这几天在扩大之前搭建的hadoop集群,我利用slave1节点创建其镜像,然后再使用该镜像创建两个新的实例,这样就免去了重新安装配置软件相关项的问题,方便省事。下面是一些添加节点步骤:
1.创建好两个新的实例后,首先要保证master可以ping通新节点,可以实现ssh免密登录。
2.然后修改各个节点的 /etc/hosts文件,把新节点的ip和主机名的映射添加进去。注意:是每个节点都要添加和更改,不管namenode还是datanode节点,不管是原先的还是新添加的节点。新节点也要把原先节点的ip和主机名的映射添加进去。保证各个节点的/etc/hosts文件是完全相同的。
3.这一点是最重要的,也是我决定写这篇博客的原因,这个问题困扰我一天才解决。添加完新节点后,start-dfs.sh启动hadoop集群,使用jps命令,发现两个新节点没有DataNode,而且50070 web页面上也没有显示新节点的信息。
查看新节点的log日志,问题如下:打马赛克的地方都是IP地址
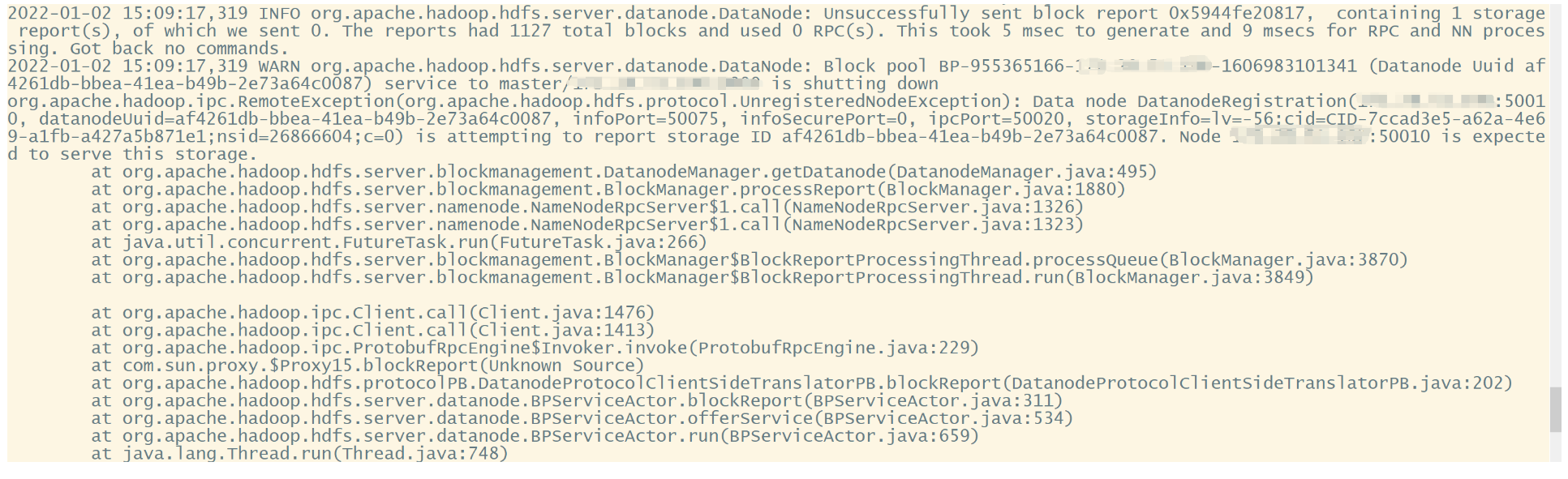 猜测是storage id出错了,应该是我创建镜像的时候,没删掉这个data。
猜测是storage id出错了,应该是我创建镜像的时候,没删掉这个data。
于是找到datanode的data文件夹,删除current文件夹,重新启动hadoop集群。
# 这个路径不是固定的,改成自己的
hadoop@slave6:cd /usr/local/hadoop/tmp/dfs/data/
hadoop@slave6:ll -h
total 16K
drwx------ 3 hadoop hadoop 4.0K Jan 2 16:11 ./
drwxrwxr-x 3 hadoop hadoop 4.0K Dec 3 2020 ../
drwxrwxr-x 3 hadoop hadoop 4.0K Jan 2 16:11 current/
-rw-rw-r-- 1 hadoop hadoop 11 Jan 2 16:11 in_use.lock
# VERSION中有storage id,发现新节点和slave1节点的storage id相同,因为我使用slave1的镜像创建的新的实例,问题就#出在这儿
hadoop@slave6:cd current/
total 16K
drwxrwxr-x 3 hadoop hadoop 4.0K Dec 3 2020 ./
drwx------ 3 hadoop hadoop 4.0K Jan 2 15:09 ../
drwx------ 4 hadoop hadoop 4.0K Jan 2 15:09 BP-955365166-172.28.51.190-1606983101341/
-rw-rw-r-- 1 hadoop hadoop 229 Jan 2 15:09 VERSION
hadoop@slave6:/usr/local/hadoop/tmp/dfs/data$ rm -rf ./current/
hadoop@slave6:/usr/local/hadoop/tmp/dfs/data/current$ jps
3139 DataNode
3221 Jps
在master节点重新启动hadoop集群,发现问题就解决了,而且50070这个web页面上也出现了新节点的信息。
参考链接:
(148条消息) Datanode没起来,报错RemoteException(org.apache.hadoop.hdfs.protocol.UnregisteredNodeException)的解决方案..._weixin_34167043的博客-CSDN博客