python机器学习-乳腺癌细胞挖掘(博主亲自录制视频)
https://study.163.com/course/introduction.htm?courseId=1005269003&utm_campaign=commission&utm_source=cp-400000000398149&utm_medium=share

A 方案--我的回归模型
(1)Input.py 通过excel接口,输入数据
(2)linear_R.py 通过导入Input.py输入数据, 此脚本用于选择最佳mode
(3)input_decide.py 确定模型后,对输入的x和y列表参数进行预处理
(4)最后执行主函数 Linear_main.py
分析汇总:
R平方达到0.998,预测准确性相当高
但是最后三年的残差数据偏离度大,而最后真实数据与最近三年权重关系很大,需要考虑其他模型
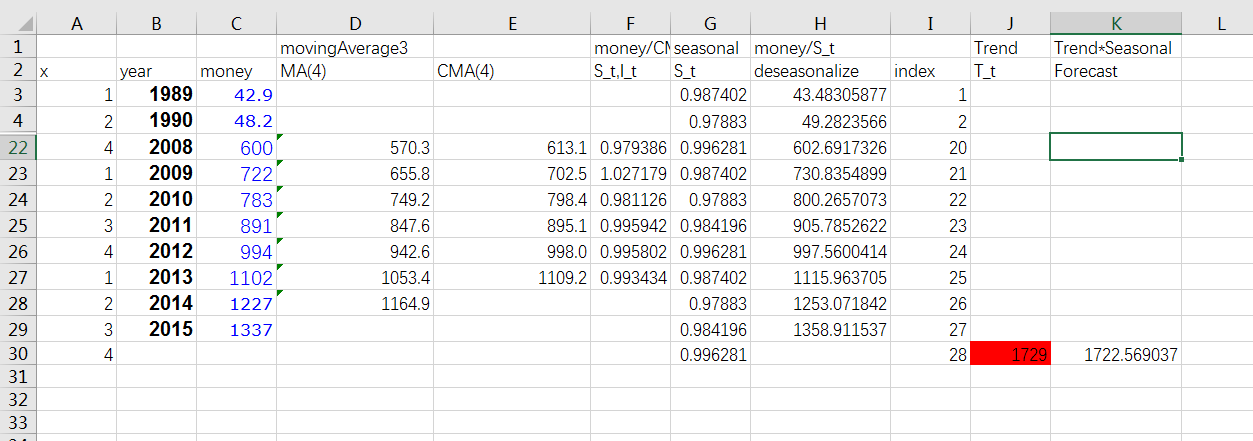
B 方案---excel 数据分析
R平方达不到0.9,而且预测数据远低于最近三年数据,比我的模型还不如,直接pass
方案C 时间序列
预测数据1722,但是回归预测中最后5年偏差还是很大,不一定准确,需要更好算法
方案D 移动平均加权
大陆军费开支数据
通过excel接口,输入数据
Input.py


#coding=utf-8 #通过excel接口,输入数据 import xlrd excelFileName="中国军费开支1.xlsx" wb=xlrd.open_workbook(excelFileName) sheet=wb.sheets()[0] list_y=sheet.col_values(2)[1:] list_x=sheet.col_values(0)[1:]
#linear_R.py
#,通过导入Input.py输入数据, 此脚本用于选择最佳mode
#coding=utf-8
#linear_R.py
#此脚本用于选择最佳mode
import math,input_process,Input
def Mean(sample_list):
mean_value=float(sum(sample_list))/len(sample_list)
return mean_value
def Variance_sample(sample_list):
#mean数组的平均数
mean= Mean(sample_list)
#数组的长度
length=len(sample_list)
sum1=0
for i in range(length):
#print "i:",i
sum1+=(sample_list[i]-mean)**2
#print "sum1:",sum1
#variance=sum1/length
variance=sum1/(length)
return variance
def Deviation(sample_list):
variance=Variance_sample(sample_list)
deviation=math.sqrt(variance)
return deviation
def R_xy(s_xy,s_x,s_y):
r_xy=float(s_xy)/(s_x*s_y)
#r_xy=round(r_xy_value,5) #保留五位小数
return r_xy
def S_xy(list_x,list_y):
x_mean=Mean(list_x)
y_mean=Mean(list_y)
if len(list_x)!=len(list_y):
print ("erro")
s_xy=0
total=0
for i in range(len(list_x)):
sum1=list_x[i]*list_y[i]
total+=sum1
s_xy=(float(total)/len(list_x))-(x_mean*y_mean)
return s_xy
#计算linear mode 的R平方值
def R_square_mode_linear(list_x,list_y):
#x平均数
x_mean=Mean(list_x)
#print "x_mean:",x_mean
#y平均数
y_mean=Mean(list_y)
#print "y_mean:",y_mean
#list_x的标准差
s_x=Deviation(list_x)
#print "s_x:",s_x
#list_y的标准差
s_y=Deviation(list_y)
#print "s_y:",s_y
s_xy=S_xy(list_x,list_y)
#print "s_xy:",s_xy
#r_xy_value为{x_i}和{y_i}的相关系数
r_xy=R_xy(s_xy,s_x,s_y)
#print "r_xy:",r_xy
#计算R平方
r_square=r_xy**2
#print "r_square:",r_square
return r_square
def R_square_mode_1(list_x,list_y):
#输入两个列表取对数,生成两个新列表
list_x=input_process.Reciprocal_list(list_x)
#x平均数
x_mean=Mean(list_x)
#print "x_mean:",x_mean
#y平均数
y_mean=Mean(list_y)
#print "y_mean:",y_mean
#list_x的标准差
s_x=Deviation(list_x)
#print "s_x:",s_x
#list_y的标准差
s_y=Deviation(list_y)
#print "s_y:",s_y
s_xy=S_xy(list_x,list_y)
#print "s_xy:",s_xy
#r_xy_value为{x_i}和{y_i}的相关系数
r_xy=R_xy(s_xy,s_x,s_y)
#print "r_xy:",r_xy
#计算R平方
r_square=r_xy**2
#print "r_square:",r_square
return r_square
def R_square_mode_2(list_x,list_y):
#输入两个列表取对数,生成两个新列表
log_list_x=input_process.log_list(list_x)
log_list_y=input_process.log_list(list_y)
#对两个新列表取平均数
x_mean=Mean(log_list_x)
y_mean=Mean(log_list_y)
#对两个新列表算标准差
s_x=Deviation(log_list_x)
s_y=Deviation(log_list_y)
s_xy=S_xy(log_list_x,log_list_y)
#r_xy_value为{x_i}和{y_i}的相关系数
r_xy=R_xy(s_xy,s_x,s_y)
#计算R平方
r_square=r_xy**2
return r_square
def R_square_mode_3(list_x,list_y):
#y列表取对数,生成新列表
log_list_y=input_process.log_list(list_y)
#对两个新列表取平均数
x_mean=Mean(list_x)
y_mean=Mean(log_list_y)
#对两个新列表算标准差
s_x=Deviation(list_x)
s_y=Deviation(log_list_y)
s_xy=S_xy(list_x,log_list_y)
#r_xy_value为{x_i}和{y_i}的相关系数
r_xy=R_xy(s_xy,s_x,s_y)
#计算R平方
r_square=r_xy**2
return r_square
def R_square_mode_5(list_x,list_y):
#y列表取对数,生成新列表
negative_reciprocal_x=input_process.negative_reciprocal_list(list_x)
log_list_y=input_process.log_list(list_y)
#for test
#print"negative_reciprocal_x:",negative_reciprocal_x
#print"log_list_y",log_list_y
#对两个新列表取平均数
x_mean=Mean(negative_reciprocal_x)
y_mean=Mean(log_list_y)
#对两个新列表算标准差
s_x=Deviation(negative_reciprocal_x)
s_y=Deviation(log_list_y)
s_xy=S_xy(negative_reciprocal_x,log_list_y)
#r_xy_value为{x_i}和{y_i}的相关系数
r_xy=R_xy(s_xy,s_x,s_y)
#计算R平方
r_square=r_xy**2
return r_square
def R_square_mode_6(list_x,list_y):
#x列表取平方数
square_list_x=input_process.square_list(list_x)
#x平均数
x_mean=Mean(square_list_x)
#y平均数
y_mean=Mean(list_y)
#list_x的标准差
s_x=Deviation(square_list_x)
#list_y的标准差
s_y=Deviation(list_y)
s_xy=S_xy(square_list_x,list_y)
#r_xy_value为{x_i}和{y_i}的相关系数
r_xy=R_xy(s_xy,s_x,s_y)
#计算R平方
r_square=r_xy**2
return r_square
def R_square_mode_7(list_x,list_y):
#输入两个列表取对数,生成两个新列表
list_x=input_process.log_list(list_x)
#x平均数
x_mean=Mean(list_x)
#print "x_mean:",x_mean
#y平均数
y_mean=Mean(list_y)
#print "y_mean:",y_mean
#list_x的标准差
s_x=Deviation(list_x)
#print "s_x:",s_x
#list_y的标准差
s_y=Deviation(list_y)
#print "s_y:",s_y
s_xy=S_xy(list_x,list_y)
#print "s_xy:",s_xy
#r_xy_value为{x_i}和{y_i}的相关系数
r_xy=R_xy(s_xy,s_x,s_y)
#print "r_xy:",r_xy
#计算R平方
r_square=r_xy**2
#print "r_square:",r_square
return r_square
def R_square_list(list_x,list_y,mode_list):
r_square_list=[]
best_mode=0
r_square=0
#计算R_square_list
for i in mode_list:
mode=i
if mode=="linear":
r_square=R_square_mode_linear(list_x,list_y)
r_square_list.append(r_square)
if mode==1:
r_square=R_square_mode_1(list_x,list_y)
r_square_list.append(r_square)
if mode==2:
r_square=R_square_mode_2(list_x,list_y)
r_square_list.append(r_square)
if mode==3:
r_square=R_square_mode_3(list_x,list_y)
r_square_list.append(r_square)
if mode==5:
r_square=R_square_mode_5(list_x,list_y)
r_square_list.append(r_square)
if mode==6:
r_square=R_square_mode_6(list_x,list_y)
r_square_list.append(r_square)
if mode==7:
r_square=R_square_mode_7(list_x,list_y)
r_square_list.append(r_square)
return r_square_list
def Dict_r_mode(r_square_list,mode_list):
dict_r_mode=dict(zip(r_square_list,mode_list))
#print"dict:R^2 and mode",dict_r_mode
return dict_r_mode
#mode函数模型自动判断
def Mode_choose(r_square_list):
#R平方列表,采用最大值对应mode
best_r_square=max(r_square_list)
best_mode=dict_r_mode[best_r_square]
return best_mode
#导入Input内数据
list_x=Input.list_x
list_y=Input.list_y
#绘图模式,mode=linear(线性标准)
#其它有
#mode=1 (y=a+b/x)
#mode=2 (y=a*x**b)
#mode=3 (y=a*e**(b*x))
#mode=4 (y=a*e**(b/x))
#mode=5 (y=a*e**(-b/x))
#mode=6 (y=b*x**2+a)
#mode=7 (y=a+b*lnx)
mode_list=["linear",1,2,3,5,6,7]
r_square_list=R_square_list(list_x,list_y,mode_list)
dict_r_mode=Dict_r_mode(r_square_list,mode_list)
mode=Mode_choose(r_square_list)
#测试时修改mode
#mode='linear'
#mode=1
#mode=7
#mode=2
input_decide.py
确定模型后,对输入的x和y列表参数进行预处理
#coding=utf-8
#input_decide.py
#确定模型后,对输入的x和y列表参数进行预处理
import math,Input,input_process,linear_R
list_x1=Input.list_x
list_y1=Input.list_y
mode=linear_R.mode
def List_x(list_x1,mode):
if mode=="linear":
#list_x不变
list_x=list_x1
if mode==1:
list_x=input_process.Reciprocal_list(list_x1)
if mode==2:
#输入两个列表取对数,生成两个新列表
list_x=input_process.log_list(list_x1)
if mode==3:
#list_x不变
list_x=list_x1
if mode==5:
#输入两个列表取对数,生成两个新列表
list_x=input_process.negative_reciprocal_list(list_x1)
if mode==6:
#输入两个列表取对数,生成两个新列表
list_x=input_process.square_list(list_x1)
if mode==7:
#输入两个列表取对数,生成两个新列表
list_x=input_process.log_list(list_x1)
return list_x
def List_y(list_y1,mode):
if mode=="linear":
#list_y不变
list_y=list_y1
if mode==1:
#输入两个列表取对数,生成两个新列表
list_y=list_y1
if mode==2:
#输入两个列表取对数,生成两个新列表
list_y=input_process.log_list(list_y1)
if mode==3:
#输入两个列表取对数,生成两个新列表
list_y=input_process.log_list(list_y1)
if mode==5:
#输入两个列表取对数,生成两个新列表
list_y=input_process.log_list(list_y1)
if mode==6:
#输入两个列表取对数,生成两个新列表
list_y=list_y1
if mode==7:
#list_y不变
list_y=list_y1
return list_y
list_x=List_x(list_x1,mode)
list_y=List_y(list_y1,mode)
最后执行主函数
#主函数Linear_main.py
#coding=utf-8
#目录:
#14.一元线性回归
#r^2自动判断模型是否合适
#residual判断错误值
#其它函数转换成一元线性回归
#1.单词
#排列permutation,组合combination,阶乘factorial 概率probability
import math,pylab,numpy,linear_R,input_decide,input_process,Input
def Mean(sample_list):
mean_value=float(sum(sample_list))/len(sample_list)
return mean_value
def Variance_sample(sample_list):
#mean数组的平均数
mean= Mean(sample_list)
#数组的长度
length=len(sample_list)
sum1=0
for i in range(length):
#print "i:",i
sum1+=(sample_list[i]-mean)**2
#print "sum1:",sum1
#variance=sum1/length
variance=sum1/(length)
return variance
def Deviation(sample_list):
variance=Variance_sample(sample_list)
deviation=math.sqrt(variance)
return deviation
def S_xy(list_x,list_y):
x_mean=Mean(list_x)
y_mean=Mean(list_y)
if len(list_x)!=len(list_y):
print ("erro")
s_xy=0
total=0
for i in range(len(list_x)):
sum1=list_x[i]*list_y[i]
total+=sum1
s_xy=(float(total)/len(list_x))-(x_mean*y_mean)
return s_xy
#14.一元线性回归
def R_xy(s_xy,s_x,s_y):
r_xy=float(s_xy)/(s_x*s_y)
#r_xy=round(r_xy_value,5) #保留五位小数
return r_xy
#r的平方可以判断模型是否合适,r的平方值越大,越合适,反之亦然
def R_estimate(r_xy_value):
if r_xy_value**2>0.8:
return True
else:
return False
#线性回归模式
def Linear_b(s_xy,s_x):
b=s_xy/s_x**2
#b=round(b,4)
return b
def Linear_a(b,x_mean,y_mean):
a=y_mean-b*x_mean
#a=round(a,4)
#当mode=2或3或5时,a要特殊处理
if mode==5 or mode==2 or mode==3:
a1=y_mean-b*x_mean
#print "a1:",a1
a=math.e**a1
return a
#预算将来值
def Forecast_linear(b,a,forecast_x,mode):
#对mode采用不同计算模式
y_forecast=0
if mode=="linear":
y_forecast=b*forecast_x+a
if mode==1:
#print "forecast_x:",forecast_x
y_forecast=a+b/forecast_x
if mode==2:
y_forecast=a*(forecast_x**b)
if mode==3:
y_forecast=a*(math.e**(b*forecast_x))
if mode==5:
y_forecast=a*(math.e**(float(-b)/forecast_x))
if mode==6:
y_forecast=a+(b*forecast_x**2)
if mode==7:
y_forecast=a+b*math.log(forecast_x,math.e)
#y_forecast=round(y_forecast,0)#不保留小数
#y_forecast=int(y_forecast) #取整数
return y_forecast
#绘制一元线性分布图
def Draw_linear_regression_model(list_x_initial,list_y_initial,b,a,mode):
#先画点,再画线
#list_x和list_y是绘制点的x和y值集合,b,a是参数,mode是绘制模式
#绘制点分布
pylab.plot(list_x_initial,list_y_initial,'ro') #'ro'表示绘制点
#x取值范围智能化
#x_min=min(list_x) x=min(list_total)/1.5
x_max=max(list_x_initial)*1.5
x=numpy.arange(0.01,x_max) #x取值范围可以随意更改
#计算y值
y=Forecast_linear(b,a,x,mode)
#绘制方程式
pylab.plot(y)
# Pad margins so that markers don't get clipped by the axes,让点不与坐标轴重合
pylab.margins(0.3)
pylab.grid(True)
pylab.title("linear regression model")
pylab.show()
#程序后期检验工作
#建模线性回归方程后,算出y的近似值
def Linear_y(b,a,list_x_initial,mode):
list_linear_y=[]
for i in list_x_initial:
#print 'i:',i
value=Forecast_linear(b,a,i,mode)
#print value
list_linear_y.append(value)
return list_linear_y
#计算residual残差列表
def Residual(list_y_initial,list_linear_y):
residual_list=[]
for i in range(len(list_y_initial)):
value=list_y_initial[i]-list_linear_y[i]
residual_list.append(value)
return residual_list
#根据residual残差检验数据错误
def WrongNumber_check(list_x_initial,list_y_initial,residual_list):
#预测不准确残差值
wrongNumber_predict=[]
#点元组为元素,生成列表
list_dot=zip(list_x_initial,list_y_initial)
#残差和点为元素,组成列表
list_residual_dot=zip(residual_list,list_dot)
dict_residual_dot=dict(list_residual_dot)
#判断标准benchmark
absolute_residual_list=input_process.Absolute_list(residual_list)
benchmark=1.5*Mean(absolute_residual_list)
#遍历残差值,如果残差绝对值大于标准值,则对应的点添加到错值预测列表
for i in residual_list:
if math.fabs(i)>benchmark:
wrongNumber=dict_residual_dot[i]
wrongNumber_predict.append(wrongNumber)
#print"wrongNumber prediction:",wrongNumber_predict
return wrongNumber_predict
#绘制残点图
def Draw_residual(residual_list):
x=[i for i in range(1,len(residual_list)+1)]
y=residual_list
pylab.plot(x,y,'ro')
pylab.title("draw residual to check wrong number")
# Pad margins so that markers don't get clipped by the axes,让点不与坐标轴重合
pylab.margins(0.3)
#绘制网格
pylab.grid(True)
pylab.show()
def print_out(x_mean,y_mean,s_x,s_y,s_xy,r_xy,r_estimate,
b,a,forecast_value,wrongNumber_Predict,mode):
print ("x_mean:",x_mean)
print ("y_mean:",y_mean)
print ("s_x:",s_x)
print ("s_y:",s_y)
print ("s_xy:",s_xy)
print ("r_xy:",r_xy)
print ("r_square:",r_square)
print ("r_estimate:",r_estimate)
print ("b:",b)
print ("a:",a)
print ("forecast_value:",forecast_value)
print ("wrongNumber_Predict:",wrongNumber_Predict)
print ("the best mode:",mode)
#输出方程式:
if mode=="linear":
print ("y=a+b*x")
if mode==1:
print ("y=a+b/x")
if mode==2:
print ("y=a*x**b")
if mode==3:
print ("y=a*e**(b*x)")
if mode==5:
print ("y=a*e**(-b/x)")
if mode==6:
print ("y=b*x**2+a")
if mode==7:
print ("y=a+b*lnx")
#execution
#standard mode
def execution_linear_regression():
#standard print
print_out(x_mean,y_mean,s_x,s_y,s_xy,r_xy,r_estimate,
b,a,forecast_value,wrongNumber_Predict,mode)
#draw regression linear
Draw_linear_regression_model(list_x_initial,list_y_initial,b,a,mode)
#draw residual
Draw_residual(residual_list)
mode=linear_R.mode
list_x_initial=Input.list_x
list_y_initial=Input.list_y
#处理后的最终参数
list_x=input_decide.list_x
list_y=input_decide.list_y
#预测值
forecast_x=28
#绘图模式,mode=linear(线性标准)
#其它有
#mode='linear' (y=a+b*x)
#mode=1 (y=a+b/x)
#mode=2 (y=a*x**b)
#mode=3 (y=a*e**(b*x))
#mode=5 (y=a*e**(-b/x))
#mode=6 (y=b*x**2+a)
#mode=7 (y=a+b*lnx)
mode_list=["linear",1,2,3,5,6,7]
#x mean value
x_mean=Mean(list_x)
#y mean value
y_mean=Mean(list_y)
#list_x variance
s_x=Deviation(list_x)
#list_y variance
s_y=Deviation(list_y)
s_xy=S_xy(list_x,list_y)
#r_xy_value is the ratio of {x_i} and {y_i}
r_xy=R_xy(s_xy,s_x,s_y)
#R平方
r_square=r_xy**2
#estimate r'value
r_estimate=R_estimate(r_xy)
#b
b=Linear_b(s_xy,s_x)
#a
a=Linear_a(b,x_mean,y_mean)
forecast_value=Forecast_linear(b,a,forecast_x,mode)
#get y's approximation
list_linear_y=Linear_y(b,a,list_x_initial,mode)
#residual
residual_list=Residual(list_y_initial,list_linear_y)
wrongNumber_Predict=WrongNumber_check(list_x_initial,list_y_initial,residual_list)
#输出详细参数数据和图
execution_linear_regression()
执行完成后程序输出的参数
R平方达到0.998,预测准确性相当高
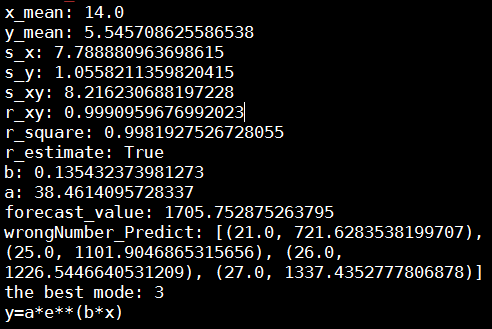
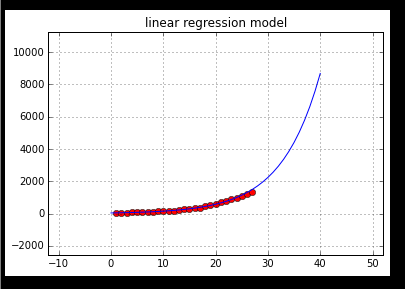
但是最后三年的残差数据偏离度大,而最后真实数据与最近三年权重关系很大,需要考虑其他模型

B 方案---excel 数据分析
R平方达不到0.9,而且预测数据远低于最近三年数据,比我的模型还不如,直接pass
方案C 时间序列
预测数据1722,但是回归预测中最后5年偏差还是很大,不一定准确,需要更好算法