刚开始配置时因为各种依赖jar包问题导致环境老是有问题,花费了两三天,特此记录下,方便后来学习使用。
本文使用Idea2020开发工具开发第一个spark程序。使用的编程语言是scala。注意:
* JDK版本要和hadoop集群里的一样
* scala版本要和spark里指定的一致
* hadoop版本要和spark里指定的一致
打开idea,首先安装Scala插件。file->settings,然后按照下图操作,我已经按照完毕,所以显示installed
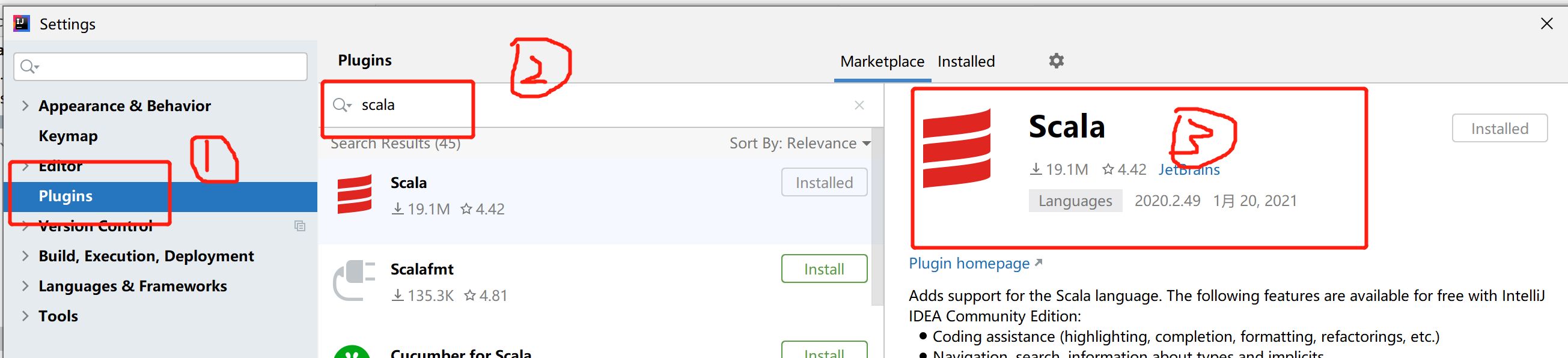
配置SDK和JDK

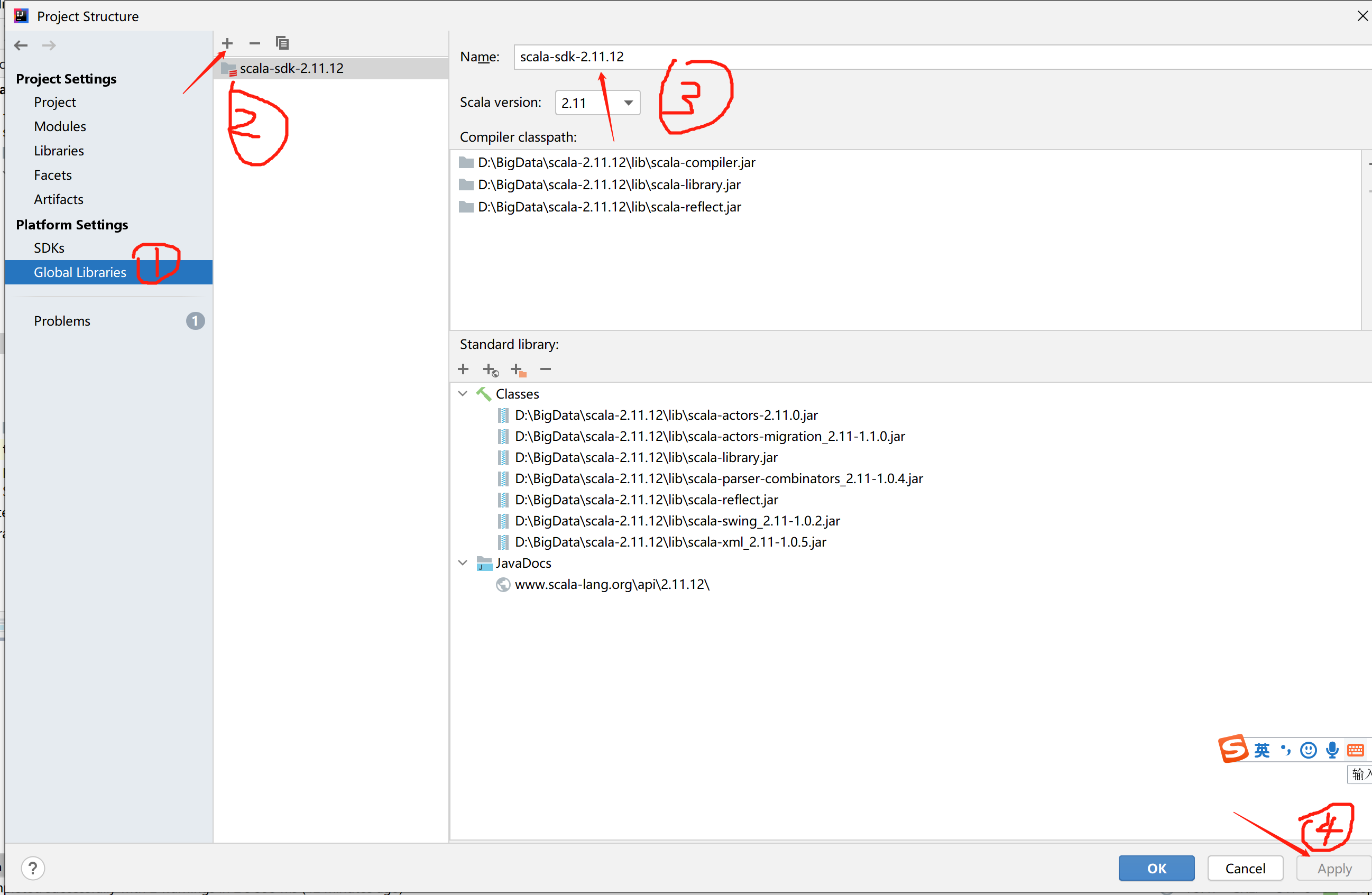
添加scala sdk。注意版本问题,要和你安装spark里指定的一致。
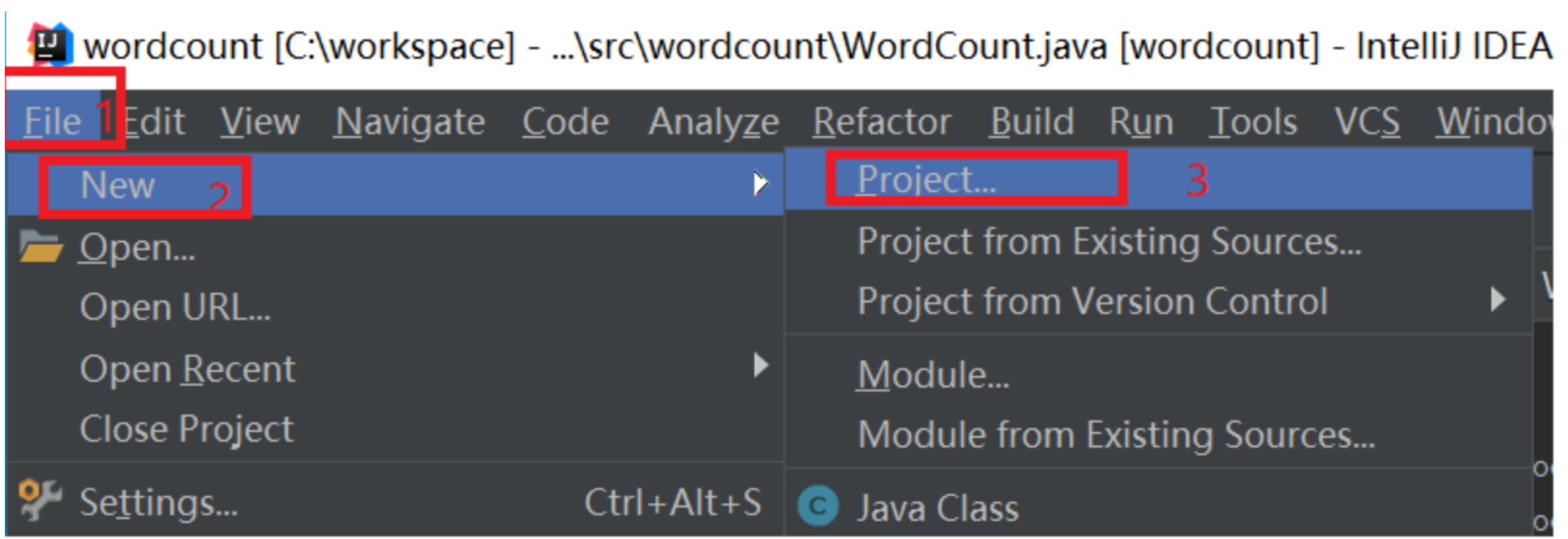
新建一个工程,如下图所示:
在弹出新建工程的界面选择Java,接着选择SDK,一般默认即可,点击“Next”按钮,如下图:
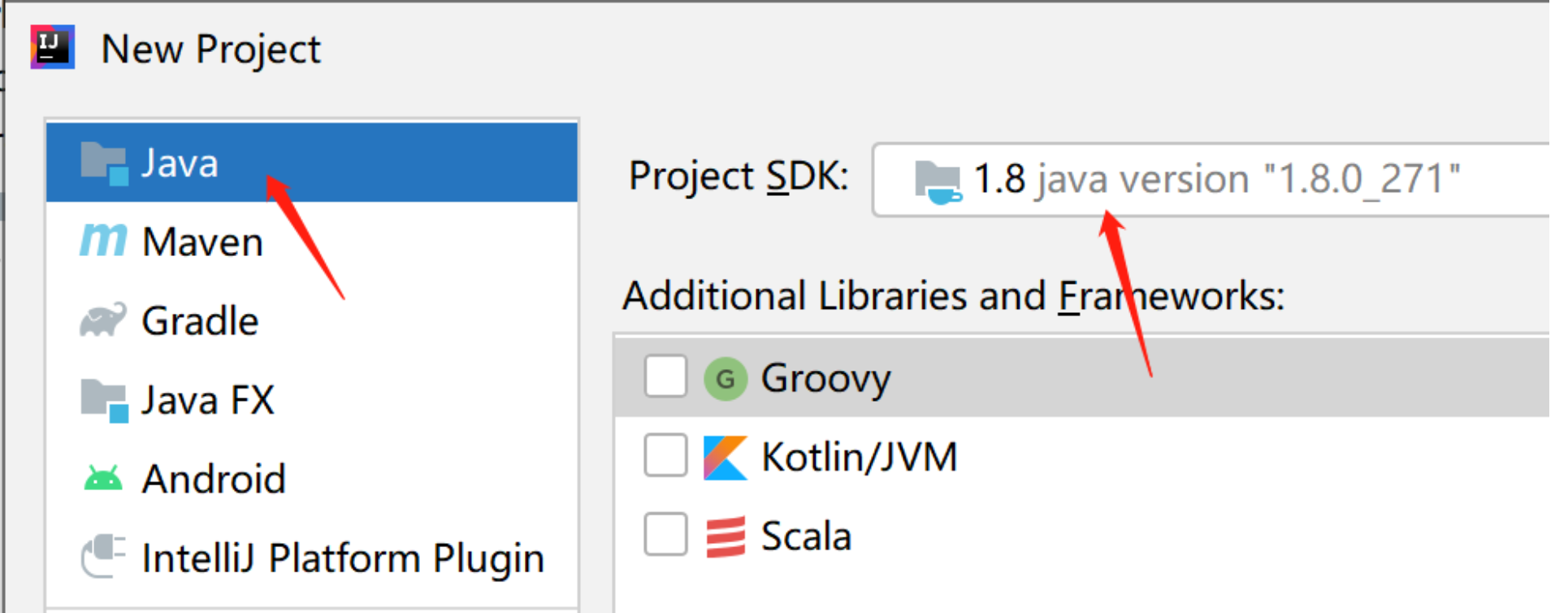
在弹出的选择创建项目的模板页面,不做任何操作,直接点击“Next”按钮。
输入项目名称,点击Finish,就完成了创建新项目的工作,我们的项目名称为:WordCount。
添加依赖jar包,要给项目添加相关依赖包,否则会出错。
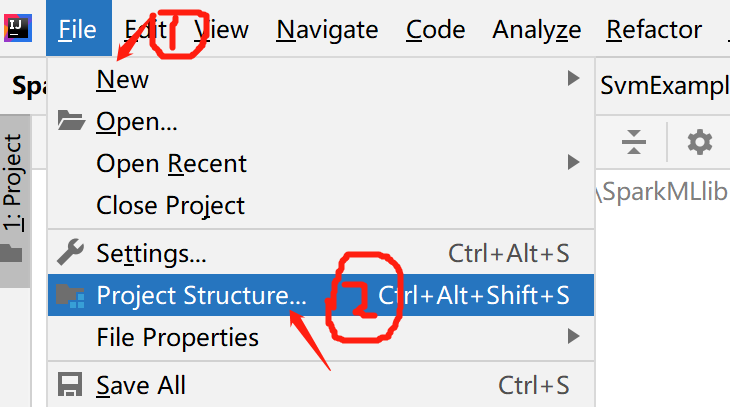
点击Idea的File菜单,然后点击“Project Structure”菜单,如下图所示:
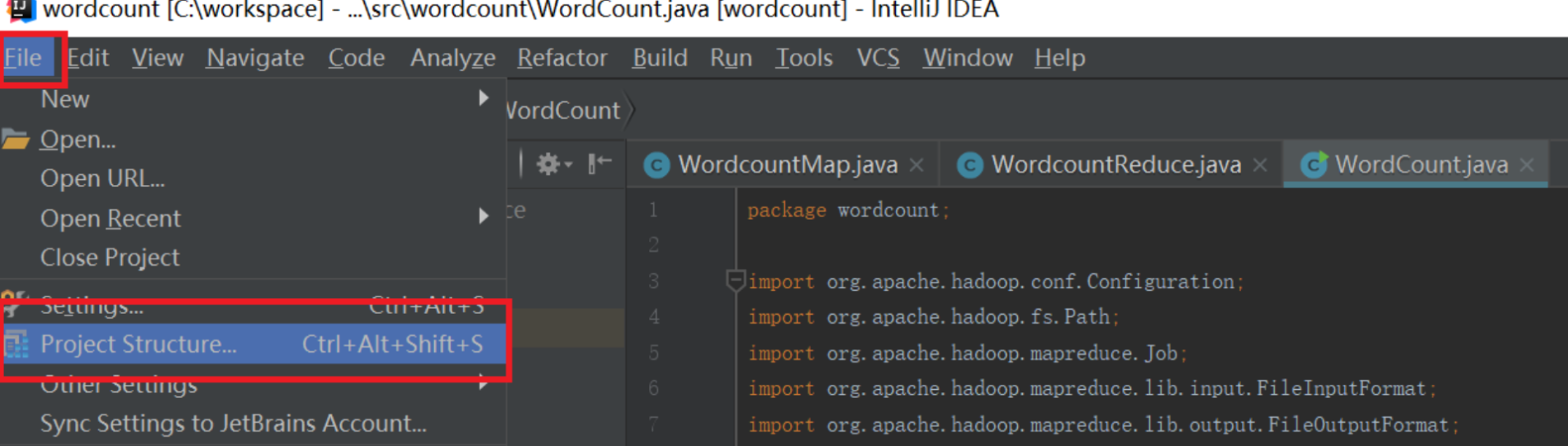
依次点击Modules和Dependencies,然后选择“+”的符号,如下图所示:
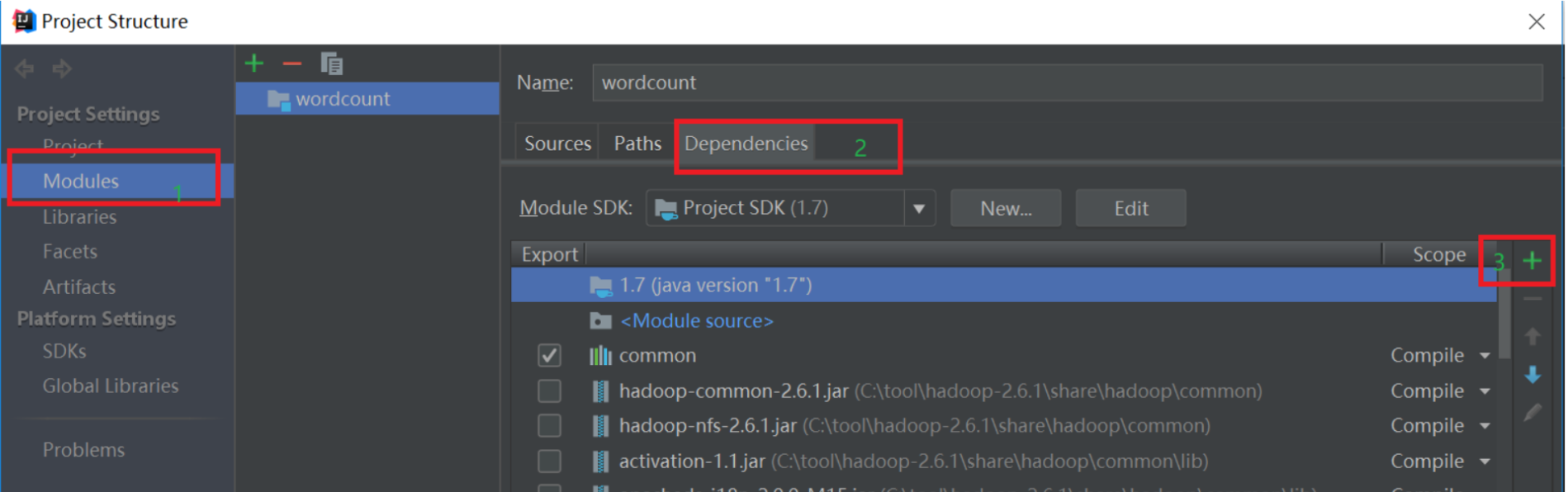
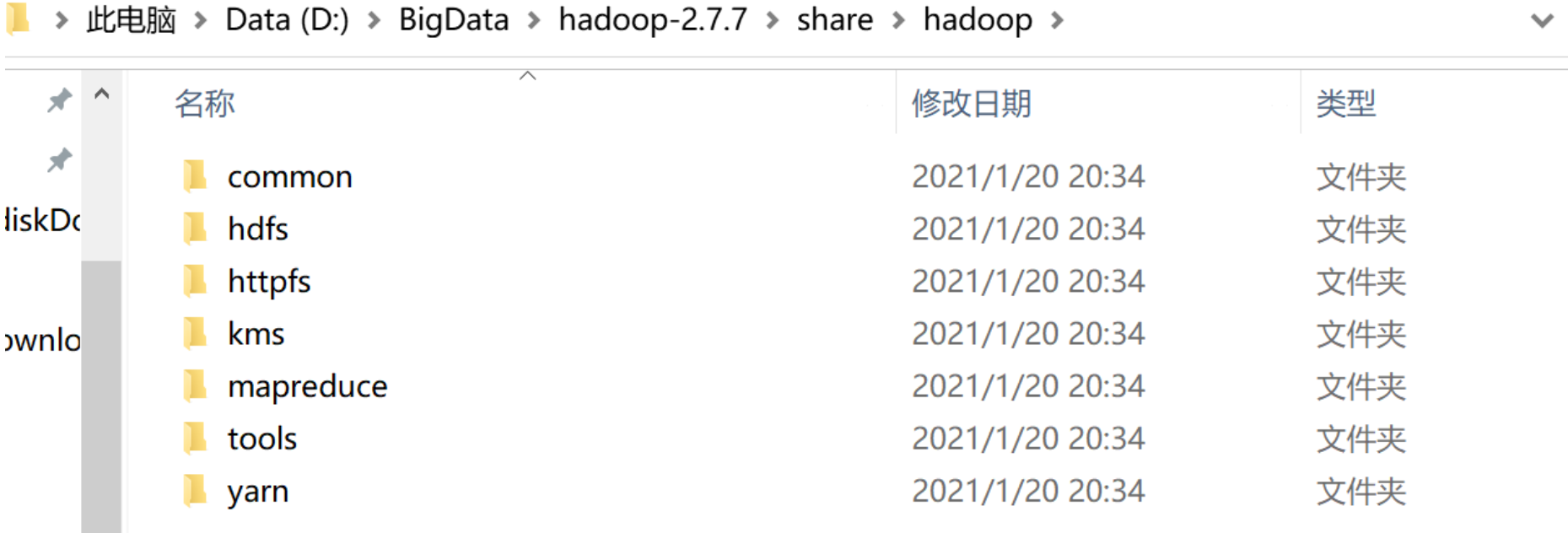
选择hadoop的包,我用得是hadoop2.7.7。把下面的依赖包都加入到工程中,否则会出现某个类找不到的错误。
(1)”/usr/local/hadoop/share/hadoop/common”目录下的所有JAR包;
(2)/usr/local/hadoop/share/hadoop/common/lib”目录下的所有JAR包;
(3)“/usr/local/hadoop/share/hadoop/hdfs”目录下的所有JAR包;
(4)“/usr/local/hadoop/share/hadoop/hdfs/lib”目录下的所有JAR包。
(5)“/usr/local/hadoop/share/hadoop/mapreduce”目录下的所有JAR包。
(6)“/usr/local/hadoop/share/hadoop/mapreduce/lib”目录下的所有JAR包。
(7)“/usr/local/hadoop/share/hadoop/yarn”目录下的所有JAR包。
(8)“/usr/local/hadoop/share/hadoop/yarn/lib”目录下的所有JAR包。
选择spark安装包:
(9)"D:BigDataspark-2.4.7-bin-without-hadoopspark-2.4.7-bin-without-hadoopjars"目录下的所有JAR包。一定注意不要引入下面的_jar文件夹中的jar包,容易出现jar包冲突,报错。(之前说错了,在此更正一下)
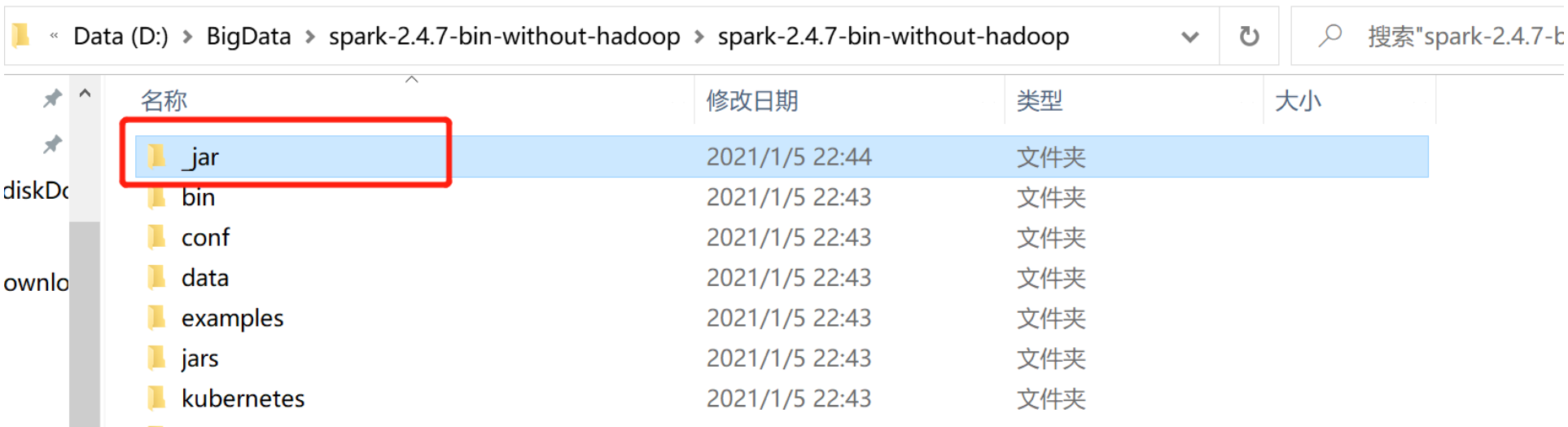
至此项目已经创建好。
代码写好之后,开始打jar包,按照下图打包。点击“File”,然后点击“Project Structure”,弹出如下的界面,
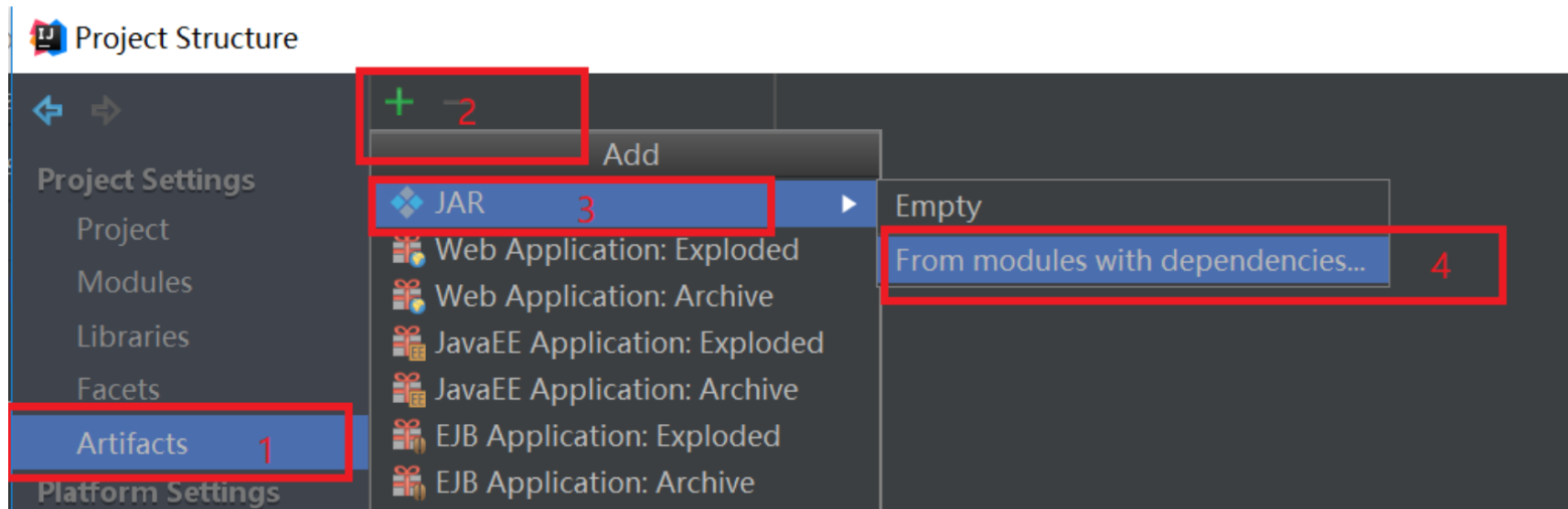
依次点击"Artifacts" -> "+" -> "JAR" -> "From modules with dependencies",然后弹出一个选择入口类的界面,选择刚刚写好的WordCount类,如下图:

按照上面设置好之后,就开始打jar包,如下图:
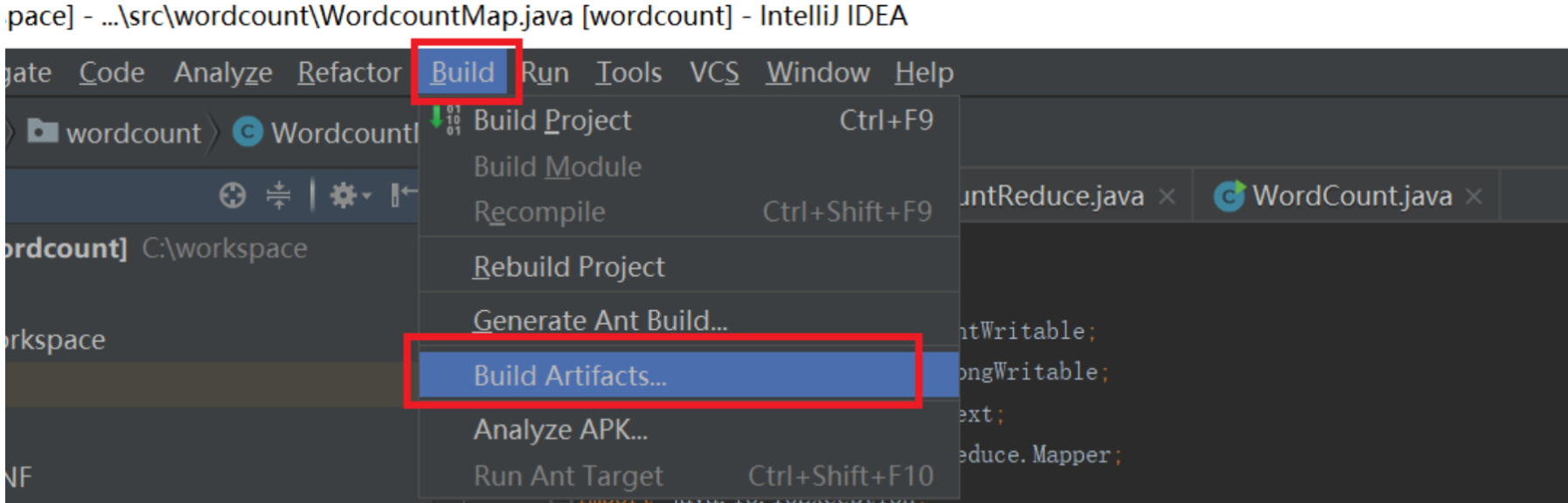

点击上图的“Build”之后就会生成一个jar包。jar的位置看下图,依次点击File->Project Structure->Artifacts就会看到如下的界面:

将打好包的wordcount.jar文件上传到装有hadoop集群的机器中。