索引的概念:
索引是提高查询速度的一种手段。索引有很多种,以下是索引树的结构
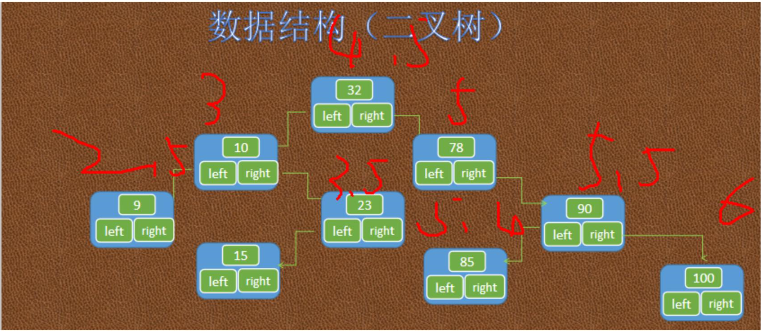
要求查询出薪资大于5000的雇员信息,只要在树中找到5000的节点,直接查询该节点右边的数据即可,左边就不用管了,这样提高了查询的效率。
将数据按照索引数据的方式保存需要先创建索引。
基本语法:
CREATE INDEX 索引名 ON 数据表(字段名);
删除索引:
DROP INDEX 索引名;
注意:系统默认主键使用索引。
复合索引
一个索引在多个字段上创建,就是一个索引作用于多个字段。
例如:CREATE INDEX 索引名 ON 数据表(字段1,字段2);
注意:查询数据使用字段2,此时使用的是全表扫描模式,查询数据使用字段1,此时使用的是索引扫描模式。(此现象叫做索引的最左原则)
在Oracle中使用了多个字段,并且是AND 连接的条件,那么字段的顺序不影响扫描的方式(索引扫描),如果是mysql则需要和复合索引的字段顺序一致。使用OR连接条件会导致索引失效,应该使用UNION ALL 代替OR查询。
总结:索引不能随便用。如果一张数据表更新频率太高,更新数据之后需要重新创建索引,这一过程很耗费性能。
Sql的优化*(面试题)
1、对查询进行优化,要尽量避免全表扫描,首先应考虑在进行条件判断的字段上创建索引。(使用索引的数据表不能更新频率太高,否则需要重新再创建索引,耗费性能。)
2、尽量避免在WHERE子句中对字段进行null值判断、对字段进行表达式计算操作、使用!=或<>操作符、使用or来连接条件(如果一个条件有索引一个没有索引),否则将导致引擎放弃使用索引而进行全表扫描。
3、NOT IN 要慎用,否则会导致全表扫描,可用NOT EXISTS代替。
4、模糊查询使用了“%”也会导致索引失效(可以将用户可能输入的关键字使用下拉列表列出来,在数据库中使用全名称查询,比如说:SELECT * FROM emp WHERE job LIKE ‘关键字’)。
5、使用复合索引要满足最左原则,并且应尽可能的让字段顺序与索引顺序一致。
6、UPDATE语句,不要更改全部字段,否则需要重新创建索引,损耗性能
7、对于多张大数据(几百条)的连接(多表连接查询),可以考虑使用程序去实现,尽量不要连接查询(多表查询出现笛卡尔积增加内存开销)。
8、索引不是越多越好,索引提高了select查询的效率,但同时也降低了insert插入及update更新的效率,插入或更新有时可能会重建索引。
9、尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型,这样会降低查询和连接的性能,并且会增加存储的开销。这是因为引擎在处理查询和连接时会逐个比较字符串中每一个字符,而对于数字型来说只需要比较一次就够了。
10、任何地方都不要使用select *,用具体的字段代替‘*’,不要返回用不到的任何字段。
11、使用慢查询来进行数据库的优化。观察到慢查询的最方便途径是(Spring+Druid)可以轻松的实现,可以观察具体哪些sql语句是执行最慢的,之后再对查询进行优化。