HDFS的读流程
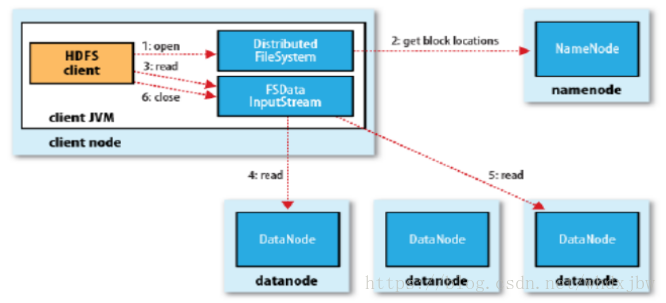
- 客户端首先通过在FileSystem上调用open()方法打开它想要打开的文件,对于HDFS来说,就是在DistributedFileSystem的实例上调用。
- 之后DistributedFileSystem就与NameNode进行RPC通信,查明组成文件的前几个块的位置,对于每一个块,NameNode会返回拥有块拷贝的DataNode的地址。DistributedFileSystem返回一个FSDataInputStream给客户端,客户端就能从流中读取数据,FSDataInputStream中封装了一个管理了DataNode与NameNode I/O的DFSInputStream。
- 之后客户端就调用read()方法。存储了文件的前几个块的地址的DFSInputStream,就会连接存储第一个人(最近的)DataNode.
- 然后DFSInputStream就通过重复调用read()方法,数据就从DataNode流动到了客户端(这个过程对客户端说是透明的,在库乎端那边看来,就像是只读取了一个连续不断的流)。
- 当该DataNode中最后一个块读取完成了,DFSInputStream会关闭与DataNode的连接,然后为下一个寻找最佳节点块是按顺序读的,通过DFSInputStream在DataNode上打开新的连接去作为客户端读取的流。它也将会呼叫NameNode来取得下一批所需要的块所在的DataNode的位置。
- 当客户端完成了读取,就在FSDtaInputStream上调用close()方法。
关于读的过程发生异常情况
- 在读取中,如果FSDataInputStream在和一个DataNode进行交流时出现了一个错误,他就去试一试下一个个最接近的块,它也会记住刚才发生错误的DataNode以至于之后不会再这个DataNode上进行没有必要的尝试。
- DFSInputStream也会再DataNode上传输的数据上检查checksums,如果损坏的块被发现了,DFSInputStream就试图从另一个拥有备份的DataNode中去读取备份块中的数据。