之前学习spark,最近需要在k8s集群上提交spark应用,学习过程中,记录了以下几点
1.k8s集群架构
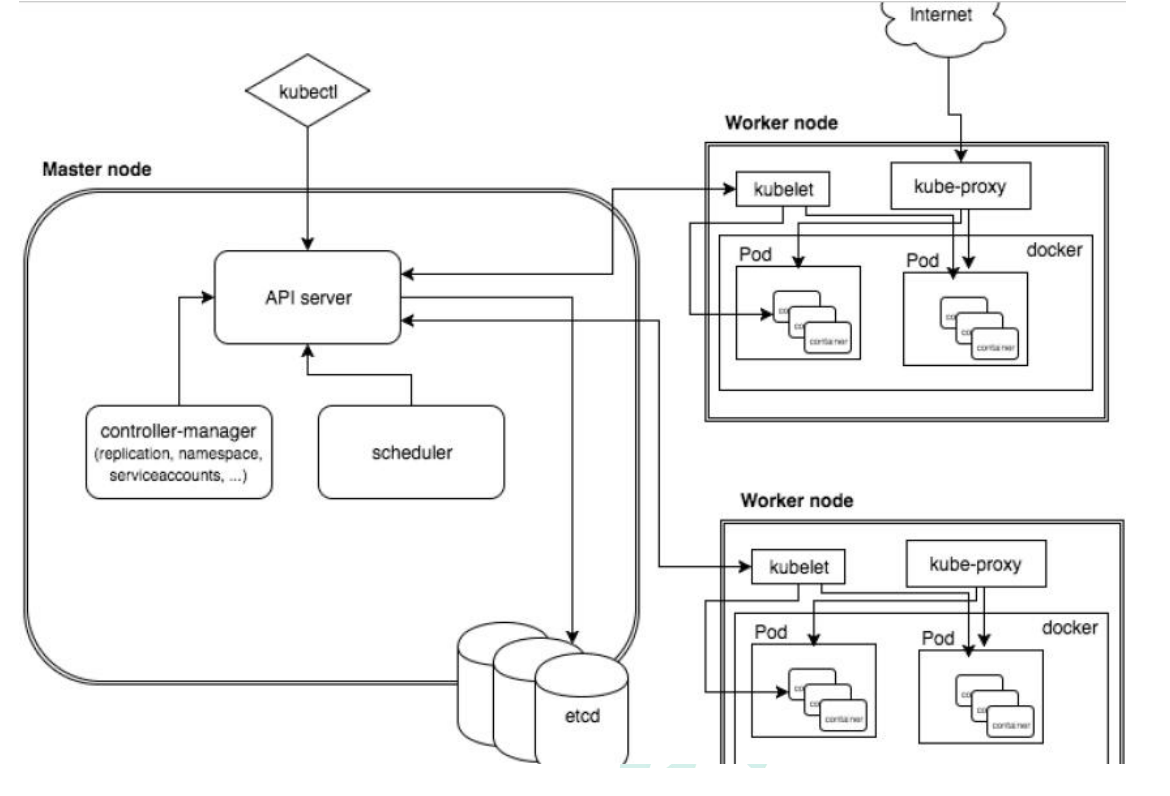
Master Node
- k8s 集群控制节点,对集群进行调度管理,接受集群外用户去集群操作请求;
Master Node 由 API Server、Scheduler、ClusterState Store(ETCD 数据库)和Controller MangerServer 所组成
- API Server。K8S的请求入口服务。API Server负责接收K8S所有请求(来自UI界面或者CLI命令行工具),然后,API Server根据用户的具体请求,去通知其他组件干活。
- Scheduler。K8S所有Worker Node的集群资源调度器。当用户要部署服务时,它通过watch监视pod的创建,负责将pod调度到合适的node节点。
- Controller Manager。K8S所有Worker Node的监控器。Controller Manager有很多具体的Controller,在文章Components of Kubernetes Architecture中提到的有Node Controller、Service Controller、Volume Controller等。Controller负责监控和调整在Worker Node上部署的服务的状态,比如用户要求A服务部署2个副本,那么当其中一个服务挂了的时候,Controller会马上调整,让Scheduler再选择一个Worker Node重新部署服务。
- etcd。K8S的存储服务。数据持久存储化,存储集群中包括node,pod,rc,service等数据;还存储了K8S的关键配置和用户配置,K8S中仅API Server才具备读写权限,其他组件必须通过API Server的接口才能读写数据。
Worker Node
- 集群工作节点,运行用户业务应用容器;
Worker Node 包含 kubelet、kube proxy 和 ContainerRuntime
- Kubelet。Worker Node的监视器,以及与Master Node的通讯器。Kubelet是Master Node安插在Worker Node上的“眼线”,它会定期向Master Node汇报自己Node上运行的服务的状态,并接受来自Master Node的指示采取调整措施。
kubelet负责镜像和pod的管理,主要负责同容器运行时(比如Docker项目)打交道。而这个交互所依赖的,是一个称作CRI(Container Runtime Interface)的远程调用接口。 - Kube-Proxy。K8S的网络代理。Kube-Proxy负责Node在K8S的网络通讯、以及对外部网络流量的负载均衡。
kube-proxy是service服务实现的抽象,负责维护和转发pod的路由,实现集群内部和外部网络的访问。 - Container Runtime。Worker Node的运行环境。即安装了容器化所需的软件环境确保容器化程序能够跑起来,比如Docker Engine。大白话就是帮忙装好了Docker运行环境,负责实现container生命周期管理。
2.将Spark应用迁移到K8s环境中
Spark Operator是Google基于Operator模式开发的一款的工具, 用于通过声明式的方式向K8s集群提交Spark作业,并且负责管理Spark任务在K8s中的整个生命周期,其工作模式如下图所示:
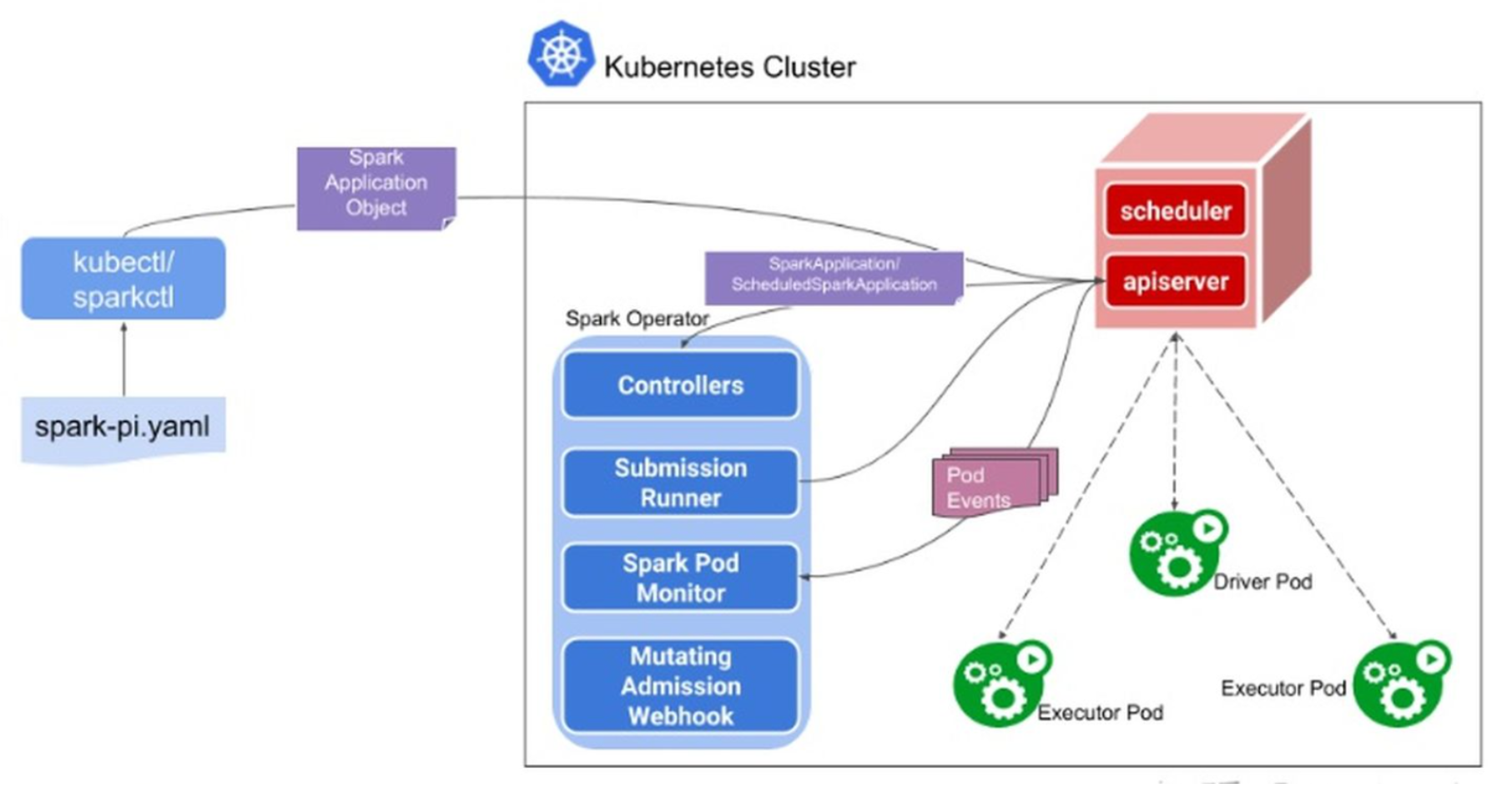
具体流程,包括以下几步:
①:用户使用 sparkctl 或 kubectl 创建 SparkApplication 对象,提交sparkApplication的请求到api-server,并把sparkApplication的CRD持久化到etcd;
②:SparkApplication controller 从 kube-api server 接收到有对象请求,创建 submission (实际上就是 参数化以后的 spark-submit 命令),然后发送给 submission runner。
③:Submission runner 提交 app 到 k8s 集群,并创建 driver pod。一旦 driver pod 正常运行,则由 driver pod 创建 executor pod。 当应用正常运行时,spark pod monitor 监听 application 的 pod 状态,(通过sparkctl可以通过list、status看到)并将pod 状态的更新发送给 controller,由 controller 负责调用 kube-api 更新 spark application 的状态(实际上是更新 SparkApplication CRD 的状态字段)。
④:mutating adminission webhook创建svc,可以查看spark web ui
Spark Opeartor本身即是一个CRD的Controller也是一个Mutating Admission Webhook的Controller。当我们下发spark-pi模板的时候,会转换为一个名叫SparkApplication的CRD对象,然后Spark Operator会监听Apiserver,并将SparkApplication对象进行解析,变成spark-submit的命令并进行提交,提交后会生成Driver Pod,用简单的方式理解,Driver Pod就是一个封装了Spark Jar的镜像。如果是本地任务,就直接在Driver Pod中执行;如果是集群任务,就会通过Driver Pod再生成Exector Pod进行执行。当任务结束后,可以通过Driver Pod进行运行日志的查看。此外在任务的执行中,Spark Operator还会动态attach一个Spark UI到Driver Pod上,通过prometheus暴露监控数据采集接口,创建Service提供spark-ui的访问,我们可以通过这个UI页面进行任务状态的查看。然后通过监听Pod的状态,不断回写更新CRD对象,实现了spark作业任务的生命周期管理。Spark Operator最核心的功能就是将CRD的配置转换为spark-submit的命令。
Spark operator 由以下几部分组成:
SparkApplication控制器, 该控制器用于创建、更新、删除SparkApplication对象,同时控制器还会监控相应的事件,执行相应的动作;
Submission Runner, 负责调用spark-submit提交Spark作业, 作业提交的流程完全复用Spark on K8s的模式;
Spark Pod Monitor, 监控Spark作业相关Pod的状态,并同步到控制器中;
Mutating Admission Webhook: 可选项,处理spark driver 和 executor pod 的定制化功能需求
SparkCtl: 用于和Spark Operator交互的命令行工具