今天介绍几个序列函数,NTILE,ROW_NUMBER,RANK,DENSE_RANK,其中 ROW_NUMBER 是现在工作中较常用到的函数,下面会一一解释各自的用途。
数据准备
cookie1,2015-04-10,1 cookie1,2015-04-11,5 cookie1,2015-04-12,7 cookie1,2015-04-13,3 cookie1,2015-04-14,2 cookie1,2015-04-15,4 cookie1,2015-04-16,4 cookie2,2015-04-10,2 cookie2,2015-04-11,3 cookie2,2015-04-12,5 cookie2,2015-04-13,6 cookie2,2015-04-14,3 cookie2,2015-04-15,9 cookie2,2015-04-16,7
建表,导入数据
create table hive.cookie2_sum ( cookieid string, createtime string, pv int ) row format delimited fields terminated by ','; load data local inpath "/home/hadoop/cookie2.txt" into table cookie2; select * from hive.cookie2_sum;
一 、ntile
ntile(n),用于将分组数据按照顺序切分成 n 片,返回当前切片值
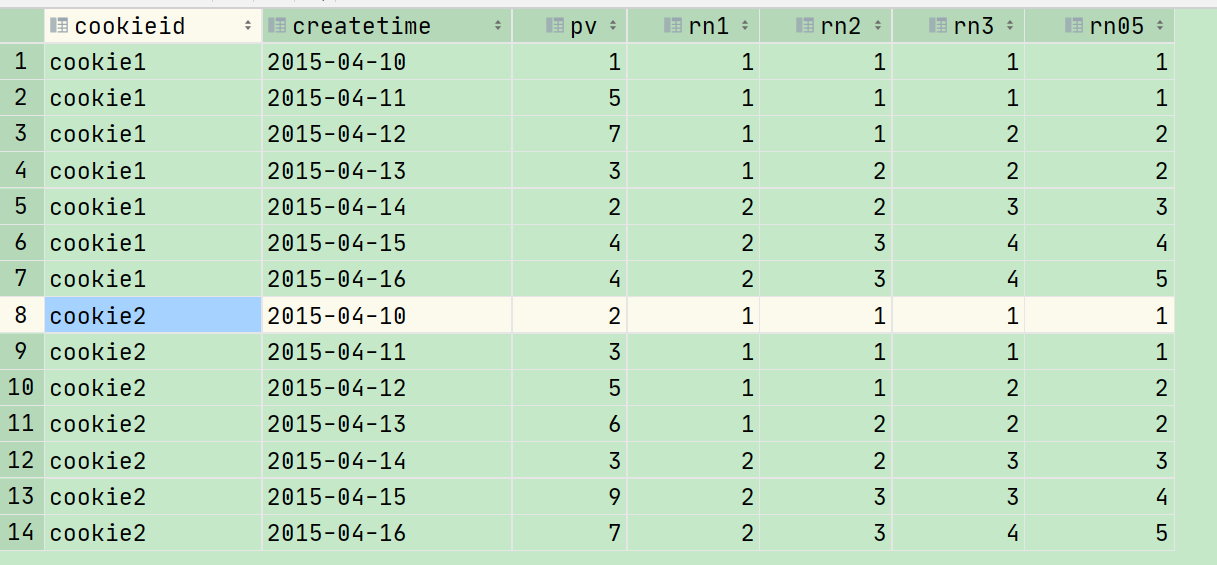
set mapreduce.map.memory.mb=8192; set mapreduce.reduce.memory.mb=8192; select cookieid, createtime, pv, ntile(2) over (partition by cookieid order by createtime) as rn1, --将分组内将数据分成 2 片 ntile(3) over (partition by cookieid order by createtime) as rn2, --将分组内将数据分成 2 片 ntile(4) over (order by createtime) as rn3, --将将所有数据分成 4 片 ntile(5) over (partition by cookieid order by createtime) as rn05 --将分组内将数据分成 5 片 from hive.cookie2_sum order by cookieid, createtime;
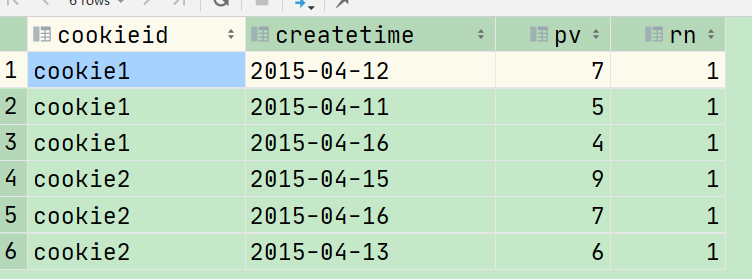
例子,统计一个cookie,pv数最多的前 1/3 的天的数据
select * from (select cookieid, createtime, pv, ntile(3) over (partition by cookieid order by pv desc ) as rn from hive.cookie2_sum) t where rn = 1;
二、row_number
ROW_NUMBER() –从1开始,按照制定排序列和排序规则进行排序,生成分组内记录的序列,比如,按照pv降序排列,生成分组内每天的pv名次
ROW_NUMBER() 的应用场景非常多,再比如,业务数据按 user_id 去重等等。
select cookieid, createtime, pv, row_number() over (partition by cookieid order by pv desc) as rn from hive.cookie2_sum;
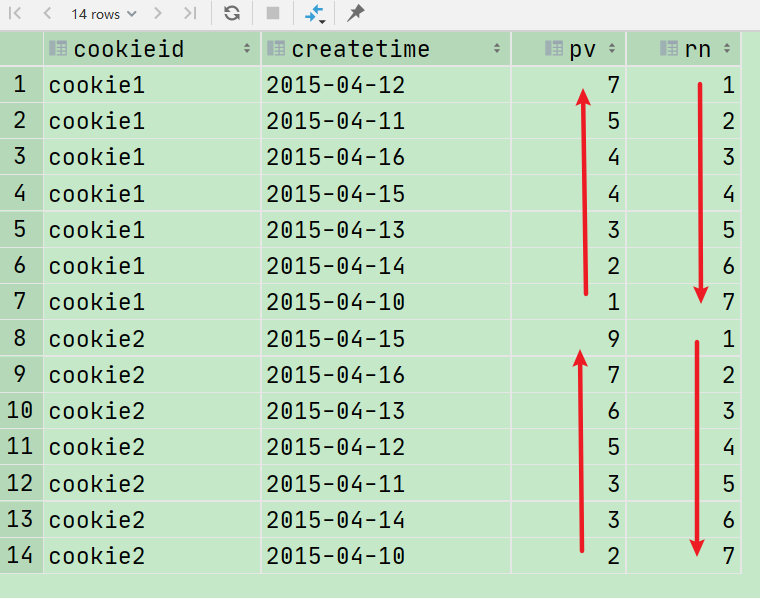
查询结果如上所示,日如果需要自定义限制前几名,可以嵌套子查询在限制一下 rn 的范围即可;
三、rank 和 dense_rank
rank() 生成数据项在分组中的排名,排名相等会在名次中留下空位;
dense_rank() 生成数据项在分组中的排名,排名相等会在名次中不会留下空位;
select cookieid, createtime, pv, rank() over (partition by cookieid order by pv desc) as rank_, dense_rank() over (partition by cookieid order by pv desc) as dense_rank_, row_number() over (partition by cookieid order by pv desc) as row_number_ from hive.cookie2_sum where cookieid = 'cookie2';
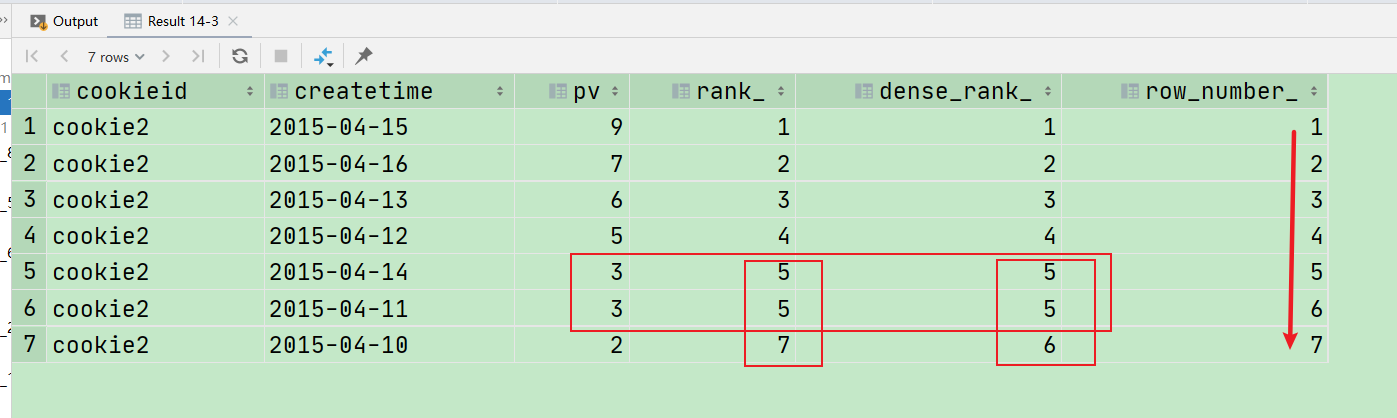
说明:
row_number: 按顺序编号,排序列值相等排序结果不留空位;
rank: 按顺序编号,排序列值相等排序结果同号,留空位;
dense_rank: 按顺序编号,排序列值相等排序结果同号,不留空位;
------------------------------------------------------------------------------------------------------------------------------------------------
下面介绍两个不太常用到的分析函数
数据准备
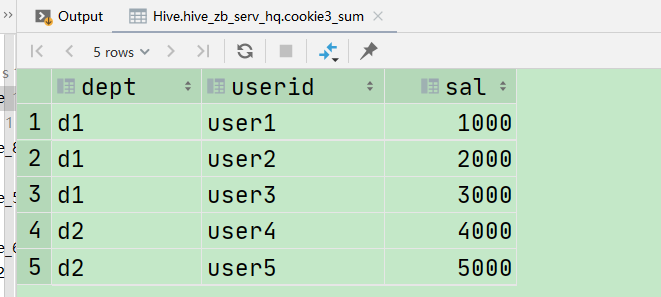
d1,user1,1000 d1,user2,2000 d1,user3,3000 d2,user4,4000 d2,user5,5000
建表
create table hive.cookie3_sum ( dept string, userid string, sal int ) row format delimited fields terminated by ','; select * from hive.cookie3_sum;
cume_dis 小于等于当前值的行数/分组内总行数
select dept, userid, sal, cume_dist() over (order by sal) as rn1, cume_dist() over (partition by dept order by sal) as rn2 from hive.cookie3_sum;
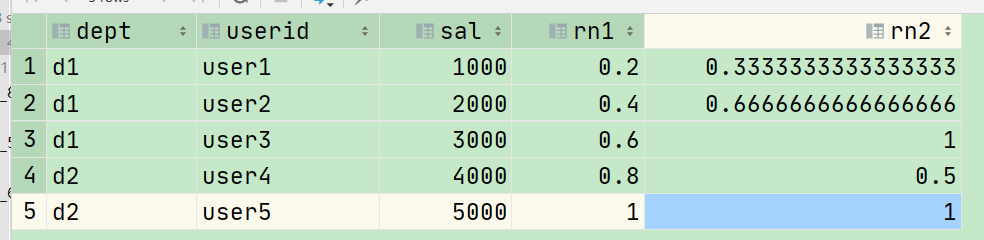
计算逻辑说明:
rn1: 没有partition,所有数据均为1组,总行数为5,5就是那个分母 第一行:小于等于1000的行数为1,因此,1/5=0.2 第二行:小于等于2000的行数为2,因此,2/5=0.4 rn2: 按照部门分组,dpet=d1的行数为3,此时分母为3,当d2 时分母为2 第二行:小于等于2000的行数为2,因此,2/3=0.6666666666666666
percent_rank :分组内当前行的 RANK 值-1/分组内总行数-1
select dept, userid, sal, percent_rank() over (order by sal) as rn1, --分组内 rank() over (order by sal) as rn11, --分组内的rank值 sum(1) over (partition by null) as rn12, --分组内总行数 percent_rank() over (partition by dept order by sal) as rn2, rank() over (partition by dept order by sal) as rn21, sum(1) over (partition by dept) as rn22 from hive.cookie3_sum;

计算逻辑说明:
rn1: rn1 = (rn11-1) / (rn12-1) 第一行,(1-1)/(5-1)=0/4=0 第二行,(2-1)/(5-1)=1/4=0.25 第四行,(4-1)/(5-1)=3/4=0.75 rn2: 按照dept分组, dept=d1的总行数为3 第一行,(1-1)/(3-1)=0 第三行,(3-1)/(3-1)=1