第一步:准备netcat(Linux环境可忽略)
由于本次代码结果的验证是在Windows环境下进行,所以需要安装一下netcat以使用nc命令,netcat的安装方法可参考链接:https://blog.csdn.net/BoomLee/article/details/102563472
第二步:代码
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
object WordCount2 {
def main(args: Array[String]): Unit ={
//创建流处理环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//接收socket文本流
// 127.0.0.1或者IPv4地址均可
val textDstream: DataStream[String] = env.socketTextStream("127.0.0.1", 7777)
//flatMap和Map需要引用的隐式转换
import org.apache.flink.api.scala._
val dataStream: DataStream[(String, Int)] = textDstream.flatMap(_.split(","))
.filter(_.nonEmpty)
.map((_, 1))
.keyBy(0)
.sum(1)
dataStream.print().setParallelism(1) //1代表并行度,不指定则默认为电脑核数
env.execute("Socket stream word count")
}
}
第三步:开启端口(小细节之nc -l和nc -L的区别:大写的L会在IDEA结束代码后继续保持nc命令执行状态,小写的l则会在IDEA结束代码后也结束nc命令)

第四步:执行代码
第五步:检查结果
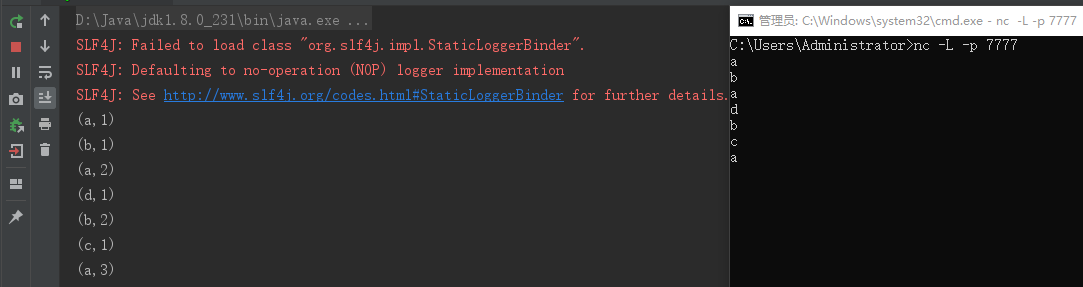
PS:第二步代码实现中也可以采取从外部读入参数的方式,代码如下:

然后在点击Edit Configurations...进行如下配置(注意Flink中参数前面用-或者--,否则会报错:java.lang.IllegalArgumentException Please prefix keys with -- or -.):

有帮助的欢迎评论打赏哈,谢谢!