1、激活函数
激活函数(activation function)运行时激活神经网络中某一部分神经元,将激活信息向后传入下一层的神经网络。神经网络之所以能解决非线性问题(如语音、图像识别),本质上就是激活函数加入了非线性因素,弥补了线性模型的表达力,把“激活的神经元的特征”通过函数保留并映射到下一层。
因为神经网络的数学基础是处处可微的,所以选取的激活函数要能保证数据输入与输出也
是可微的。那么激活函数在 TensorFlow 中是如何表达的呢?
激活函数不会更改输入数据的维度,也就是输入和输出的维度是相同的。TensorFlow 中有
如下激活函数,它们定义在 tensorflow-1.1.0/tensorflow/python/ops/nn.py 文件中,这里包括平滑
非线性的激活函数,如 sigmoid、tanh、elu、softplus 和 softsign,也包括连续但不是处处可微的
函数 relu、relu6、crelu 和 relu_x,以及随机正则化函数 dropout:
1 tf.nn.relu() 2 tf.nn.sigmoid() 3 tf.nn.tanh() 4 tf.nn.elu() 5 tf.nn.bias_add() 6 tf.nn.crelu() 7 tf.nn.relu6() 8 tf.nn.softplus() 9 tf.nn.softsign() 10 tf.nn.dropout()#防止过拟合,用来舍弃某些神经元
上述激活函数的输入均为要计算的 x(一个张量),输出均为与 x 数据类型相同的张量。
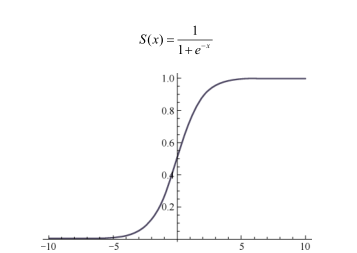
1.1、Sigmoid函数:
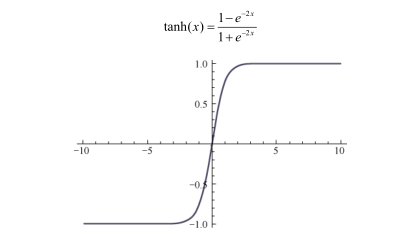
1.2、tanh函数:
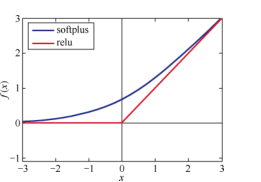
1.3、relu函数:and softplus函数:
2、卷积函数:
卷积函数定义在 tensorflow-1.1.0/tensorflow/python/ops 下的 nn_impl.py 和
nn_ops.py 文件中。
1 tf.nn.convolution(input, filter, padding, strides=None,dilation_rate=None, name=None, data_format=None) 2 tf.nn.conv2d(input, filter, strides, padding, use_cudnn_on_gpu=None,data_format= None, name=None) 3 tf.nn.depthwise_conv2d (input, filter, strides, padding, rate=None, name=None,data_format=None) 4 tf.nn.separable_conv2d (input, depthwise_filter, pointwise_filter, strides, padding,rate=None, name=None, data_format=None) 5 tf.nn.atrous_conv2d(value, filters, rate, padding, name=None) 6 tf.nn.conv2d_transpose(value, filter, output_shape, strides, padding='SAME',data_format='NHWC', name=None) 7 tf.nn.conv1d(value, filters, stride, padding, use_cudnn_on_gpu=None,data_format= None, name=None) 8 tf.nn.conv3d(input, filter, strides, padding, name=None) 9 tf.nn.conv3d_transpose(value, filter, output_shape, strides, padding='SAME',name=None)
(1)tf.nn.convolution(input, filter, padding, strides=None, dilation_rate=None, name=None,
data_format =None)这个函数计算 N 维卷积的和。
(2)tf.nn.conv2d(input, filter, strides, padding, use_cudnn_on_gpu=None, data_format=None,
name=None)这个函数的作用是对一个四维的输入数据 input 和四维的卷积核 filter 进行操作,然
后对输入数据进行一个二维的卷积操作,最后得到卷积之后的结果。
def conv2d(input, filter, strides, padding, use_cudnn_on_gpu=None,data_format=None, name=None) # 输入: # input:一个 Tensor。数据类型必须是 float32 或者 float64 # filter:一个 Tensor。数据类型必须是 input 相同 # strides:一个长度是 4 的一维整数类型数组,每一维度对应的是 input 中每一维的对应移动步数, # 比如,strides[1]对应 input[1]的移动步数 # padding:一个字符串,取值为 SAME 或者 VALID # padding='SAME':仅适用于全尺寸操作,即输入数据维度和输出数据维度相同 # padding='VALID:适用于部分窗口,即输入数据维度和输出数据维度不同 # use_cudnn_on_gpu:一个可选布尔值,默认情况下是 True # name:(可选)为这个操作取一个名字 # 输出:一个 Tensor,数据类型是 input 相同 事例; input_data = tf.Variable( np.random.rand(10,9,9,3), dtype = np.float32 ) filter_data = tf.Variable( np.random.rand(2, 2, 3, 2), dtype = np.float32) y = tf.nn.conv2d(input_data, filter_data, strides = [1, 1, 1, 1], padding = 'SAME')
打印出 tf.shape(y)的结果是[10 9 9 2]。
(3)tf.nn.depthwise_conv2d (input, filter, strides, padding, rate=None, name=None,data_format=
None) 这个函数输入张量的数据维度是[batch, in_height, in_width, in_channels],卷积核的维度是
[filter_height, filter_width, in_channels, channel_multiplier],在通道 in_channels 上面的卷积深度是
1,depthwise_conv2d 函数将不同的卷积核独立地应用在 in_channels 的每个通道上(从通道 1
到通道 channel_multiplier),然后把所以的结果进行汇总。最后输出通道的总数是 in_channels *
channel_multiplier。
input_data = tf.Variable( np.random.rand(10, 9, 9, 3), dtype = np.float32 ) filter_data = tf.Variable( np.random.rand(2, 2, 3, 5), dtype = np.float32) y = tf.nn.depthwise_conv2d(input_data, filter_data, strides = [1, 1, 1, 1], padding = 'SAME') 这里打印出 tf.shape(y)的结果是[10 9 9 15]。
(4)tf.nn.separable_conv2d (input, depthwise_filter, pointwise_filter, strides, padding, rate=None,
name=None, data_format=None)是利用几个分离的卷积核去做卷积。在这个 API 中,将应用一个
二维的卷积核,在每个通道上,以深度 channel_multiplier 进行卷积。
1 def separable_conv2d (input, depthwise_filter, pointwise_filter, strides, padding, 2 rate=None, name=None, data_format=None) 3 # 特殊参数: 4 # depthwise_filter:一个张量。数据维度是四维[filter_height, filter_width, in_channels, 5 # channel_multiplier]。其中,in_channels 的卷积深度是 1 6 # pointwise_filter:一个张量。数据维度是四维[1, 1, channel_multiplier * in_channels, 7 # out_channels]。其中,pointwise_filter 是在 depthwise_filter 卷积之后的混合卷积 8 使用示例如下: 9 input_data = tf.Variable( np.random.rand(10, 9, 9, 3), dtype = np.float32 ) 10 depthwise_filter = tf.Variable( np.random.rand(2, 2, 3, 5), dtype = np.float32) 11 pointwise_filter = tf.Variable( np.random.rand(1, 1, 15, 20), dtype = np.float32) 12 # out_channels >= channel_multiplier * in_channels 13 y = tf.nn.separable_conv2d(input_data, depthwise_filter, pointwise_filter,strides = [1, 1, 1, 1], padding = 'SAME') 14 15 这里打印出 tf.shape(y)的结果是[10 9 9 20]。
(5)tf.nn.atrous_conv2d(value, filters, rate, padding, name=None)计算 Atrous 卷积,又称孔卷
积或者扩张卷积。
使用示例如下:
1 input_data = tf.Variable( np.random.rand(1,5,5,1), dtype = np.float32 ) 2 filters = tf.Variable( np.random.rand(3,3,1,1), dtype = np.float32) 3 y = tf.nn.atrous_conv2d(input_data, filters, 2, padding='SAME') 4 5 这里打印出 tf.shape(y)的结果是[1 5 5 1]。
(6)tf.nn.conv2d_transpose(value, filter, output_shape, strides, padding='SAME', data_format='NHWC',
name=None)
① 在解卷积网络(deconvolutional network)中有时称为“反卷积”,但实际上是 conv2d
的转置,而不是实际的反卷积。
1 def conv2d_transpose(value, filter, output_shape, strides, padding='SAME', 2 data_format='NHWC', name=None) 3 # 特殊参数: 4 # output_shape:一维的张量,表示反卷积运算后输出的形状 5 # 输出:和 value 一样维度的 Tensor 6 使用示例如下: 7 x = tf.random_normal(shape=[1,3,3,1]) 8 kernel = tf.random_normal(shape=[2,2,3,1]) 9 y = tf.nn.conv2d_transpose(x,kernel,output_shape=[1,5,5,3],strides=[1,2,2,1],padding="SAME") 10 11 这里打印出 tf.shape(y)的结果是[1 5 5 3]。
(7)tf.nn.conv1d(value, filters, stride, padding, use_cudnn_on_gpu=None, data_format=None,
name=None)和二维卷积类似。这个函数是用来计算给定三维的输入和过滤器的情况下的一维卷
积。不同的是,它的输入是三维,如[batch, in_width, in_channels]。卷积核的维度也是三维,少
了一维 filter_height,如 [filter_width, in_channels, out_channels]。stride 是一个正整数,代表卷积
核向右移动每一步的长度。
(8)tf.nn.conv3d(input, filter, strides, padding, name=None)和二维卷积类似。这个函数用来计
算给定五维的输入和过滤器的情况下的三维卷积。和二维卷积相对比:
● input 的 shape 中多了一维 in_depth,形状为 Shape[batch, in_depth, in_height,in_width,in_channels];
● filter 的 shape 中多了一维 filter_depth,由 filter_depth, filter_height, filter_width 构成了卷
积核的大小;
● strides 中多了一维,变为[strides_batch, strides_depth, strides_height, strides_width,
strides_channel],必须保证 strides[0] = strides[4] = 1。
(9)tf.nn.conv3d_transpose(value, filter, output_shape, strides, padding='SAME', name=None)
和二维反卷积类似,不再赘述。
3、池化函数
在神经网络中,池化函数一般跟在卷积函数的下一层,它们也被定义在 tensorflow-1.1.0/
tensorflow/python/ops 下的 nn.py 和 gen_nn_ops.py 文件中。
1 tf.nn.avg_pool(value, ksize, strides, padding, data_format='NHWC', name=None) 2 tf.nn.max_pool(value, ksize, strides, padding, data_format='NHWC', name=None) 3 tf.nn.max_pool_with_argmax(input, ksize, strides, padding, Targmax=None, name=None) 4 tf.nn.avg_pool3d(input, ksize, strides, padding, name=None) 5 tf.nn.max_pool3d(input, ksize, strides, padding, name=None) 6 tf.nn.fractional_avg_pool(value, pooling_ratio, pseudo_random=None, overlapping=None, 7 deterministic=None, seed=None, seed2=None, name=None) 8 tf.nn.fractional_max_pool(value, pooling_ratio, pseudo_random=None, overlapping=None, 9 deterministic=None, seed=None, seed2=None, name=None) 10 tf.nn.pool(input, window_shape, pooling_type, padding, dilation_rate=None, strides=None, 11 name=None, data_format=None)
池化操作是利用一个矩阵窗口在张量上进行扫描,将每个矩阵窗口中的值通过取最大值或
平均值来减少元素个数。每个池化操作的矩阵窗口大小是由 ksize 指定的,并且根据步长 strides
决定移动步长。下面就分别来说明
(1)tf.nn.avg_pool(value, ksize, strides, padding, data_format='NHWC', name=None)。这个函
数计算池化区域中元素的平均值。
1 def avg_pool(value, ksize, strides, padding, data_format='NHWC', name=None) 2 # 输入: 3 # value:一个四维的张量。数据维度是[batch, height, width, channels] 4 # ksize:一个长度不小于 4 的整型数组。每一位上的值对应于输入数据张量中每一维的窗口对应值 5 # strides:一个长度不小于 4 的整型数组。该参数指定滑动窗口在输入数据张量每一维上的步长 6 # padding:一个字符串,取值为 SAME 或者 VALID 7 # data_format: 'NHWC'代表输入张量维度的顺序,N 为个数,H 为高度,W 为宽度,C 为通道数(RGB 三 8 # 通道或者灰度单通道) 9 # name(可选):为这个操作取一个名字 10 # 输出:一个张量,数据类型和 value 相同 11 12 13 使用示例如下: 14 15 input_data = tf.Variable( np.random.rand(10,6,6,3), dtype = np.float32 ) 16 filter_data = tf.Variable( np.random.rand(2, 2, 3, 10), dtype = np.float32) 17 y = tf.nn.conv2d(input_data, filter_data, strides = [1, 1, 1, 1], padding = 'SAME') 18 output = tf.nn.avg_pool(value = y, ksize = [1, 2, 2, 1], strides = [1, 1, 1, 1], 19 padding ='SAME') 20 上述代码打印出 tf.shape(output)的结果是[10 6 6 10]。计算输出维度的方法是:shape(output) = 21 (shape(value) - ksize + 1) / strides。
(2)tf.nn.max_pool(value, ksize, strides, padding, data_format='NHWC', name=None)。这个函
数是计算池化区域中元素的最大值。
1 input_data = tf.Variable( np.random.rand(10,6,6,3), dtype = np.float32 ) 2 filter_data = tf.Variable( np.random.rand(2, 2, 3, 10), dtype = np.float32) 3 y = tf.nn.conv2d(input_data, filter_data, strides = [1, 1, 1, 1], padding = 'SAME') 4 output = tf.nn.max_pool(value = y, ksize = [1, 2, 2, 1], strides = [1, 1, 1, 1], 5 padding ='SAME') 6 7 上述代码打印出 tf.shape(output)的结果是[10 6 6 10]。
(3)tf.nn.max_pool_with_argmax(input, ksize, strides, padding, Targmax = None, name=None)。
这个函数的作用是计算池化区域中元素的最大值和该最大值所在的位置。
在计算位置 argmax 的时候,我们将 input 铺平了进行计算,所以,如果 input = [b, y, x, c],
那么索引位置是(( b * height + y) * width + x) * channels + c。
使用示例如下,该函数只能在 GPU 下运行,在 CPU 下没有对应的函数实现
1 input_data = tf.Variable( np.random.rand(10,6,6,3), dtype = tf.float32 ) 2 filter_data = tf.Variable( np.random.rand(2, 2, 3, 10), dtype = np.float32) 3 y = tf.nn.conv2d(input_data, filter_data, strides = [1, 1, 1, 1], padding = 'SAME') 4 output, argmax = tf.nn.max_pool_with_argmax(input = y, ksize = [1, 2, 2, 1], 5 strides = [1, 1, 1, 1], padding = 'SAME')
返回结果是一个张量组成的元组(output, argmax),output 表示池化区域的最大值;argmax
的数据类型是 Targmax,维度是四维。
(4)tf.nn.avg_pool3d()和 tf.nn.max_pool3d()分别是在三维下的平均池化和最大池化。
(5)tf.nn.fractional_avg_pool()和tf.nn.fractional_max_pool()分别是在三维下的平均池化和最大池化。
(6)tf.nn.pool(input, window_shape, pooling_type, padding, dilation_rate=None, strides=None,
name=None, data_format=None)。这个函数执行一个 N 维的池化操作。
4、分类函数:
TensorFlow 中常见的分类函数主要有sigmoid_cross_entropy_with_logits、softmax、log_softmax、softmax_cross_entropy_with_logits 等,它们也主要定义在 tensorflow-1.1.0/tensorflow/python/ops 的nn.py 和 nn_ops.py 文件中。
1 tf.nn.sigmoid_cross_entropy_with_logits(logits, targets, name=None) 2 tf.nn.softmax(logits, dim=-1, name=None) 3 tf.nn.log_softmax(logits, dim=-1, name=None) 4 tf.nn.softmax_cross_entropy_with_logits(logits, labels, dim=-1, name=None) 5 tf.nn.sparse_softmax_cross_entropy_with_logits(logits, labels, name=None)
(1)tf.nn.sigmoid_cross_entropy_with_logits(logits, targets, name=None):
1 def sigmoid_cross_entropy_with_logits(logits, targets, name=None): 2 # 输入:logits:[batch_size, num_classes],targets:[batch_size, size].logits 用最后一 3 # 层的输入即可 4 # 最后一层不需要进行 sigmoid 运算,此函数内部进行了 sigmoid 操作 5 # 输出:loss [batch_size, num_classes]
这个函数的输入要格外注意,如果采用此函数作为损失函数,在神经网络的最后一层不需
要进行 sigmoid 运算。
(2)tf.nn.softmax(logits, dim=-1, name=None)计算Softmax 激活,也就是 softmax = exp(logits) /
reduce_sum(exp(logits), dim)。
(3)tf.nn.log_softmax(logits, dim=-1, name=None)计算 log softmax 激活,也就是 logsoftmax =
logits - log(reduce_sum(exp(logits), dim))。
(4)tf.nn.softmax_cross_entropy_with_logits(_sentinel=None, labels=None, logits=None, dim=-1,
name =None):
1 def softmax_cross_entropy_with_logits(logits, targets, dim=-1, name=None): 2 # 输入:logits and labels 均为[batch_size, num_classes] 3 # 输出: loss:[batch_size], 里面保存的是 batch 中每个样本的交叉熵
(5)tf.nn.sparse_softmax_cross_entropy_with_logits(logits, labels, name=None) :
1 def sparse_softmax_cross_entropy_with_logits(logits, labels, name=None): 2 # logits 是神经网络最后一层的结果 3 # 输入:logits: [batch_size, num_classes] labels: [batch_size],必须在[0, num_classes] 4 # 输出:loss [batch_size],里面保存是 batch 中每个样本的交叉熵
5、优化方法:
TensorFlow 提供了很多优化器(optimizer),我们重点介绍下面这 8 个:
1 class tf.train.GradientDescentOptimizer 2 class tf.train.AdadeltaOptimizer 3 class tf.train.AdagradOptimizer 4 class tf.train.AdagradDAOptimizer 5 class tf.train.MomentumOptimizer 6 class tf.train.AdamOptimizer 7 class tf.train.FtrlOptimizer 8 class tf.train.RMSPropOptimizer
这 8 个优化器对应 8 种优化方法,分别是梯度下降法(BGD 和 SGD)、Adadelta 法、Adagrad
法(Adagrad 和 AdagradDAO)、Momentum 法(Momentum 和 Nesterov Momentum)、Adam、
Ftrl 法和 RMSProp 法,其中 BGD、SGD、Momentum 和 Nesterov Momentum 是手动指定学习
率的,其余算法能够自动调节学习率。
(1)BGD 法
BGD 的全称是 batch gradient descent,即批梯度下降。这种方法是利用现有参数对训练集
中的每一个输入生成一个估计输出 y i ,然后跟实际输出 y i 比较,统计所有误差,求平均以后得
到平均误差,以此作为更新参数的依据。它的迭代过程为:
(1)提取训练集中的所有内容{x 1 , …, x n },以及相关的输出 y i ;
(2)计算梯度和误差并更新参数。
这种方法的优点是,使用所有训练数据计算,能够保证收敛,并且不需要逐渐减少学习率;
缺点是,每一步都需要使用所有的训练数据,随着训练的进行,速度会越来越慢。
那么,如果将训练数据拆分成一个个批次(batch),每次抽取一批数据来更新参数,是不
是会加速训练呢?这就是最常用的 SGD。
2.SGD 法
SGD 的全称是 stochastic gradient descent,即随机梯度下降。因为这种方法的主要思想是将
数据集拆分成一个个批次(batch),随机抽取一个批次来计算并更新参数,所以也称为 MBGD
(minibatch gradient descent)。
SGD 在每一次迭代计算 mini-batch 的梯度,然后对参数进行更新。与 BGD 相比,SGD 在
训练数据集很大时,仍能以较很的速度收敛。但是,它仍然会有下面两个缺点。
(1)由于抽取不可避免地梯度会有误差,需要手动调整学习率(learning rate),但是选择
合适的学习率又比较困难。尤其在训练时,我们常常想对常出现的特征更新速度很一些,而对
不常出现的特征更新速度慢一些,而 SGD 在更新参数时对所有参数采用一样的学习率,因此无法满足要求。
(2)SGD 容易收敛到局部最优,并且在某些情况下可能被困在鞍点。
为了解决学习率固定的问题,又引入了 Momentum 法。
3.Momentum 法
Momentum 是模拟物理学中动量的概念,更新时在一定程度上保留之前的更新方向,利用
当前的批次再微调本次的更新参数,因此引入了一个新的变量 v(速度),作为前几次梯度的累
加。因此,Momentum 能够更新学习率,在下降初期,前后梯度方向一致时,能够加速学习;
在下降的中后期,在局部最小值的附近来回震荡时,能够抑制震荡,加很收敛。
4.Nesterov Momentum 法
Nesterov Momentum 法由Ilya Sutskever 在Nesterov 工作的启发下提出的,是对传统Momentum
法的一项改进,其基本思路如图

标准 Momentum 法首先计算一个梯度(短的 1 号线),然后在加速更新梯度的方向进行一
个大的跳跃(长的 1 号线);Nesterov 项首先在原来加速的梯度方向进行一个大的跳跃(2 号线),
然后在该位置计算梯度值(3 号线),然后用这个梯度值修正最终的更新方向(4 号线)。
上面介绍的优化方法都需要我们自己设定学习率,接下来介绍几种自适应学习率的优化
方法。
5.Adagrad 法
Adagrad 法能够自适应地为各个参数分配不同的学习率,能够控制每个维度的梯度方向。
这种方法的优点是能够实现学习率的自动更改:如果本次更新时梯度大,学习率就衰减得很一
些;如果这次更新时梯度小,学习率衰减得就慢一些。
6.Adadelta 法
Adagrad 法仍然存在一些问题:其学习率单调递减,在训练的后期学习率非常小,并且需
要手动设置一个全局的初始学习率。Adadelta 法用一阶的方法,近似模拟二阶牛顿法,解决了
这些问题。
7.RMSprop 法
RMSProp 法与 Momentum 法类似,通过引入一个衰减系数,使每一回合都衰减一定比例。
在实践中,对循环神经网络(RNN)效果很好。
8.Adam 法
Adam 的名称来源于自适应矩估计
① (adaptive moment estimation)。Adam 法根据损失函数
针对每个参数的梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。
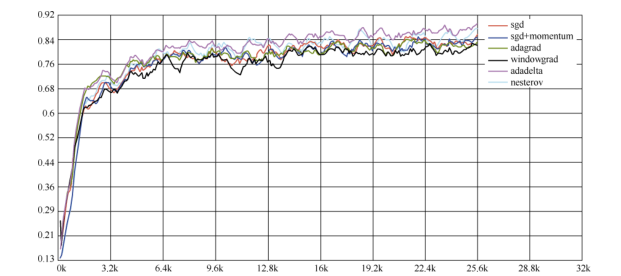
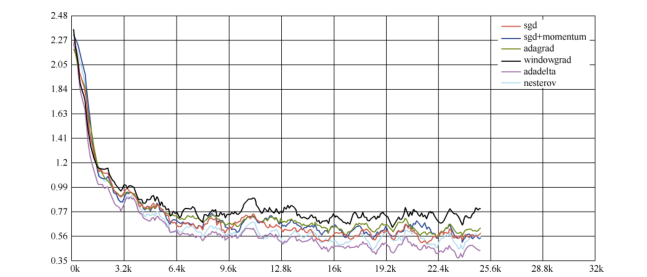
9.各个方法的比较
Karpathy 在 MNIST 数据集上用上述几个优化器做了一些性能比较,发现如下规律
② :在不
怎么调整参数的情况下,Adagrad 法比 SGD 法和 Momentum 法更稳定,性能更优;精调参数的
情况下,精调的 SGD 法和 Momentum 法在收敛速度和准确性上要优于 Adagrad 法。
各个优化器的损失值比较结果如图
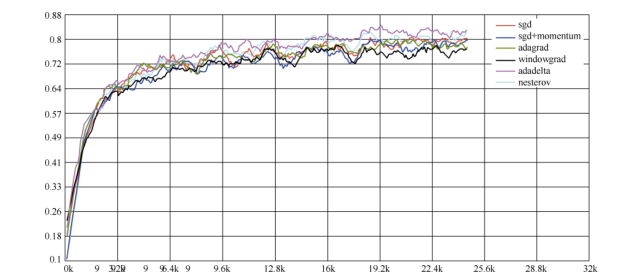
各个优化器的测试准确率比较如图
各个优化器的训练准确率比较如图