1.1 Standalone-client
使用SparkSubmit提交任务的时候,使用本地的Client类的main函数来创建sparkcontext并初始化它,为我们的Application启动一个Driver进程;
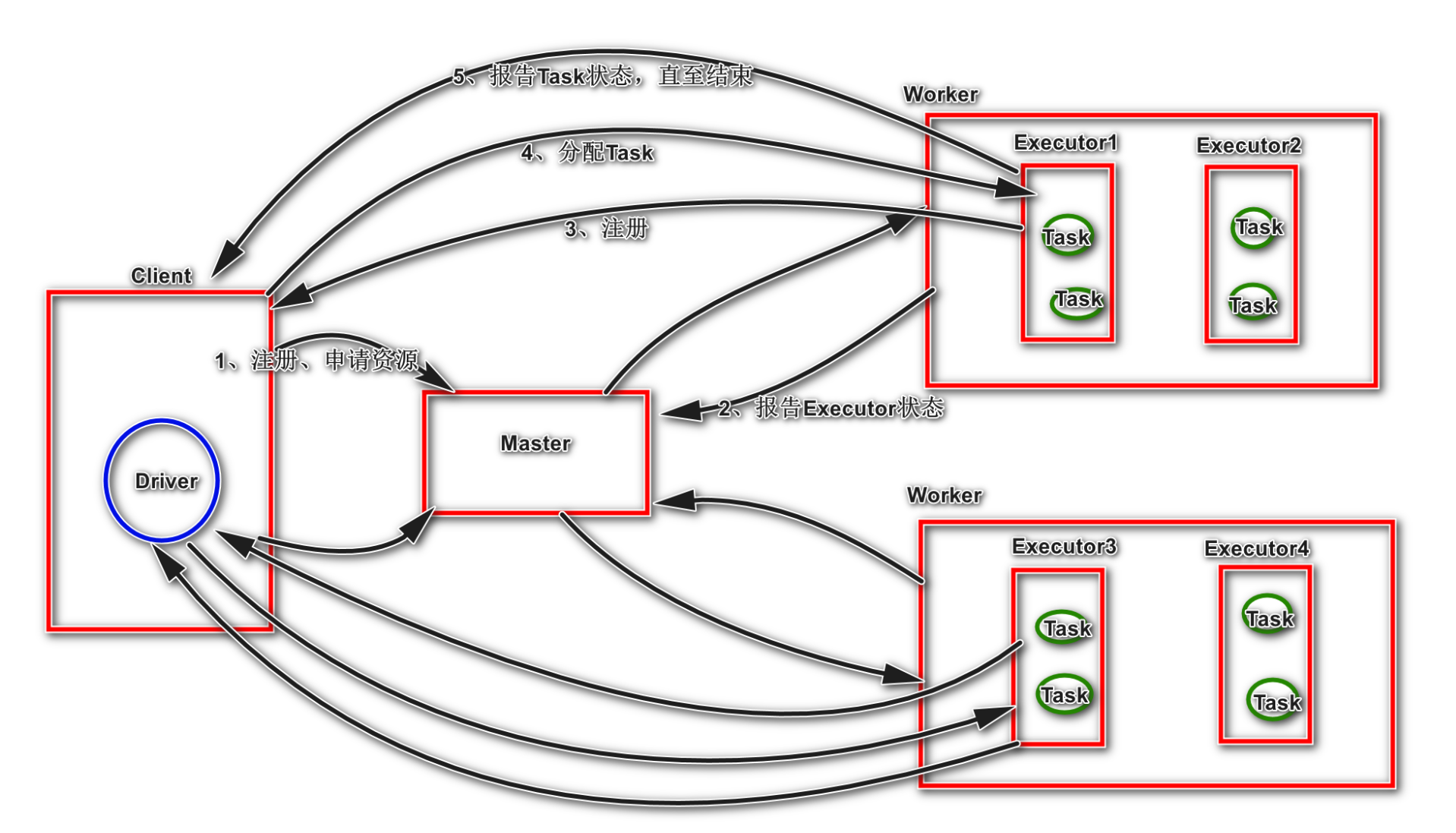
1、Driver连接到Master,注册并申请资源(内核和内存)。
2、Master根据Driver提出的申请,根据worker的心跳报告,来决定到底在那个worker上启StandaloneExecutorBackend(executor)
3、executor向Driver注册
4、Driver将应用分配给executor
Driver解析应用,创建DAG图,提交给DAGScheduler,DAGScheduler根据宽依赖将Job划分为若干stage,并为每一个阶段组装一批task组成taskset(task里面就包含了序列化之后的我们编写的spark transformation);然后将taskset交给TaskScheduler,由其将任务分发给对应的executor;executor进程接收到driver发送过来的taskset,进行反序列化,然后将这些task封装进一个叫taskrunner的线程中,放到本地线程池中,调度我们的作业的执行;
5、executor创建Executor线程池taskrunner,开始执行task,并向Driver汇报 6、所有的task执行完成之后,Driver向Master注销
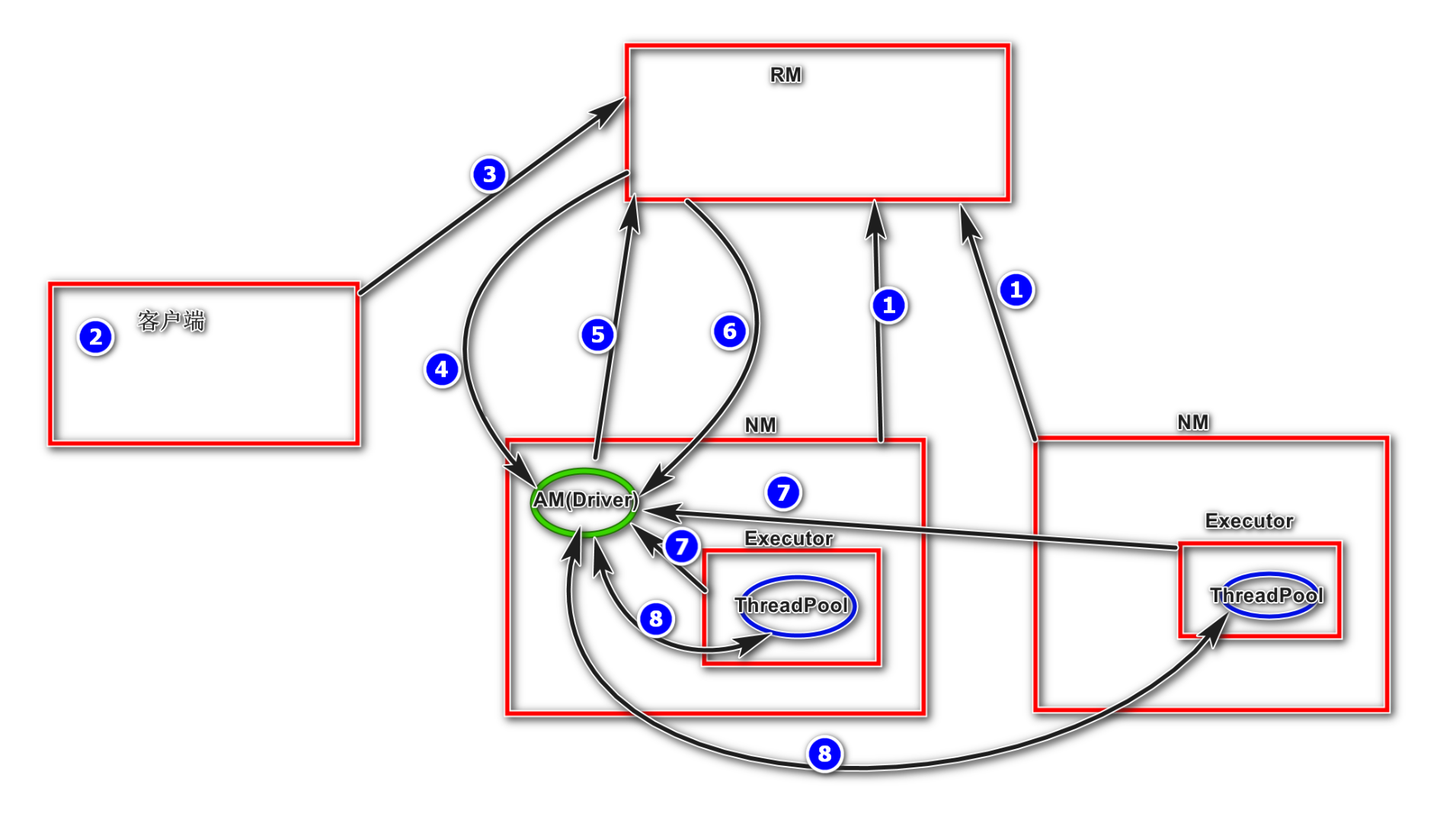
1) 集群启动后,NodeManager向ResourceManager汇报资源,ResourceManager掌握了集群资源
3) 客户端向ResourceManager申请启动ApplicationMaster
4) ResourceManager随机找一台NodeManager启动ApplicationMaster(Driver)
5) ApplicationMaster向ResourceManager申请资源用于启动Executor,然后它将采用轮询的方式通过RPC协议为各个任务申请资源,并监控它们的运行状态直到运行结束;
6) ResourceManager返回一批满足资源的NodeManager节点给ApplicationMaster, ApplicationMaster在这些NodeManager上启动Executor
7) Executor反向注册给Driver(ApplicationMaster),申请Task
8) ApplicationMaster发送task给NodeManager,CoarseGrainedExecutorBackend运行Task并向ApplicationMaster汇报运行的状态和进度,以让ApplicationMaster随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务;监控task执行,回收结果.应用程序运行完成后,ApplicationMaster向ResourceManager申请注销并关闭自己。
RDD究竟是什么
只读,分区,并行操

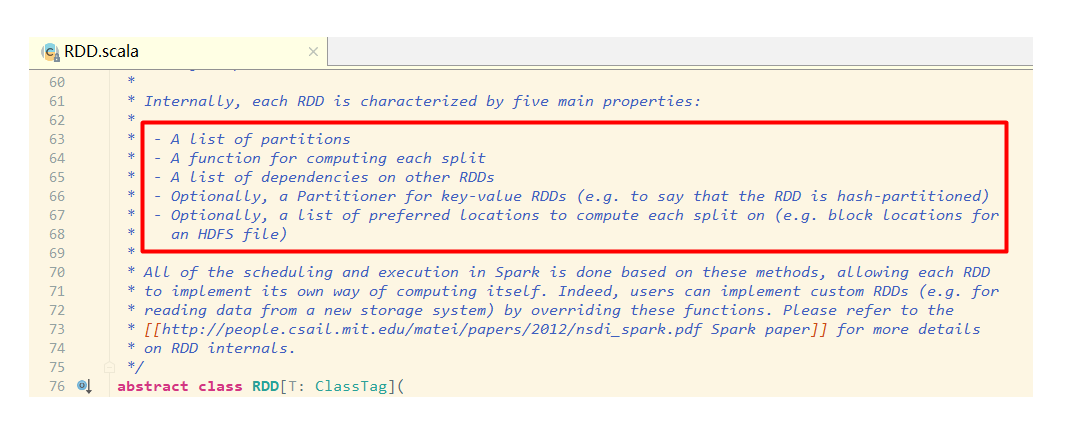
翻了spark的源码,找到了其中RDD的定义,一个RDD当中包含以下内容:
-
A list of partitions
-
A function for computing each split
-
A list of dependencies on other RDDs
-
Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)
-
Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file)
我们一条一条来看:
-
分区列表,分区是spark中数据集的最小单位。也就是说spark当中数据是以分区为单位存储的,不同的分区被存储在不同的节点上。这也是分布式计算的基础。对于RDD来说,每个分片都会被一个计算任务处理,分片数决定并行度。用户可以在创建RDD时指定RDD的分片个数,如果没有指定,那么就会采用默认值。
-
在各个分区上执行计算任务的函数。在spark当中数据和执行的操作是分开的,并且spark基于懒计算的机制,也就是在真正触发计算的行动操作出现之前,spark会存储起来对哪些数据执行哪些计算。数据和计算之间的映射关系就存储在RDD中。
-
RDD之间的依赖关系,RDD之间存在转化关系,一个RDD可以通过转化操作转化成其他RDD,这些转化操作都会被记录下来。当部分数据丢失的时候,spark可以通过记录的依赖关系重新计算丢失部分的数据,而不是重新计算所有数据。
-
可选项。分区方法,也就是计算分区的函数。spark当中支持基于hash的hash分区方法和基于范围的range分区方法。
-
可选项,一个列表,存储存取每个Partition的优先位置(preferred location)。对于一个HDFS文件来说,这个列表保存的就是每个Partition所在的块的位置。按照"移动数据不如移动计算"的理念,Spark在进行任务调度的时候,会尽可能选择那些存有数据的worker节点来进行任务计算。
通过以上五点,我们可以看出spark一个重要的理念。即移动数据不如移动计算,也就是说在spark运行调度的时候,会倾向于将计算分发到节点,而不是将节点的数据搜集起来计算。
2.1 什么是弹性?
我的理解如下:
1. RDD可以在内存和磁盘之间手动或自动切换
2. RDD可以通过转换成其他的RDD,即血统
3. RDD可以存储任意类型的数据
2.2 RDD存储的内容是什么?
RDD其实是不存储真实数据的,存储的只是 真实数据的分区信息的计算方法getPartitions,还有就是针对单个分区的读取方法 compute。
初代RDD:
@transient private var _sc: SparkContext,
@transient private var deps: Seq[Dependency[_]]
) extends Serializable with Logging {
//计算某个分区数据的方法 ,将某个分区的数据读成一个 Iterator<br>
def compute(split: Partition, context: TaskContext): Iterator[T]
//计算分区信息 只会被调用一次
protected def getPartitions: Array[Partition]
}
子代RDD:
//子代RDD的作用起始很简单 就是记录初代RDD到底在干了什么才得到了自己
private[spark] class MapPartitionsRDD[U: ClassTag, T: ClassTag](
prev: RDD[T], //上一代RDD
f: (TaskContext, Int, Iterator[T]) => Iterator[U], // (TaskContext, partition index, iterator) //初代RDD生成自己的方法
preservesPartitioning: Boolean = false)
extends RDD[U](prev) {
override val partitioner = if (preservesPartitioning) firstParent[T].partitioner else None
override def getPartitions: Array[Partition] = firstParent[T].partitions
override def compute(split: Partition, context: TaskContext): Iterator[U] =
f(context, split.index, firstParent[T].iterator(split, context))
}
初代RDD: 处于血统的顶层,存储的是任务所需的数据的分区信息,还有单个分区数据读取的方法,没有依赖的RDD, 因为它就是依赖的开始。
子代RDD: 处于血统的下层, 存储的东西就是 初代RDD到底干了什么才会产生自己,还有就是初代RDD的引用
2.3 数据读取发生在什么时候?
数据读取是发生在运行的Task中,也就是说,任务在分发的executor上运行的时候数据被读取了
final def iterator(split: Partition, context: TaskContext): Iterator[T] = {
if (storageLevel != StorageLevel.NONE) {
//先判断是否有缓存 ,有则直接从缓存中取 , 没有就从磁盘中取出来, 然后再执行缓存操作
SparkEnv.get.cacheManager.getOrCompute(this, split, context, storageLevel)
} else {
//直接从磁盘中读取 或 从 检查点中读取
computeOrReadCheckpoint(split, context)
}
}