python信用评分卡(附代码,博主录制)

互联网金融可以应用的大数据,首先体现在社交数据:微博微信等社交平台早已深入人们的日常生活中,产生了大量文本数据和图像视频数据,这些数据的处理和存储,分析,对于相关互联网企业产生了挑战。相应的存储,处理和分析的需求应运而生。
这些数据的第一个特点是非结构化,不是像传统的数据,每个变量定义清晰,一条一条地存储在数据表中。
第二个特点是多维度。比如,法律,旅游,水电,社保,娱乐,消费……等等维度的增加,也体现了大数据的“大”。
在互联网金融领域现阶段,分析这些数据产生个人信用的评分,和P2P公司实际业务所需要的评分模型,还有一定差距。
单纯基于大数据的模型效用有限
互联网金融的风险控制模型经常用到评分卡,例如:个人信用等级评分卡。然而要做评分卡,要计算相应的违约率,首先应该根据业务,定义目标变量,即输出变量:什么样的客户算好客户,什么样的客户是坏客户。根据这个目标变量,我们再选择相关的其它变量来考察各输入变量对输出变量的贡献。
目前,很多企业在做单纯基于大数据的评分模型,并没有把违约与否的情况和网上的行为数据拼接起来,貌似有了一个评分,那也不过是按照自己的理解,对网上行为做了一个初步的整理,从模型的角度,已经有了偏差,即模型偏差。所以在应用上,要做到对风险进行准确定价,实用价值有限。
然而我并不是说所有的主要基于大数据的模型都不能用,我们要分开来看这个问题,对于像淘宝,京东等形成自己的业务闭环的商业模式中,尽可以使用各种方法对自己业务中产生大数据进行分析,因为他们的目标变量和所谓大数据变量是可以拼接到一起的。但是对于P2P机构来说,由于并不是所有的贷款申请人都有淘宝账户,京东账户,所以这里的所谓大数据,大数据模型要落地还是比较困难的。
回归到互联网金融领域,对于申请人,如果拉一个央行的征信报告,那还算方便,其实征信报告的数据也比较规范,只不过是维度增加了;如果要拼接在网上的行为,各方面难度就比较大了。
同时由于”大数据” 的收集,整理,存储,预处理,分析等的投入都比较大,所以我在这里说,有个所谓的费效比的8/2 效应。即对大数据分析投入的精力与其产出实际效应的比例约为8:2。由此可见,单纯基于大数据构建的互联网金融风控模型意义是有限的。
如果为P2P公司构建风控模型的工作中,使用的大多数是脱敏数据(不包含姓名等个人信息),这就使与大数据拼接十分困难。目前大数据对于互联网金融领域的贡献,我们认为主要在反欺诈领域,我们为P2P公司风险控制设计的反欺诈模型就利用了很多互联网的数据源。
随着互联网金融和中国征信行业的发展,我相信大数据也会越来越多的为我们的风控模型贡献价值。
传统数据和大数据拼接
在社交数据出现之前,互联网金融行业已经积累了大量的业务数据,这些业务数据基本上都是结构化存储,而且数据质量都比较好,数据的业务定义也比较清晰。所以在应用”大数据”之前,怎么发挥已有的结构化数据的价值,是我们数据分析建模工作的基础,和目前的重点。
那么具体的, 我们应该如何结合现有的数据选择怎么样的算法来做这个事情呢?
在传统银行以及大多数互联网金融机构,首先看的是违约,那么就把违约与否作为好坏客户的定义,然后在选择诸如,工资,性别,年龄,房产,车产等作为输入变量,这是所谓的传统、结构化数据,我也称之为基础数据;而对于大数据,我们认为,应该在传统数据的基础上,相对于目标变量,做一个拼接,即:
目标变量 = 基础变量 + 大数据变量
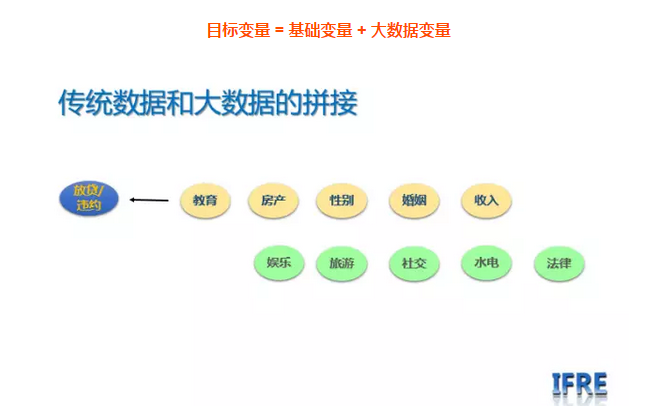
只有在此基础上,做出来的模型才有意义。但是,做这个拼接,从数据收集的角度来说,是有难度的。
实际上,在传统金融领域,对于违约与否,主要考察的是两个方面,还款能力和还款意愿。理论上说,如果直接有这两个变量,那我们就不需要其他的输入变量了。我们所选择的一些输入变量,就是来还原这两个方面。同时,我们之所以在模型中加入大数据,也是因为某些数据的加入,能对更准确还原这两方面贡献一些信息。
同时,互联网金融,有丰富多彩的业务模式,风险管理注重的方面也大大丰富了,如恶意欺诈,多头负债,朋友贷中对信誉的高度重视,学生贷中考察他的学业能力, 等等。
风控模型需要多大数据
+
下面我们来聊聊互联网金融风控模型需要多大的数据?这需要先回答一个问题: “最少需要多少数据?数据是不是越多越好?“
作为IFRE技术负责人与客户接触的时候,经常碰到一个问题:由于众所周知的原因,各家P2P机构对自己的违约率都比较敏感,担心全量数据给我们之后,泄露商业机密,这是可以理解的。但是显然,全量数据所做的模型应该是最准确的。
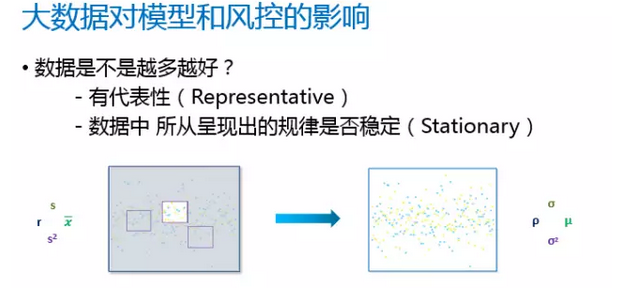
真随机抽样
在没有大数据这个名词出现之前, 我们做模型对于数据的要求是这样的:抽样的样本对于总体有代表性(representative):即样本和总体的各项指标是一样的,那么用样本做出来的模型,才可以代表总体;第二个假设是,总体数据做隐含的规律是稳定的(stationary/stability)。
同时还有一个隐含的假设,做模型的数据表现和要用到模型的个体数据的统计性状是相同的,即用历史数据模拟的分数,和以后的客户,如果评分相同,那么他们的表现也相同。只有这样,模型才可以用。否则,还是会产生偏差。
假设有输入变量,”性别”,包含两个属性:
男, 女; 身高,包含三个属性:高,中,低。
那么,所有的属性组合是 2*3=6个属性,即:
“男,高”,“男,中”, “男,低“,“女,高”,“女,中”, “女,低“。

引申开来,如果模型中有10个输入变量,每个有两个属性,那么至少需要2的十次方,1024 条数据, 才能把这些属性组合覆盖。我们才能说,哪一个属性对于目标变量的贡献是多少,然后是哪一个变量对于目标变量的贡献是多少。随着变量的增加,对于数据数量的要求是指数级增长。
由此可知,在互联网金融风控模型搭建中,基于成本与效率考虑,数据并不是越多越好,同时我们需要具有稳定性数据,更需要对每一个变量背后的业务含义具有深刻的了解。后面的文章中,我会继续探讨数据仓库搭建,数据清洗以及数据缺失值填补等问题。
python风控建模实战lendingClub(博主录制,catboost,lightgbm建模,2K超清分辨率)
https://study.163.com/course/courseMain.htm?courseId=1005988013&share=2&shareId=400000000398149

微信扫二维码,免费学习更多python资源
