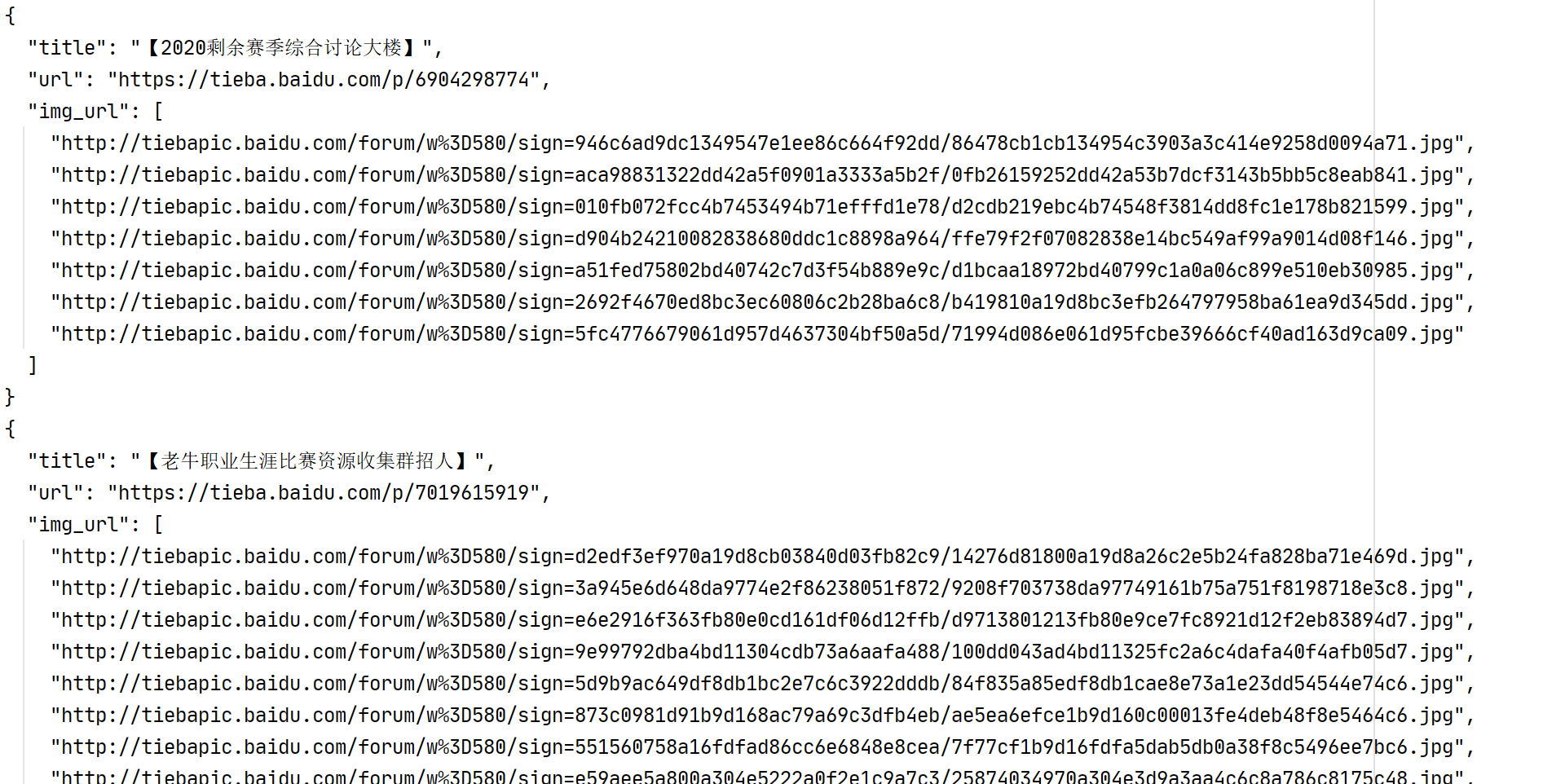
本爬虫以百度贴吧为例,爬取某个贴吧的【所有发言】以及对应发言详情中的【图片链接】
涉及:
- request 发送请求获取响应
- html 取消注释
- 通过xpath提取数据
- 数据保存
思路:
- 由于各贴吧发言的数量不一,因此通过观察url规律统一构造url列表进行遍历爬取,不具有可推广性,因此通过先找到【下一页】url,看某一页是否存在下一页url决定爬虫的停止与否
- 对初始url 进行while True,直到没有下一页url为止
- 发送请求获取响应
- 提取数据(标题列表、url列表、下一页url)
- 遍历url列表
- 对初始url 进行while True,直到没有下一页url为止
- 发送请求获取响应
- 提取数据(image_url_list、下一页url
- 保存数据
- 对初始url 进行while True,直到没有下一页url为止
- 遍历url列表
代码:
1 import requests 2 from lxml import etree 3 import json 4 5 6 class TieBaSpider: 7 def __init__(self): 8 self.proxies = {"http": "http://122.243.12.135:9000"} # 免费ip代理 9 self.start_url = "https://tieba.baidu.com/f?kw={}&ie=utf-8&pn=0" 10 self.headers = { 11 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.k36 (KHTML, like Gecko) " 12 "Chrome/86.0.4240.11"} 13 14 # 发送请求获取响应 15 def parse_url(self, url): 16 res = requests.get(url, headers=self.headers, proxies=self.proxies) 17 html_str = res.content.decode().replace(r"<!--", "''").replace(r"-->", "''") # 去除网页注释 18 19 return html_str 20 21 # 提取外层url内容列表 22 @staticmethod 23 def get_outer_content(html_str): 24 html = etree.HTML(html_str) 25 title_list = html.xpath("//a[@class='j_th_tit ']/text()") 26 url_list = html.xpath("//a[@class='j_th_tit ']/@href") 27 if len(html.xpath("//a[text()='下一页']/@href")) > 0: 28 next_url_outer = html.xpath("//a[text()='下一页'/@href")[0] 29 else: 30 next_url_outer = None 31 32 return title_list, url_list, next_url_outer 33 34 # 提取内层url内容列表 35 @staticmethod 36 def get_inner_content(html_str): 37 html = etree.HTML(html_str) 38 image_list = html.xpath("//img[@class='BDE_Image']/@src") 39 40 if len(html.xpath("//a[text()='下一页']/@href")) > 0: 41 next_url_inner = 'https://tieba.baidu.com' + html.xpath("//a[text()='下一页']/@href")[0] 42 else: 43 next_url_inner = None 44 45 return image_list, next_url_inner 46 47 # 保存数据 48 @staticmethod 49 def save(comment): 50 with open("tb.txt", "a", encoding="utf8") as f: 51 f.write(json.dumps(comment, ensure_ascii=False, indent=2)+" ") 52 53 # 主函数 54 def run(self): 55 # 初始化保存数据的字典 56 comment = {} 57 # 构造 url 58 url = self.start_url.format("费德勒") 59 # 初始化外层循环条件 60 next_url_outer = url 61 while next_url_outer is not None: # 循环外层的每一页 62 html_str = self.parse_url(next_url_outer) # 发送请求,获取响应 63 title_list, url_list, next_url_outer = self.get_outer_content(html_str) # 提取数据(标题,下一页url) 64 i = 0 65 for url_inner in url_list: # 循环外层的某一页 66 image_list_all = [] # 初始化存放img_url的列表 67 url_inner = 'https://tieba.baidu.com' + url_inner # 构建url 68 image_list, next_url_inner = self.get_inner_content(self.parse_url(url_inner)) # 获取数据 69 image_list_all.extend(image_list) 70 71 while next_url_inner is not None: # 循环某一页上的某一个url 72 html_str = self.parse_url(next_url_inner) 73 image_list, next_url_inner = self.get_inner_content(html_str) 74 image_list_all.extend(image_list) 75 76 comment["title"] = title_list[i] 77 comment["url"] = url_inner 78 comment["img_url"] = image_list_all 79 80 self.save(comment) 81 i += 1 82 print("ok") 83 84 85 if __name__ == "__main__": 86 tb = TieBaSpider() 87 tb.run()