一、hadoop 序列化与反序列化
Hadoop 通过Writable接口实现序列化机制
Writable 接口中主要有两个方法:
wirte(DataOutput out)
readFields(DataInput in)
对象在实现这个接口时,属性既可以是java 类型的,也可以是 Hadoop类型的。
实现write 方法时:将对象转化为字节流并写入到输出流out中。
如果属性是java类型的,out.write(name);(name 是对象中的一个属性)
如果属性是 Hadoop类型的,name.write(out);
实现readFields时,从输出流中读取字节流并反序列化对象。
java:in.readFields(name)
Hadoop: name.readFields(in)
二、SequenceFile
SequenceFile:Hadoop 可以通过 SequenceFile 对小文件进行合并,获得更高的存储效率。Hadoop提供的SequenceFile文件格式提供一对key,value形式的不可变的数据结构,方便对二进制文件进行处理。二进制文件可以直接将<Key,Value>对序列化到文件中。SequenceFile 中的key 和value 可以是任意类型的Writable 或者自定义的Writable类型。HDFS和MapReduce job使用SequenceFile文件可以使文件的读取更加高效。SequenceFile 内部结构如下: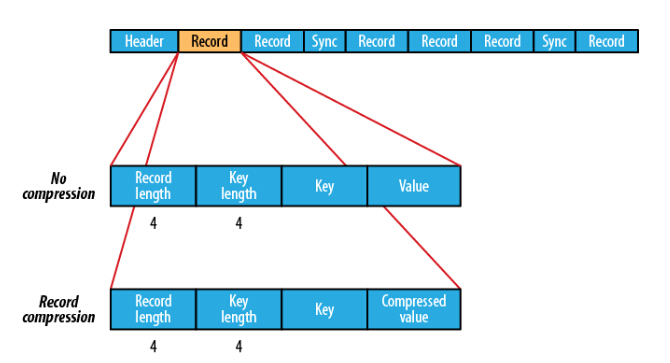
如果没有压缩,每个记录由记录长度(4字节)、键长度(4 字节)、键和值组成,如果启动了压缩,那么value 就是压缩后的值。
SequenceFile 特点:可以定制基于Record(记录)和Block(块)压缩。
Record 针对行压缩,只压缩Value 而不压缩 Key , 而Block 对Key 和 Value 都压缩。
MapFile:MapFiel 是排过序的SequeceFile,由两部分构成,分别是index 和 data,index 作为文件的数据索引,存储了record 的key 值。以及该record 在文件中的偏移位置。在MapFile 被访问的时候,索引文件首先会被加载到内存。通过映射关系可以迅速找到record 所在文件中的位置。MapFile 的检索效率更高,但是要消耗额外的内存来存储index数据。