点(文本节点)的值。
设置属性值
x[0].setAttribute("category","child");
//设置节点的某个属性的值
y=x.getAttributeNode("category");
//现获取该属性 设置属性
y.nodeValue="child";