python信用评分卡(附代码,博主录制)

变量筛选Variables Selection in Predictive Analytics

Predictive Analytics: Variables Selection – by Roopam
The following story goes back to the time when I just started my transition from physics to business. I met this investment banker* in his mid-thirties during a Friday night party. After gulping down a few pints of beer, his mood became a bit somber and he told me how he hates his job. However, he had a plan of working his ass off until he retires at 45. Then he will do everything that makes him happy. I was thoroughly confused, how could someone debar himself from an emotion – happiness – for so many years and rediscover it later? I was wondering about the recipe for happiness – raindrops on roses and whiskers on kittens. An individual’s happiness is a tricky thing; however, I shall attempt to tackle this issue in my later article on logistic regression. For now, let us try to explore how states measure the collective well-being of their people. I shall use this topic of population well-being to explore an interesting topic in analytical scorecard development: variables selection.
以下故事可以追溯到我刚开始从物理到商业的过渡时期。 我在周五晚上的聚会期间遇到了这位投资银行家*。 在喝了几品脱啤酒之后,他的心情变得有些忧郁,他告诉我他是如何讨厌自己的工作的。 然而,他有一个计划工作他的屁股,直到他在45退休。然后他会做一切让他开心的事情。 我彻底搞糊涂了,这么多年以后,有多少人会从情感 - 快乐中贬低自己,并在以后重新发现它? 我想知道快乐的秘诀 - 玫瑰上的雨滴和小猫的胡须。 个人的幸福是一件棘手的事情; 但是,我将在后面关于逻辑回归的文章中尝试解决这个问题。 现在,让我们试着探讨各国如何衡量其人民的集体福祉。 我将利用这个人口福祉主题来探索分析记分卡开发中的一个有趣话题:
Variables Selection – Lessons from GDP & GNH
The most popular measure for national prosperity, unanimously projected by economists and TV channels, is Gross Domestic Product (GDP). The equation for measuring GDP as taught in macroeconomics 101 is:
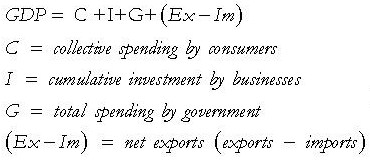
Clearly, there are 5 factors/variables that govern GDP according to this equation. The first look at GDP as a measure for national well-being seemed incomplete to me. All the variables for GDP were from commerce. They are important but cannot be the only factors for country’s well-being, more so in a highly diverse & complicated country like India.
ariables Selection - 来自GDP和GNH的经验教训
经济学家和电视频道一致预测的最受国民兴趣的衡量标准是国内生产总值(GDP)。 宏观经济学101中教授的衡量GDP的等式是:
GDP方程式
显然,根据这个等式,有5个因素/变量可以控制GDP。 首先将国内生产总值视为衡量国家福祉的指标对我来说似乎不完整。 GDP的所有变量都来自商业。 它们很重要,但不能成为国家福祉的唯一因素,在印度等高度多样化和复杂的国家更是如此。
Gross National Happiness Index – The Story of Bhutan Naresh

Variables Selection – by Roopam
Ok, so what else do we have? A lesser-known index is Gross National Happiness (GNH). The origins of GNH are in Bhutan. They measure their country’s progress through GNH. The term was coined and implemented by Jigme Singye Wangchuck. This name immediately takes me back to the early nineties live telecast of the SAARC summit by India’s national broadcaster Doordarshan (DD). The old-timer Hindi commentators were referring to a modest man in a bathrobe-like-attire as ‘Bhutan Naresh’ – King of Bhutan. At first glance, he did not fit well with the power horses of the south Asian region. Nevertheless, he seems to have devised a more holistic metric to measure his country’s well-being. GNH is a combination of the following broad categories:
1. Living standard & income
2. Health coverage
3. Physiological well-being
4. Time spent at work and relaxing
5. Good governance
6. Schooling & education
7. Cultural diversity
8. Community vitality
9. Environmentalism and conservatism
There are 72 total variables in GNH measured on a scale of 0 to 1, such as daily hours of sleep and trust in media; hmmm, not a bad start! You could do your own research on GNH and let me know what you feel about it. Actually, we can work out our own formula for a GNH like metric. The idea is to select the right variables to build your model!
国民幸福总指数 - 不丹纳雷什的故事
变量选择 - 由Roopam
好的,那我们还有什么呢?一个鲜为人知的指数是国民幸福总值(GNH)。 GNH的起源在不丹。他们通过GNH衡量他们国家的进步。该术语由Jigme Singye Wangchuck创造和实施。这个名字让我回到了印度国家广播公司Doordarshan(DD)在九十年代早期的SAARC峰会现场直播。旧时的印地语评论员指的是一个穿着浴衣般装扮的谦虚男人,就像不丹之王“不丹纳雷什”。乍一看,他并不适合南亚地区的动力马。然而,他似乎已经设计了一个更全面的衡量标准来衡量他的国家的福祉。 GNH是以下大类的组合:
1.生活水平和收入
2.健康保险
3.生理健康
4.工作和放松的时间
5.善治6.学校教育
7.文化多样性
8.社区活力
9.环境保护主义和保守主义
GNH中有72个总变量,按0到1的等级测量,例如每天的睡眠时间和对媒体的信任;嗯,这不是一个糟糕的开始!你可以自己研究GNH,让我知道你对它的看法。实际上,我们可以为GNH度量标准制定出我们自己的公式。我们的想法是选择正确的变量来构建您的模型!
Variables Selection in Credit Scoring
In data mining and statistical model building exercises, similar to credit scoring, variables selection process is performed through statistical significance – a reasonably automated process through advanced software. However, the variables are still created and measured by humans. High impact analyses in businesses are still driven by hunches. Human intelligence is not obsolete yet.
In one of the projects I did with a financial organization, the result of credit risk analysis and scoring led to redesigning of the application form. Application forms are a major source of data collection regarding the borrower. However, nobody wants to fill a lengthy form hence an optimal size of the form ensures accurate information provided by the borrower. The idea is to select the right variable and ensure accurate measurement.
There are several aspects regarding variables but I will mention just one of them here (coarse classing).
信用评分中的变量选择
在数据挖掘和统计模型构建练习中,类似于信用评分,变量选择过程通过统计显着性来执行 - 通过高级软件进行合理自动化的过程。 但是,变量仍由人类创造和测量。 企业的高影响力分析仍然受到预感的驱动。 人类智慧尚未过时。
在我与金融机构合作的一个项目中,信用风险分析和评分的结果导致了申请表的重新设计。 申请表是有关借款人的主要数据收集来源。 然而,没有人想要填写冗长的表格,因此表格的最佳尺寸确保了借款人提供的准确信息。 我们的想法是选择正确的变量并确保准确的测量。
关于变量有几个方面,但我在这里只提到其中一个(粗略分类)。
Coarse Classing in Credit Scoring

One of my favorite activities as a kid was going to a shoe store and getting my feet measured every summer before the school started. The shoe shops had a strange, miniature, slide-like device to measure foot size. It was fun to see my feet grow from one size to another every year or two. The growth was quantized i.e you are size-2 or 3 never 2.5 or 2.7. This aspect of converting measure such as 2.5 & 2.7 to 3 is called grouping, bucketing or classing. This is an integral part of creating scorecards that you will find in all the books I have listed in the first part of this blog series.
I have been a part of several heated discussions on the relevance of coarse class in scorecard development throughout my career. In most, if not all academic articles you will rarely see coarse classing as a technique during model development. Quite a few academicians & practitioners for a good reason believe that coarse classing results in loss of information. However, in my opinion, coarse classing has the following advantage over using raw measurement for a variable.
1. It reduces random noise that exists in raw variables – similar to averaging and yes, you lose some information here.
2. It handles extreme events – on two extremes of a variable – much better where you have thin data.
3. It handles the non-linear relationship between dependent and independent variable without a lot of effort of variable transformation from the analyst.
信用评分中的粗分类
3鞋子测量我小时候最喜欢的一项活动是去一家鞋店,每年夏天在学校开始前测量我的脚。这些鞋店有一个奇怪的,微型的滑动式设备来测量脚的大小。每年或每两年看到我的脚从一个尺寸增长到另一个尺寸很有趣。增量被量化,即你的大小为2或3从不2.5或2.7。将诸如2.5和2.7之类的度量转换为3的这一方面称为分组,分组或分类。这是创建记分卡的一个组成部分,您可以在本博客系列的第一部分列出的所有书籍中找到这些记分卡。
在我的职业生涯中,我参与了几个关于粗俗课程在记分卡开发中的相关性的热烈讨论。在大多数情况下,如果不是所有的学术文章,你很少会在模型开发过程中看到粗略的分类。相当多的学者和从业者有充分理由相信粗略的分类会导致信息丢失。但是,在我看来,粗略分类比使用变量的原始测量具有以下优势。
1.它减少了原始变量中存在的随机噪声 - 类似于平均值,是的,你在这里丢失了一些信息。
它处理极端事件 - 在变量的两个极端情况下 - 在您拥有精简数据的情况下更好。
3.它处理依赖变量和自变量之间的非线性关系,而无需分析师进行变量转换。
Sign-off Note
We are half way through this series on ‘Analytical Scorecard Development’ and I am enjoying writing this thoroughly. I hope as a reader you are on the same page. Scorecard building is highly technical and I have tried to discuss some aspects with easy to understand examples. However, to manage the length of the article, I am not able to get into the details. I must say that I love the details! So, if you have any queries, doubts, points-of-view or recommendations please write back on the discussion board or on my email: roopam.up@gmail.com
python风控建模实战lendingClub(博主录制,catboost,lightgbm建模,2K超清分辨率)
https://study.163.com/course/courseMain.htm?courseId=1005988013&share=2&shareId=400000000398149

微信扫二维码,免费学习更多python资源
