import requests
from bs4 import BeautifulSoup
import re
url='http://www.quanjing.com/'
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3253.3 Safari/537.36'}
response=requests.get(url=url,headers=headers)
response.encoding='utf-8'
html=response.text
soup=BeautifulSoup(html,'html.parser')
imgs_src=soup.find_all('img',src=re.compile('^/image/2017index/'))
count=1
for i in imgs_src:
img_src='http://www.quanjing.com'+i['src']
response=requests.get(url=img_src,headers=headers,stream=True)
with open('D:/Python/img/'+str(count)+'.jpg','wb') as f:
#以字节流的方式写入,每128个流遍历一次,完成后为一张照片
for data in response.iter_content(128):
f.write(data)
print('第%d张照片下载完毕
'%count)
count=count+1
print('照片下载完毕')
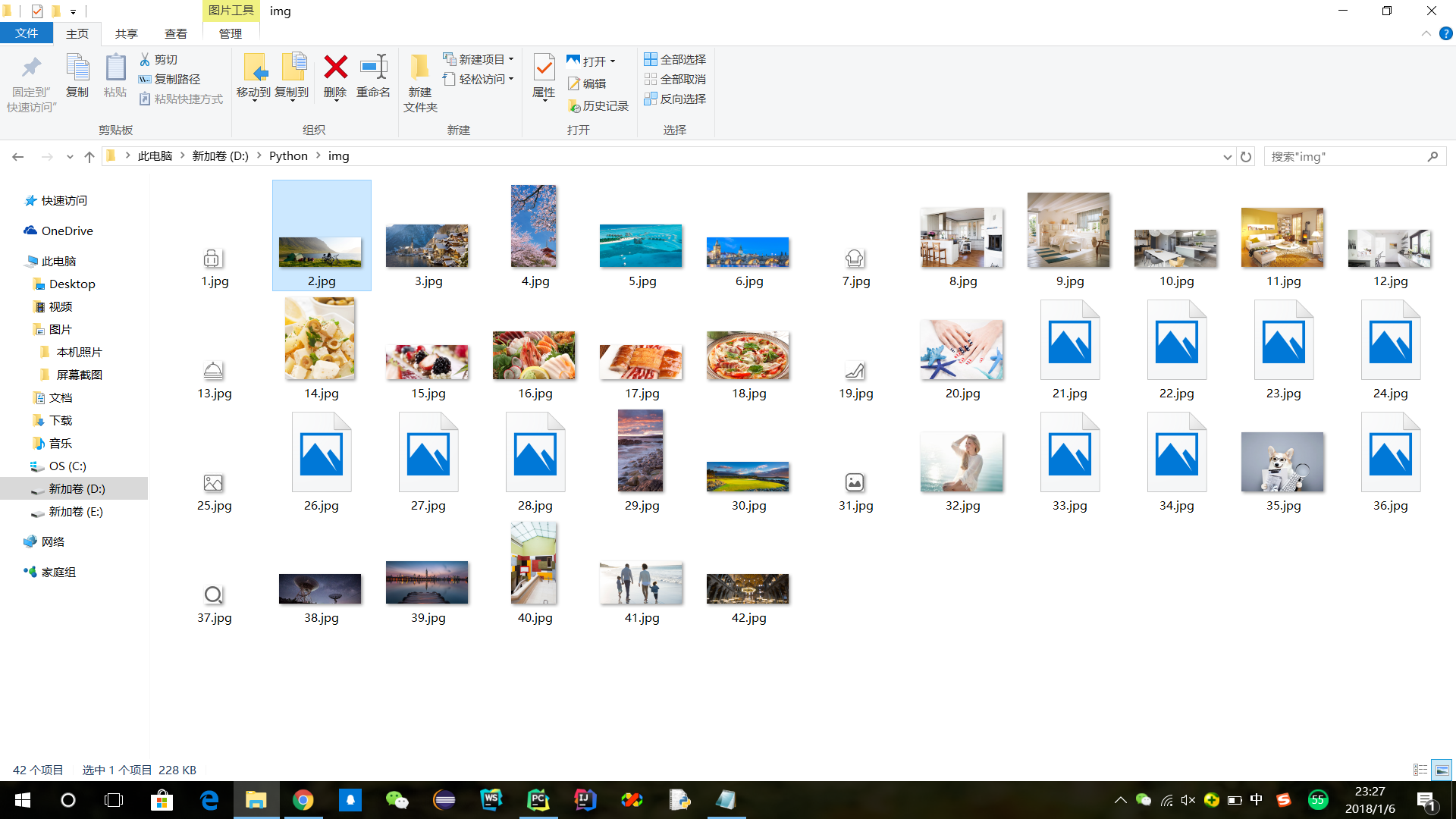
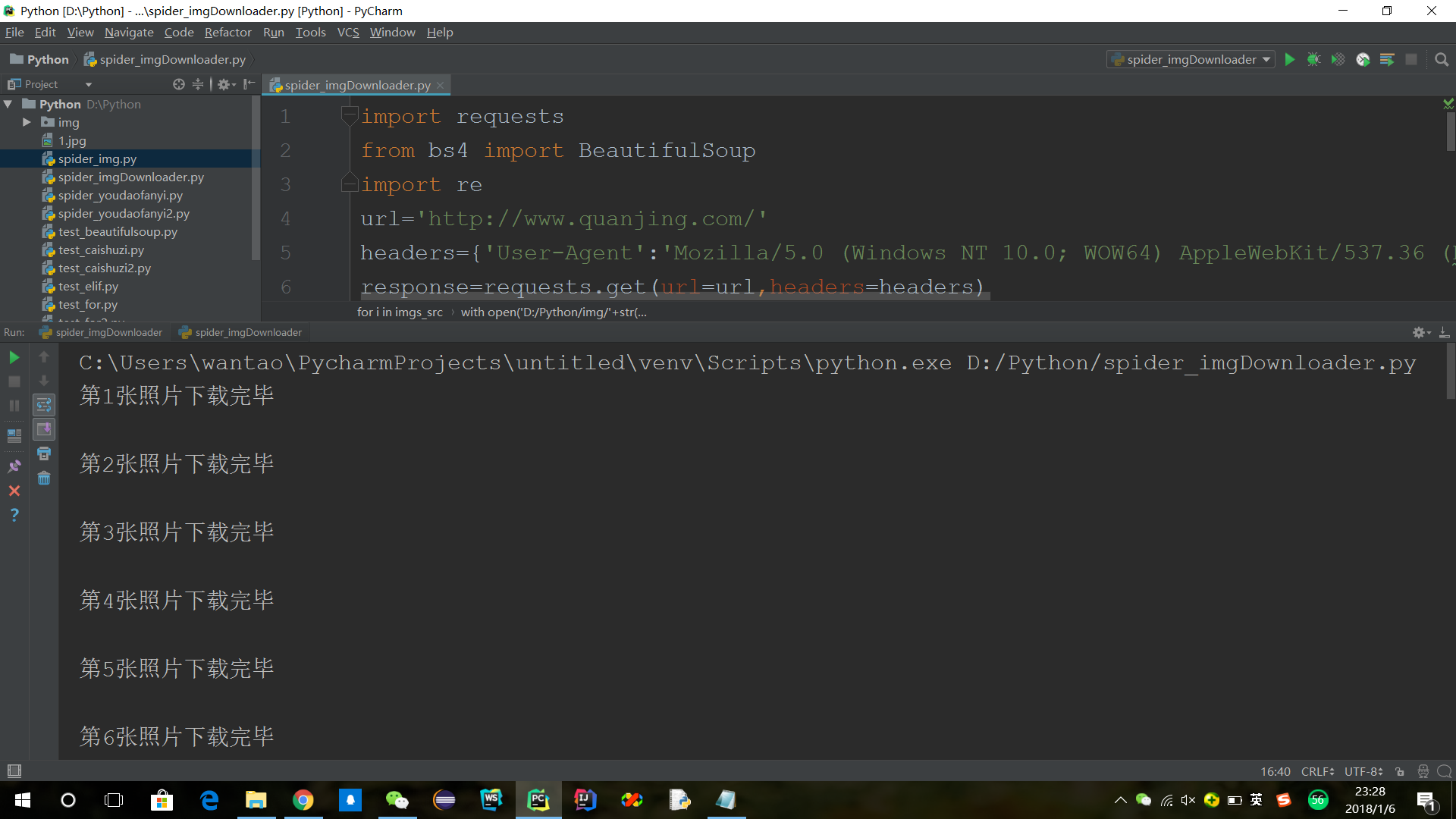
出现的两个问题:
1.字符串与int型不能直接拼接,需要拼接前通过str()将int型转成str
2.下载照片时,图片时二进制文件,使用字节流将文件写入