1、数据本地化级别
数据本地化:数据离计算它的代码有多近。基于数据距离代码的距离,有几种数据本地化级别:
-
PROCESS_LOCAL :数据和计算它的代码在同一个Executor JVM进程中。
-
NODE_LOCAL : 数据和计算它的代码在同一个节点,但不在同一个进程中,比如在不同的executor进程中,或者是数据在HDFS文件的block中。因为数据需要在不同的进程之间传递或从文件中读取。分为两种情况,第一种:task 要计算的数据是在同一个 worker 的不同 Executor 进程中。第二种:task 要计算的数据是在同一个 worker 的磁盘上,或在 HDFS 上恰好有 block 在同一个节点上。如果 Spark 要计算的数据来源于 HDFS 上,那么最好的本地化级别就是 NODE_LOCAL。
-
NO_PREF : 从任何地方访问数据速度都是一样,不关心数据的位置。
-
RACK_LOCAL : 机架本地化,数据在同一机架的不同节点上。需要通过网络传输数据以及文件 IO,比 NODE_LOCAL 慢。情况一:task 计算的数据在 worker2 的 EXecutor 中。情况二:task 计算的数据在 work2 的磁盘上。
-
ANY : 数据可能在任何地方,比如其他网络环境内,或者其他机架上。 越往前的级别等待时间应该设置的长一点,因为越是前面性能越好
根据“数据不动代码动”的原则,Spark Core 优先尊重数据分片的本地位置偏好,尽可能地将计算任务分发到本地计算节点去处理。显而易见,本地计算的优势来源于网络开销的大幅减少,进而从整体上提升执行性能。
下面以一个图来展开 spark 是如何进行调度的?
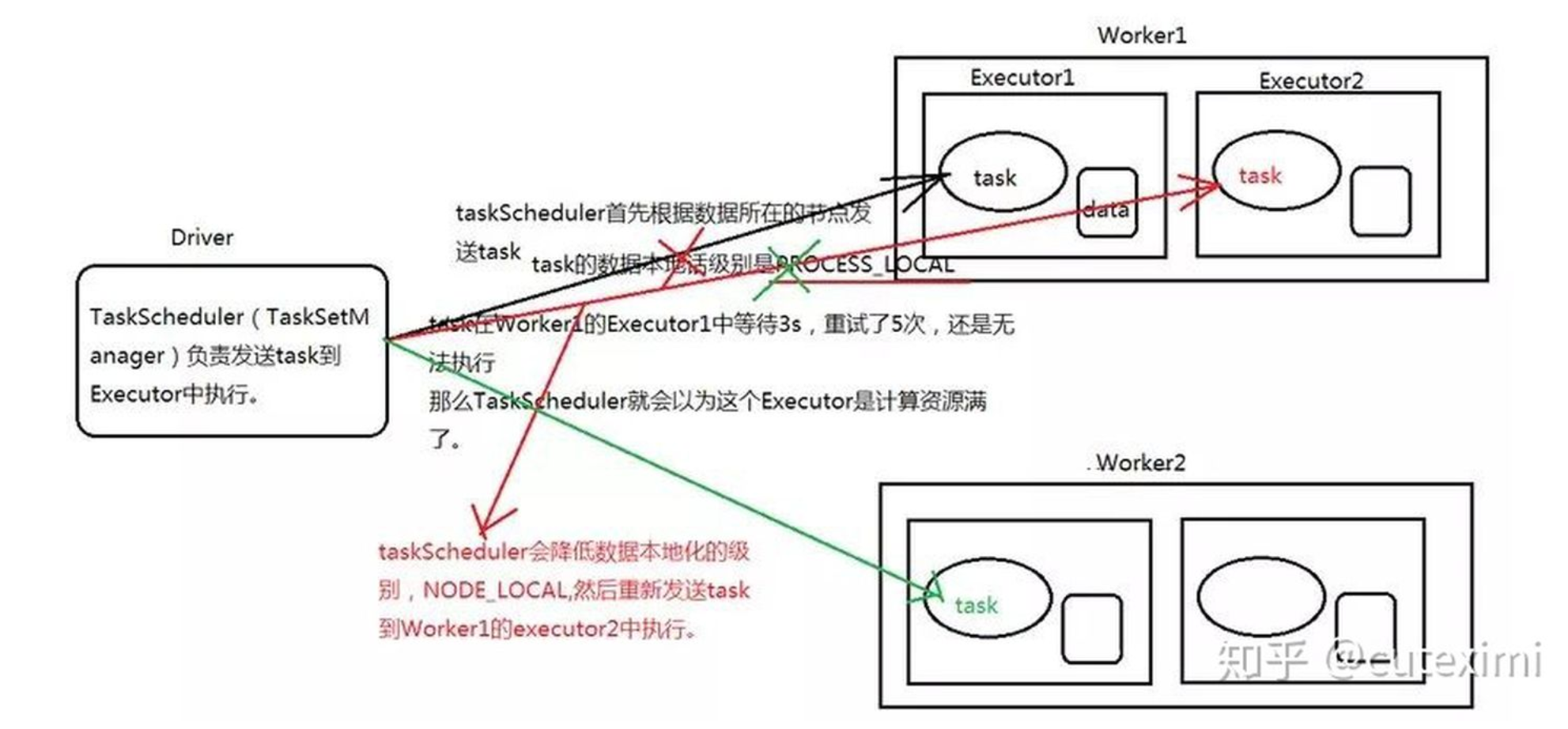
第一步:PROCESS_LOCAL
TaskScheduler 根据数据的位置向数据节点发送 task 任务。如果这个任务在 worker1 的 Executor 中等待了 3 秒。(默认的,可以通过spark.locality.wait 来设置),可以通过 SparkConf() 来修改,重试了 5 次之后,还是无法执行,TaskScheduler 就会降低数据本地化的级别,从 PROCESS_LOCAL 降到 NODE_LOCAL。
第二步:NODE_LOCAL
TaskScheduler 重新发送 task 到 worker1 中的 Executor2 中执行,如果 task 在worker1 的 Executor2 中等待了 3 秒,重试了 5 次,还是无法执行,TaskScheduler 就会降低数据本地化的级别,从 NODE_LOCAL 降到 RACK_LOCAL。
第三步:RACK_LOCAL
TaskScheduler重新发送 task 到 worker2 中的 Executor1 中执行。
第四步:
当 task 分配完成之后,task 会通过所在的 worker 的 Executor 中的 BlockManager 来获取数据。如果 BlockManager 发现自己没有数据,那么它会调用 getRemote() 方法,通过 ConnectionManager 与原 task 所在节点的 BlockManager 中的 ConnectionManager先建立连接,然后通过TransferService(网络传输组件)获取数据,通过网络传输回task所在节点(这时候性能大幅下降,大量的网络IO占用资源),计算后的结果返回给Driver。
可以在代码里面这样设置:
new SparkConf.set("spark.locality.wait","100")

Spark RDD通过其Transformation操作,形成了RDD血缘关系图,即DAG,最后通过Action的调用,触发Job并调度执行。DAGScheduler负责Stage级的调度,主要是将job切分成若干Stages,并将每个Stage打包成TaskSet交给TaskScheduler调度。TaskScheduler负责Task级的调度,将DAGScheduler给过来的TaskSet按照指定的调度策略分发到Executor上执行,调度过程中SchedulerBackend负责提供可用资源,其中SchedulerBackend有多种实现,分别对接不同的资源管理系统。
②:TaskSetManager负责监控管理同一个Stage中的Tasks,TaskScheduler就是以TaskSetManager为单元来调度任务。TaskScheduler会先把DAGScheduler给过来的TaskSet封装成TaskSetManager扔到任务队列里,然后再从任务队列里按照一定的规则(FIFO调度策略)把它们取出来在SchedulerBackend指定的Executor上运行。
TaskSetManager结构如下图所示。

TaskScheduler初始化后会启动SchedulerBackend,它负责跟外界打交道,接收Executor的注册信息,并维护Executor的状态,所以说SchedulerBackend是管“粮食”的,同时它在启动后会定期地去“询问”TaskScheduler有没有任务要运行,也就是说,它会定期地“问”TaskScheduler“我有这么余量,你要不要啊”,TaskScheduler在SchedulerBackend“问”它的时候,会从调度队列中按照指定的调度策略选择TaskSetManager去调度运行,大致方法调用流程如下图所示:

将TaskSetManager加入rootPool调度池中之后,调用SchedulerBackend的riviveOffers方法给driverEndpoint发送ReviveOffer消息;driverEndpoint收到ReviveOffer消息后调用makeOffers方法,过滤出活跃状态的Executor(这些Executor都是任务启动时反向注册到Driver的Executor),然后将Executor封装成WorkerOffer对象;准备好计算资源(WorkerOffer)后,taskScheduler基于这些资源调用resourceOffer在Executor上分配task。
3、spark on k8s和on yarn对比有什么优势?
-
Yarn是资源管理工具,也就是说管理CPU+MEM的资源隔离。
-
k8s是容器编排工具,显然,资源管理是其功能之一。
①:yarn就是一个JVM负载的编排工具,而k8s是容器负载的编排工具。这么一比较,k8s显然胜出一筹,因为容器在应用的支持方面更广泛,更不要说k8s能够实现比yarn好得多的多的隔离了。也就是说,用了k8s之后,不仅仅可以在这个集群运行spark负载,显然也可以运行其他所有的基于容器的负载,那么只需要把应用都进行容器化即可。各种BI工具啦,报表工具啦,查询工具啦,都可以在一个k8s集群上运行,而spark只是作为其中的应用之一。
②:yarn在企业中,只能用来管理离线的计算资源,k8s则是在线离线通吃,这又是另一个优势了。
③:可以增加扩展性。举个栗子来说吧:当yarn作为资源管理器的时候,spark在nodeManager启动任务执行器的时候,是不是需要jdk环境?同一台机器下同一个用户的环境变量往往只有一个JAVA_HOME,因此,如果我在环境变量JAVA_HOME里配置了jdk1.7,那他无论启动的是什么应用,均是使用的jdk1.7的环境(缺省情况)。此时如果有一个新兴的spark应用,需要使用jdk1.8怎么办呢?很自然我们就能想到你更新一下jdk的版本不就可以了吗?当然,我们可以这么做,但是有没有想过万一1.7和1.8有哪些地方不兼容,运行在同一台机器同一个用户下的应用是不是可能就会出错?
而spark on k8s则不一样,k8s是基于容器化的资源管理器,每个容器都有自己的env,你在启动时可以指定你这个容器需要的jdk版本,本机上无须安装任何jdk软件(类比:在docker中,你可以不装jdk,指定jdk image来运行java程序)。spark任务执行器归根结底也是一个jvm进程,所以,他应该也可以用这种方法去指定。这个时候,你就可以体会到k8s所带来的隔离性的好处了。
④:k8s容器化技术很容易做到应用间互不干扰,而在分布式环境下,往往运行着多个应用,所以,这种容器化的技术才会被大家所接受认可。
⑤:然后我们再对比一下Yarn和k8s的依赖的管理。这块是区分点比较大的一个地方。Yarn提供一个全局的spark版本,包括python的版本,全局的包的依赖,缺少环境隔离。而k8s是完全的环境隔离,每一个应用可以跑在完全不同的环境、版本等。Yarn的包管理方案是上传依赖包到HDFS。K8s的包管理方案是自己管理镜像仓库,将依赖包打入image中,支持包依赖管理,将包上传到 HDFS。
为什么容器技术(和K8s)对于Spark很重要?
在共享云计算平台、多租户的应用场景下,每个用户都希望有独立的,隔离的应用环境,减少彼此调用的干扰,比如做Python调用时,不同用户对于Python的版本可能都会有不同要求。容器技术可以为不同用户和应用构建完全隔离,独立,可简单维护的运行环境。这是Hadoop时代的YARN,利用虚拟的资源分配技术所满足不了的。 YARN是大数据资源调度框架,而数据中心软件系统往往还包括数据库服务,web服务,消息服务等等其它应用程序,让这些完全不相干的应用友好共存,最大化资源利用率,是数据中心维护者的最大心愿,K8s碰巧又是可以完成这一使命的有力候选人。
Spark on K8S面临的问题和调整
除了计算需求以外,大数据还会有大量的数据存储在HDFS之上,当Kubernetes可以轻易调度Apache Spark,为它提供一个安全可靠的运行隔离环境时,数据在多用户之间的安全性又变得非常棘手