为了解决内存访问越界的问题,英特尔发明了80286处理器,这款处理器引入了保护模式,为现代操作系统和应用程序奠定了基础,但是80286在设计上有些奇葩,例如:
段寄存器为24位,通用寄存器为16位,这样显得不伦不类,80286上电时处于实模式,段寄存器只用到了16位,进入保护模式后,段选择子也不会用到24位,因此24位寄存器有些浪费。
理论上,段寄存器中的数值可以直接作为段基址。80286中16位寄存器最多访问64K的内存,为了访问16M的内存,必须不停的切换段基址。
80286是一款试水的产品,80286引入的保护模式得到了市场的认可,试水成功后,英特尔紧接着推出了80386,这时计算机进入新时期的标志,80386有以下特性:
1、32位的地址总线(可支持4G的内存空间)
2、段寄存器和通用寄存器都为32位,任何一个寄存器都能访问到内存的任意角落,这也开启了平坦内存模式的新时代,将段基址设置为0,使用通用寄存器即可访问4G内存空间。
80386依然要兼容8086和80286,因为已经有很多程序在这两款机器上运行,因此,80386有以下三种运行模式:

平坦模式只是分段模式的一个特例,保护模式是在分段模式的基础上实现的,在分段模式基础上加入了内存保护机制。
分段机制要想达到内存保护的目的,必须要给每个段设置段属性,如下所示:
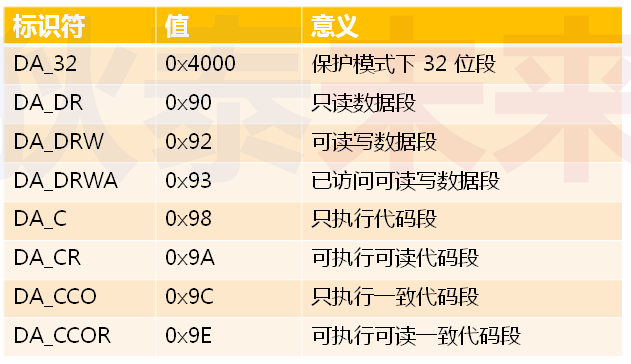
段属性定义了每个段是否可读可写、是否可执行等。
每个段有自己的属性,相应的选择子也有自己的属性,选择子属性如下:
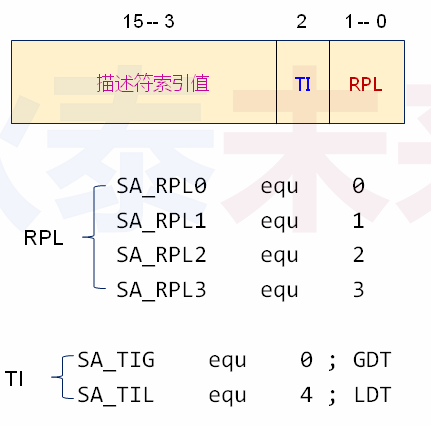
段选择子中3-15位是段描述符表的下标。
段描述符是64位的,具体如下所示:
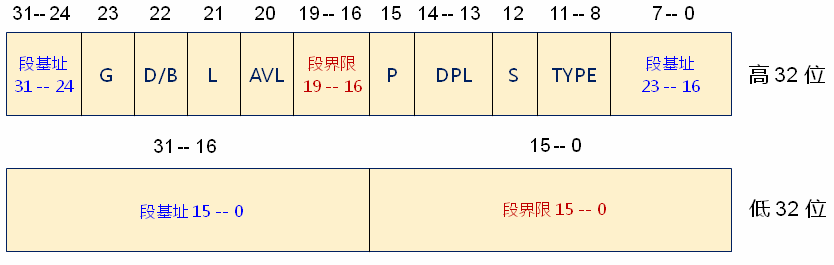
在汇编程序中,我们需要定义自己的段,也要自己定义段描述符,因此,给出如下的汇编宏,这是一个宏定义,其定义的64位数据正好能和上图对应起来。

有了以上的宏定义,我们就可以使用它直接定义自己的段描述符了,这个宏接受3个参数,也即上图中Descriptor 3中的3代表接受三个参数,而%1,%2,%3分别表示取出第几个参数,下面给出保护模式中的段定义:

上图中,第一个段描述符定义为0,这是x86处理器建议的,而第二个段描述符基地址也定义为0,我们在程序的运行过程中会进行修改,而GDT结束后,下面紧接着是一个结构体,定义了GDT的界限和GDT的基地址。
做实验之前,我们先给出一些汇编的知识点,如下:

section定义的段在逻辑上是紧挨着的,它指的是源程序是挨着的,因此,编译出的二进制也是挨着的,即使这两个section在源程序中放在了不同的位置,只要他们的段名字相同即可。

16位编译和32编译在对齐上会存在一下差异,或者16位指令和32位指令在格式上也有一些差异,这些会由编译器进行处理。
程序中需要注意的事项如下:

有了以上的分析,我们直接给出汇编代码,首先添加一个文件inc.asm,文件中给出了一下宏定义和常量定义,如下所示:
1 ; Segment Attribute 2 DA_32 equ 0x4000 3 DA_DR equ 0x90 4 DA_DRW equ 0x92 5 DA_DRWA equ 0x93 6 DA_C equ 0x98 7 DA_CR equ 0x9A 8 DA_CCO equ 0x9C 9 DA_CCOR equ 0x9E 10 11 ; Selector Attribute 12 SA_RPL0 equ 0 13 SA_RPL1 equ 1 14 SA_RPL2 equ 2 15 SA_RPL3 equ 3 16 17 SA_TIG equ 0 18 SA_TIL equ 4 19 20 ; 描述符 21 ; usage: Descriptor Base, Limit, Attr 22 ; Base: dd 23 ; Limit: dd (low 20 bits available) 24 ; Attr: dw (lower 4 bits of higher byte are always 0) 25 %macro Descriptor 3 ; 段基址, 段界限, 段属性 26 dw %2 & 0xFFFF ; 段界限1 27 dw %1 & 0xFFFF ; 段基址1 28 db (%1 >> 16) & 0xFF ; 段基址2 29 dw ((%2 >> 8) & 0xF00) | (%3 & 0xF0FF) ; 属性1 + 段界限2 + 属性2 30 db (%1 >> 24) & 0xFF ; 段基址3 31 %endmacro ; 共 8 字节
loader.asm的程序如下所示:
1 %include "inc.asm" 2 3 org 0x9000 4 5 jmp CODE16_SEGMENT 6 7 [section .gdt] 8 ; GDT definition 9 ; 段基址, 段界限, 段属性 10 GDT_ENTRY : Descriptor 0, 0, 0 11 CODE32_DESC : Descriptor 0, Code32SegLen - 1, DA_C + DA_32 12 ; GDT end 13 14 GdtLen equ $ - GDT_ENTRY 15 16 GdtPtr: 17 dw GdtLen - 1 18 dd 0 19 20 21 ; GDT Selector 22 23 Code32Selector equ (0x0001 << 3) + SA_TIG + SA_RPL0 24 25 ; end of [section .gdt] 26 27 28 [section .s16] 29 [bits 16] 30 CODE16_SEGMENT: 31 mov ax, cs 32 mov ds, ax 33 mov es, ax 34 mov ss, ax 35 mov sp, 0x7c00 36 37 ; initialize GDT for 32 bits code segment 38 mov eax, 0 39 mov ax, cs 40 shl eax, 4 41 add eax, CODE32_SEGMENT 42 mov word [CODE32_DESC + 2], ax 43 shr eax, 16 44 mov byte [CODE32_DESC + 4], al 45 mov byte [CODE32_DESC + 7], ah 46 47 ; initialize GDT pointer struct 48 mov eax, 0 49 mov ax, ds 50 shl eax, 4 51 add eax, GDT_ENTRY 52 mov dword [GdtPtr + 2], eax 53 54 ; 1. load GDT 55 lgdt [GdtPtr] 56 57 ; 2. close interrupt 58 cli 59 60 ; 3. open A20 61 in al, 0x92 62 or al, 00000010b 63 out 0x92, al 64 65 ; 4. enter protect mode 66 mov eax, cr0 67 or eax, 0x01 68 mov cr0, eax 69 70 ; 5. jump to 32 bits code 71 jmp dword Code32Selector : 0 72 73 [section .s32] 74 [bits 32] 75 CODE32_SEGMENT: 76 mov eax, 0 77 jmp CODE32_SEGMENT 78 79 Code32SegLen equ $ - CODE32_SEGMENT
第一扇区中的加载程序将loader.asm加载到指定位置,然后跳转过来开始执行,刚进入程序时,首先跳转到16位模式代码处执行,如第5行所示,16位模式处的代码完成了初始化GDT表和GDT表指针(GDT表的起始地址),此外,还完成了以下工作:
1、加载GDT表指针
2、关闭中断
3、打开A20地址线
4、进入保护模式
5、跳转到32位代码处执行
以上的程序中第55行加载GDT,就是将定义段描述符表信息的结构体加载到CPU寄存器中。第68行的mov cr0, eax执行完,CPU就已经进入了32位的保护模式,那么CPU又是怎么知道该运行在16位还是32位呢,在设置段属性时,我们给段定义了DA_32属性(第11行),这个属性表示:这个段是保护模式下的32位段。并且属性中还设置了只可以执行。在执行jmp dword Code32Selector : 0之前,CPU已经进入了32位保护模式,因此,偏移地址已经没有了64K的限制,按段描述符中的20位偏移计算的话,偏移地址的限制为1M。段界限可以是1字节为单位也可以是4k字节为单位,在段属性中有一个粒度位可以设置,如果粒度为4k,那20位的段界限最大就可以到4G了,可以访问整个物理内存。这句跳转语句中的段基址是段选择子而不再是实模式下的基地址。执行完这句话之后,CPU根据32位代码的段描述符的地址,跳转到相应的位置去执行。这句话中的dword告诉编译器要按照32位地址模式去编译这句话,如果不是按照32位模式,则当偏移地址大小超过64K时会被截断,造成错误,因为32位模式下偏移地址的限制是1M(20位偏移限制,1字节为单位的情况下)。
32位代码处是一个死循环,以上程序,我们使用bochs断点调试来观察现象,断点打在第71行处:
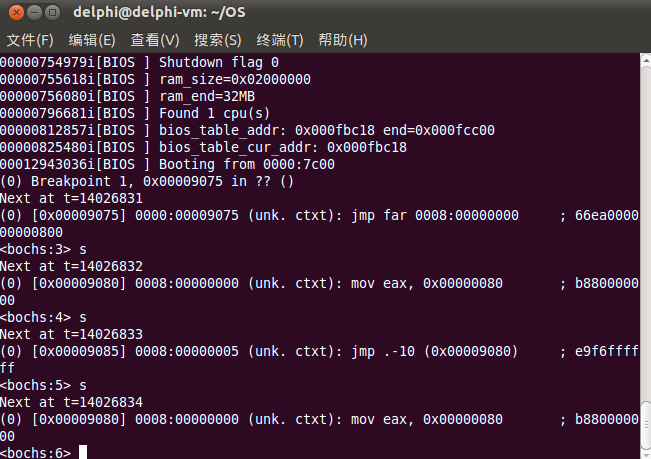
上图中0x00009075处即为断点,从断点处接着向下执行即进入了32位代码,通过s单步执行发现,程序进入了死循环。
更细致的观察:
我们在jmp dword Code32Selector处打上断点,执行到这句话时,打印寄存器的内容,结果如下:
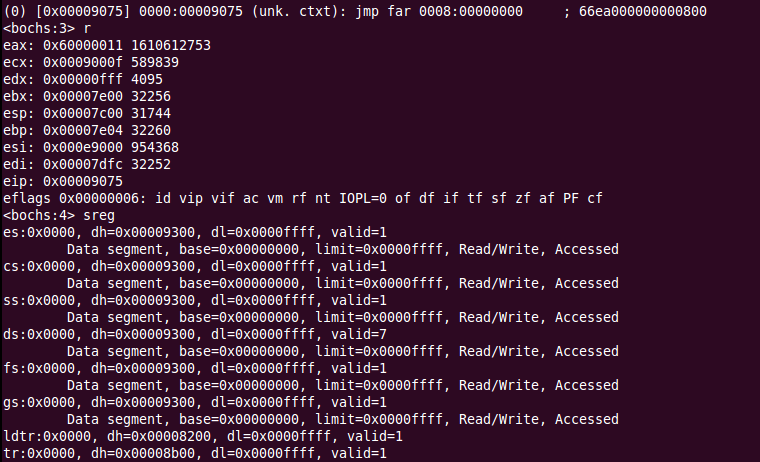
可以看到,cs为0,base为0,eip为0x9075,这也是绝对物理地址,此时,虽然已经设置CPU为保护模式,但是还没有加载具体的段描述符,所以还是显示的实模式下的内容。接着执行,再次打印寄存器内容:
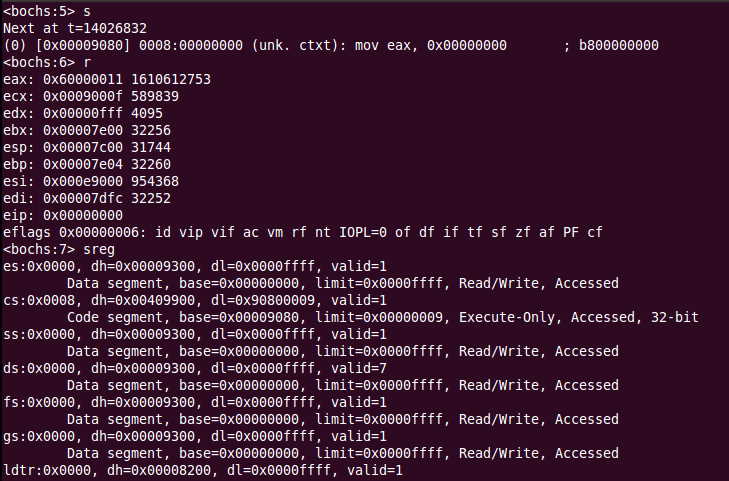
执行完jmp dword Code32Selector之后,CPU根据段描述符更改了相应的寄存器,真正的进入了32位保护模式,可以看到cs为0x8,这是段选择子起始地址下标(按字节算),base变为了0x9080,这是mov eax,0的地址,而eip为0,这就是偏移地址了,接着执行的话,eip会变为下一条指令的段内偏移地址,如下:
下面我们对程序进行小小的修改,如下:
1 %include "inc.asm" 2 3 4 5 org 0x9000 6 7 8 9 jmp CODE16_SEGMENT 10 11 12 13 [section .gdt] 14 15 ; GDT definition 16 17 ; ¶Î»ùÖ·£¬ ¶ÎœçÏÞ£¬ ¶ÎÊôÐÔ 18 19 GDT_ENTRY : Descriptor 0, 0, 0 20 21 GDT_ENTRYTEMP : Descriptor 0, 0, 0 22 23 CODE32_DESC : Descriptor 0, Code32SegLen - 1, DA_C + DA_32 24 25 ; GDT end 26 27 28 29 GdtLen equ $ - GDT_ENTRY 30 31 32 33 GdtPtr: 34 35 dw GdtLen - 1 36 37 dd 0 38 39 40 41 42 43 ; GDT Selector 44 45 46 47 Code32Selector equ (0x0002 << 3) + SA_TIG + SA_RPL0 48 49 50 51 ; end of [section .gdt] 52 53 54 55 56 57 [section .s16] 58 59 [bits 16] 60 61 CODE16_SEGMENT: 62 63 mov ax, cs 64 65 mov ds, ax 66 67 mov es, ax 68 69 mov ss, ax 70 71 mov sp, 0x7c00 72 73 74 75 ; initialize GDT for 32 bits code segment 76 77 mov eax, 0 78 79 mov ax, cs 80 81 shl eax, 4 82 83 add eax, CODE32_SEGMENT 84 85 mov word [CODE32_DESC + 2], ax 86 87 shr eax, 16 88 89 mov byte [CODE32_DESC + 4], al 90 91 mov byte [CODE32_DESC + 7], ah 92 93 94 95 ; initialize GDT pointer struct 96 97 mov eax, 0 98 99 mov ax, ds 100 101 shl eax, 4 102 103 add eax, GDT_ENTRY 104 105 mov dword [GdtPtr + 2], eax 106 107 108 109 ; 1. load GDT 110 111 lgdt [GdtPtr] 112 113 114 115 ; 2. close interrupt 116 117 cli 118 119 120 121 ; 3. open A20 122 123 in al, 0x92 124 125 or al, 00000010b 126 127 out 0x92, al 128 129 130 131 ; 4. enter protect mode 132 133 mov eax, cr0 134 135 or eax, 0x01 136 137 mov cr0, eax 138 139 140 141 ; 5. jump to 32 bits code 142 143 jmp dword Code32Selector : 0 144 145 146 147 [section .s32] 148 149 [bits 32] 150 151 CODE32_SEGMENT: 152 153 mov eax, 0 154 155 jmp CODE32_SEGMENT 156 157 158 159 Code32SegLen equ $ - CODE32_SEGMENT
21行加了一个段描述符,47将选择子中的下标改为2,再次调试程序,断点打在相同的位置,结果如下:
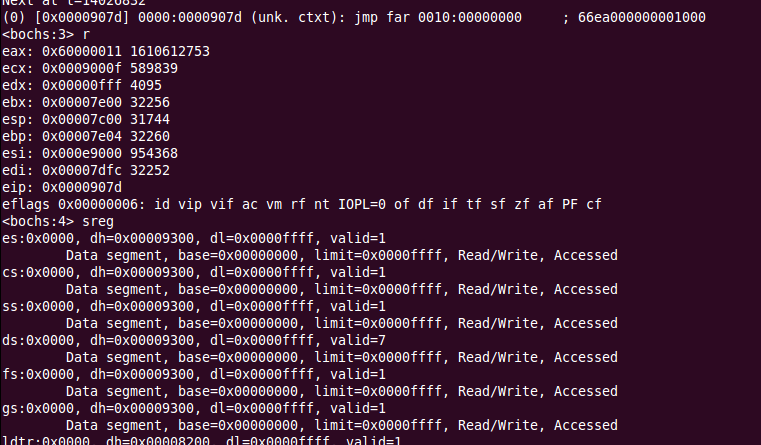
执行到jmp dword Code32Selector时,现象相似,继续执行并打印寄存器内容:
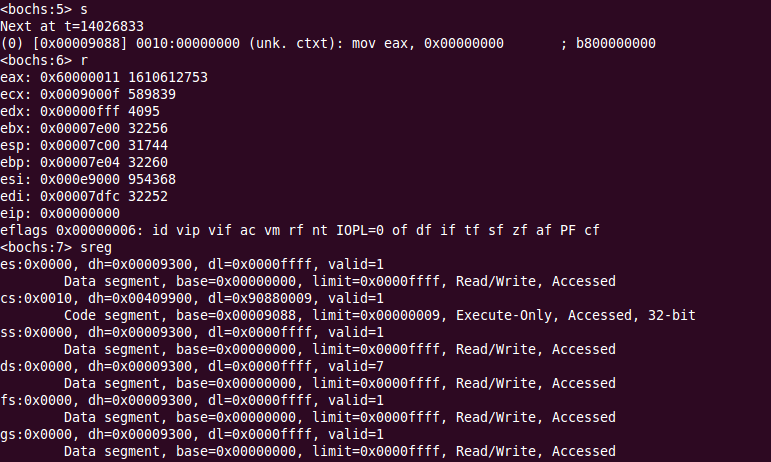
可以看到,cs存储的段选择子变为了0x10,也就是十进制16,这正是第三个段描述符起始地址的偏移(按字节计算),base是0x9088,eip为0。
下面我们来解答两个问题:
1、为什么要在16位代码中给段描述符(描述32位程序段)中的基地址动态赋值,而不是直接使用标签CODE32_SEGMENT?
每个汇编文件当成一个单独的模块来编译,标签是一个地址,这个地址是从文件开头处那个地址计算得到的,在一个文件中我们可以认为标签是绝对地址,例如在loader.asm中,文件开头的地址是0x9000,标签CODE32_SEGMENT就是根据这个0x9000计算出来的。在加载loader.asm的时候,段基址寄存器是0,如果我们加载loader.asm的时候的加载地址为0x9000,这个地址和loader.asm的开头处的重定位的编译地址一样,那么直接使用标签CODE32_SEGMENT给段描述符中的段基址赋值是没有问题的,因为现在的段基址寄存器是0,CODE32_SEGMENT即代表了32位程序的真正的物理地址。 如果加载loader.asm的时候,段基址寄存器不为0,这时候CODE32_SEGMENT和32位程序的真正的物理地址是不同的,直接使用标签赋值是不行的,要想计算出32位程序真正的物理地址,需要有段基址寄存器的参与,因此,为了通用性,必须要在16位程序中动态的计算出32位程序的物理地址。
段描述符中的基地址应该是绝对的物理地址,文件中的标签是相对于文件起始地址计算出来的绝对地址,而不是相对于0地址计算出来的绝对地址,因此,要算出一条指令在内存中的绝对物理地址时,必须要把段寄存器中的基地址考虑进来。
2、为什么16位代码段到32位代码段必须无条件跳转?
从程序中可以看出,如果程序直接执行,也可以从16位代码段顺利过渡到32位代码段,但是为什么要使用跳转呢? 因为CPU执行指令有一个预取机制,一开始是16位执行模式,执行16位代码处的最后一条指令时同时预取了32位代码段的指令,这时CPU可能会误将32位指令当成16位指令执行,造成出错,而jmp无条件跳转会强制刷新流水线,重新对32位指令进行取指,这样可以防止出错。
80386上电时按16位实模式运行,经过设置,可以进入32位的保护模式,不存在16位的保护模式。