Python爬虫视频教程零基础小白到scrapy爬虫高手-轻松入门
https://item.taobao.com/item.htm?spm=a1z38n.10677092.0.0.482434a6EmUbbW&id=564564604865

# -*- coding: utf-8 -*-
"""
Created on Mon May 9 09:14:32 2016
@author: Administrator
"""
import requests,bs4,csv,time,selenium,random
from selenium import webdriver
site_hubei="http://china.guidechem.com/suppliers/list_catid-21_area-%E6%B9%96%E5%8C%97"
pages_hubei=31
def Get_sites(site,pages):
list_pages=[]
for page in range(1,pages+1):
thePage=site+"-"+"p"+str(page)+".html"
list_pages.append(thePage)
return list_pages
#采集一个公司的二级网址
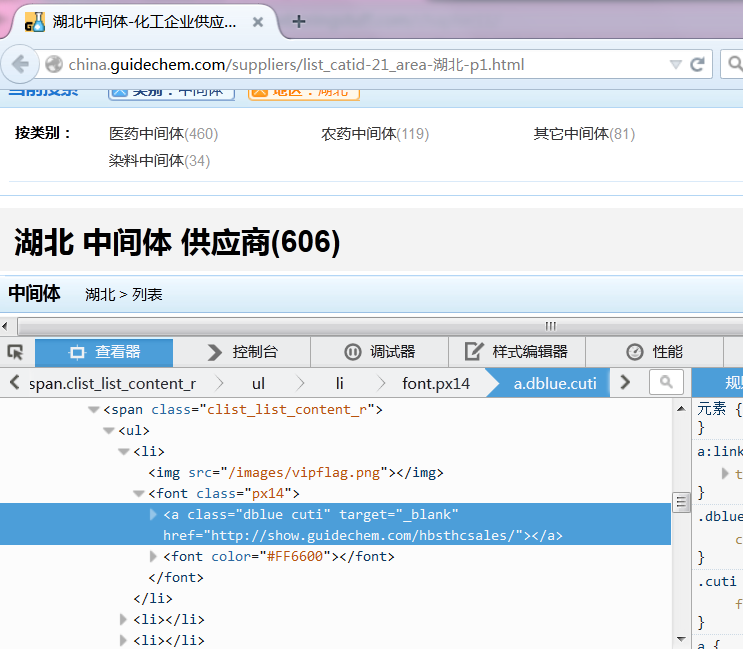
def Get_corporation_site():
elems=browser.find_elements_by_class_name("dblue")
links_list=[i.href for i in elems]
return links_list
list_pages_hubei=Get_sites(site_hubei,pages_hubei)
browser=webdriver.Firefox()
#访问湖北省首页
browser.get(list_pages_hubei[0])
elems=browser.find_elements_by_class_name("dblue")
links_list=[i.get_attribute("href") for i in elems]