redis 持久化 交换
什么是持久化: 将数据从掉电易失的内存存放到能够永久存储的设备上
redis持久化方式:RDB(Redis DB) hdfs:fsimage(产生持久化镜像文件,以二进制格式文件的形式存储,对应reids的RDB文件)
AOF(AppendOnlyFile) hdfs: edit logs 关闭 (以客户端向redis发送指令的形式来存储文件 ,对应redis的AOF文件)
RDB: 在默认情况下,redis将数据库快照保存在名字为dump.rdb的二进制文件中
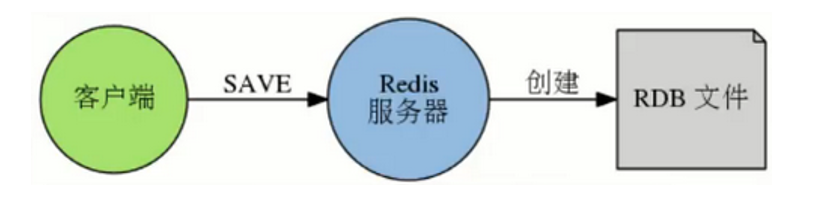
方式: 1、阻塞方式 客户端执行save命令 2、非阻塞方式 bgsave
策略: 自动:按照配置文件中的条件满足就执行BGSAVE
save 60 1000,redis要满足在60秒内至少有1000个键被改动,会自动保存一次
手动:客户端发起save,bgsave
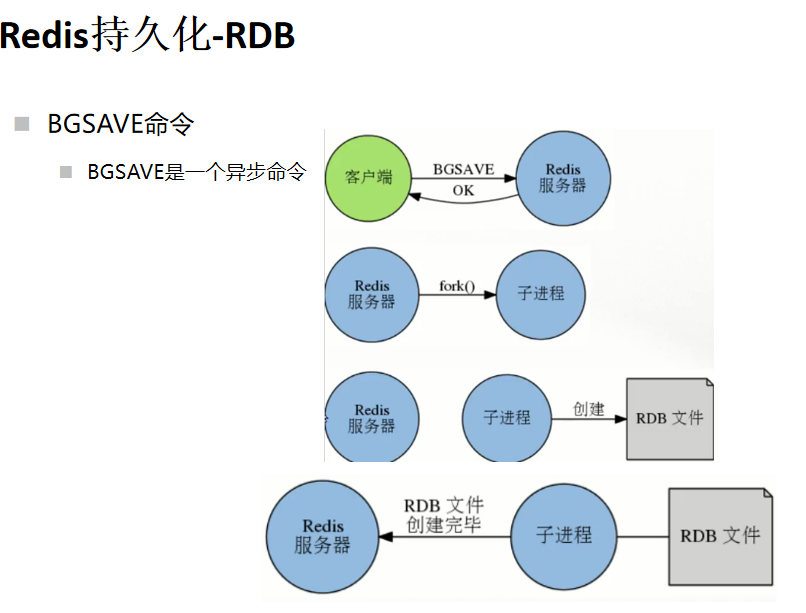
BGSAVE命令:
redis> bgsave
非阻塞,redis服务正常接收处理客户端请求
redis会 fork() 一个新的子进程来创建RDB文件,子进程处理完后,会像父进程发送一个信号,通知它处理完毕
父进程用新的dump.rdb替代旧文件
持久化默认配置:
save 9001
save 300 10
save 10 10000
只要上面三个条件满足一个就会自动执行备份
创建RDB文件之后,时间计数器和次数计数器会清零,所以多个条件的效果不是叠加的
redis持久化的优点和缺点:
优点 1、完全备份,不同时间的数据集备份可以做到多版本恢复
2、紧凑的单一文件,方便网络传输,适合灾难恢复
3、恢复大数据集速度较AOF快
缺点:
1、会丢失最近写入、修改的而未能持久化的数据
2、fork过程非常耗时,会造成毫秒级不能响应客户端请求
AOF写入机制:
AOF不能保证绝对不丢失数据
目前常见的操作系统中,执行系统调用write函数,将一些内容写入到某个文件里面时,为了提高效率,系统通常不会将内容直接写入到硬盘里面。而是现将内容放入一个内存缓冲区中,等到缓冲区被填满,或者用户执行fsync调用和fdatasync调用时才将存储在缓冲区的内容真正写入到硬盘里面,未写入磁盘之前,数据可能会丢失
写入磁盘的策略:
appendfsync选项,这个选项的值可以是always,everysec或者no
always: 服务器没写入一个命令,就调用一次fdatasync,将缓冲区里面的命令写入到硬盘。这种模式下,服务器出现故障,也不会丢失任何已经成功执行的命令 数据
Everysec(默认): 服务器每一秒重调用一次fdatasync,将缓冲区里面的数据写入到硬盘,这种模式下,服务器出现故障,最多只丢失一秒钟内执行的命令数据
NO: 服务器不主动调用fdatasync,由操作系统决定何时将缓冲区里面的命令写入到磁盘。这种模式下,服务器遭遇意外停机时,丢失命令的数量是不确定的
运行速度:always运行速度慢,everysec和no都很快
AOF重写过程:
fork一个子进程负责重写AOF文件
子进程会创建一个临时文件写入AOF信息
父进程会开辟一个内存缓冲区接受新的命令
子进程重写完成之后,父进程会获得一个信号,将进程收到的新的写操作由子进程写入到临时文件之中,新文件替代旧的文件
注:如果写入操作的时候出现故障导致命令写半截,可以使用redis-check-aof工具修复
reids持久化 -AOF 操作
优点: 写入机制,默认fysec每秒执行,性能很好不阻塞服务,最多丢失一秒的数据
重写机制,优化AOF文件
如果误操作了,只要AOF未重写,停止服务移除AOF文件尾部FLUSHALL命令,重启redis,可以将数据集恢复到FLUSHALL执行之前的状态
缺点:
相同的数据集,AOF文件体积较RDB大了很多
恢复数据库速度较RDB慢
开启AOF操作之后,默认不在使用RDB作为备选,但二者任然可以同时开启
搭建集群时需要遵循的原则: CAP原则,指的是在一个分布式系统之中,Consistency(一致性),Availability(可用性),partitiontolerance(分区容错性),三者不可兼得
redis主从复制
一个redis服务可以有多个该服务的复制品,这个redis服务称为master,其他复制品称为slaves
只要网络连接正常,master会一直将自己的数据同步更新给slaves,保持主从同步
只有master可以执行写命令,slaves才可以执行读命令
主从复制创建:
redis-server-slaveof<master-ip> <master-port> ,配置当前服务称为某redis服务的slave
example: #redis-server--port 6308 --slaveof 127.0.0.1 6379
SLAVEOF host port 命令,将当前服务器状态从master修改为别的服务器的slave
redis > SLAVEOF 192.168.1.1. 6379, 将服务器转换为slave
redis > SLAVEOF NO ONE ,将服务器重新恢复到master,不会丢弃已同步数据
配置方式,启动时,服务器读取配置文件,并自动成为指定服务器的从服务器
、slaveof <masterip> <masterport>
slaveof 127.0.0.1 6379
单节点模拟主从架构模式:
手动实现主从模式
1、创建redis 文件夹 在该文件夹下面创建三个子文件夹
2、分别进入这三个文件夹,并在着三个文件夹之中分别启动redis 服务
3、启动redis服务 : redis-server --port 6380 (在第一个文件夹中创建,相当于创建了一个redis实例 )
reids-server --port 6381 --slaveof 127.0.0.1 6380 (在第二个文件夹中创建一个redis实例)
reids-server --port 6382 --slaveof 127.0.0.1 6380 (在第三个文件夹中创建一个redis实例)
启动一个客户端实例: redis-cli -p 6380
插入一条数据验证之前插入的数据,与其他节点的数据是同步的
当主节点初夏故障之后,手动切换主从节点: 在6381客户端输入 SLAVEOF no one 就实现了将6381节点命名为新的注节点
在6382的节点将6382节点切换为6381的从节点: SLAVEOF 127.0.0.1 6381
实现自动切换主从架构:
redis哨兵paxos
监控 monitoring
sentinel会不断检查master和slaves是否正常
每一个sentinel可以同步监控任意多个master和该master 下的slaves
sentinel网络:
监控同一个master的sentinel会自动连接,组成一个分布式sentinel网络,互相通信并交换彼此关于被监控服务器的信息
哨兵一般也以集群的方式来运行
redis哨兵 senlinel配置文件
至少包含一个监控配置选项,用于监控被指定master的相关信息
sentinel monitor<name><ip><port><quorum>,l例如 sentinel monitor mymaster 127.0.0.1 6379 2
监视master的主服务器,服务器ip和端口,将这个主服务器下线失效至少需要2个sentinel同意,如果多数sentinel同意才会执行故障转移
sentinel会根据master的配置自动发现master的slaves
sentiNel默认端口是26279
哨兵的使用方法:(所有的操作都在模拟的单节点上运行)
1、mkdir sent
2、在新建文件夹下创建三个哨兵启动时的启动目录
3、启动文件的名称是固定的 vi s1.conf
在新建文件夹中分别设置哨兵的启动条件:
port 26380 (设置哨兵的启动节点端口号)
sentinel monitor xxx 127.0.0.1 6380 2 (设置哨兵监控的端口号以及某个节点提升为主节点需要的投票数)
cp s1.conf s2.conf cp s1.conf s3.conf
修改每个配置文件中哨兵的端口号
需要将哨兵的启动目录放置到bin目录之下,目的是可以在任意的目录都可以进行启动
4、启动哨兵: 首先进入到节点sent目录下
redis-sentinel s1.conf
redis-sentinel s2.conf
redis-sentinel s3.conf
当主节点当掉之后,会自动选举一个节点作为主节点
redis集群分片
集群将整个数据库分为16384个槽位slot,所有key的数据都是这些slot中的一个,key的槽位计算公式为slot_number = crc16(key)%16384,其中crc16位的循环冗余校验和函数
集群中每个节点都可以处理0个至16383个槽,当16383个槽都有某个节点在负责处理时,集群进入上线状态,并开始处理客户端发送的数据命令请求
每个节点拥有的槽位数量是可以进行自由分配的
用这种方式可以解决数据迁移以及数据倾斜的问题
搭建redis集群:
上传redis 3.0.0.4 版本的安装目录 ,并进行解压
2、对redis安装文件进行编译 make && make PREFIX= /opt/wcg/redis/ install
3、3.0版本和2.8版本的区别在于 服务器启动时即是服务器有事哨兵
4、搭建一个完整的redis集群至少需要六个节点 ,启动之后需要进行区分主从,同时要进行一个槽位的认领
5、安装ruby (脚本)环境,该环境的作用是支持槽位分发 安装ruby环境的命令: yum -y install ruby rubtgems
6、安装gcc 以及tcl 环境
7、redis-cluster 目录下安装 redis gem 模块: # gem install --local redis-3.3.0.gem
8、创建文件夹 redis-test 并创建6个启动文件
9、分别在每个文件下启动redis服务器 (共六个)
10、 完成之后用ruby进行分槽 # ./redis-trib.rb create --replicas 1 127.0.0.1:7000 127.0.0.1:7001
127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005
11、槽位分发完成之后,服务器才算是真正的运作了起来
12、启动客户端集群的命令: redis-cli -p 7000 -c