1.1 什么是建模
在设计数据库时,对现实世界进行分析、抽象、并从中找出内在联系,进而确定数据库的结构。
1.2 建模在系统中的作用
数据采集、业务处理、数据分析、数据挖掘、数据展现、数据应用、信息管理
1.3 模型技能要求
经验、架构、工具、理论、应用场景
2 业务系统建模
2.1 什么是业务系统 -- OLTP
ERP、网站、物流、淘宝交易、银行柜台
On-Line Transaction Processing 在线处理过程
也成为面向交易的处理过程,基本特征是前台接收用户数据可以立即传送到计算中心进行处理,并在很短的时间内给出处理结构,是对用户操作快速响应的方式之一。
2.2 原始数据
2.2.1 一范式建模
列的原子性:即列不能够再分成其他几列。

2.2.2 二范式建模
行记录唯一性:首先是1NF,一是表必须有一个主键,二是没有包含在主键中的列必须完全依赖于主键,而不能只依赖主键的一部分
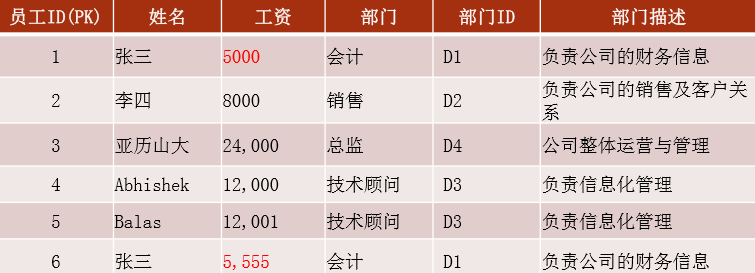
联合主键:多个列组成的主键,例员工ID和部门ID作为联合主键,部门描述依赖联合主键。
2.2.3 三范式建模
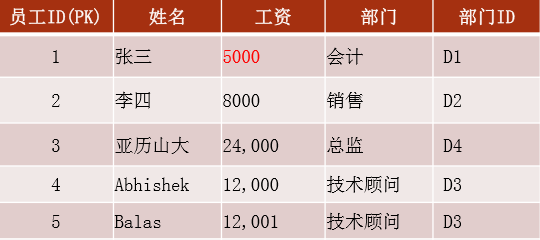
主键唯一依赖,首先时2NF,另外非主键列必须直接依赖于主键,不能存在传递依赖
对上面的表进行拆分,查询时利用部门ID进行关联
员工表:
部门表:
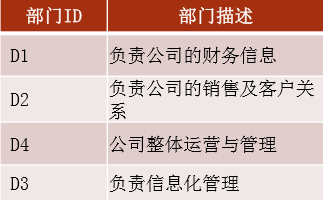
一是加快数据查询速度,二是减少数据查询复杂度,三是降低数据冗余。
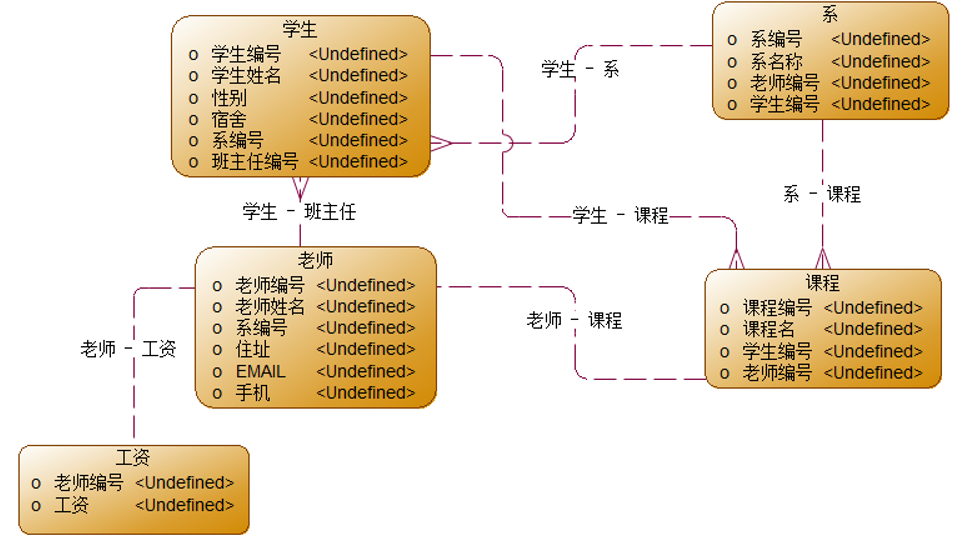
2.2.4 三范式案例
2.2.5 OLTP特点
用于支持业务过程的执行
用来协助企业对响应事件或事务的日常商务活动进行处理。
事件驱动、面向应用的,通常是对一个或一组记录的增、删、改以及简单查询等
应用程序和数据是紧紧围绕着所管理的事件来构造的
数据库要求能支持日常事务中的大量事务,用户对数据的存取操作频率高而每次操 作处理的时间短
2.2.6 接口开发方式
数据库直连
API
FTP文件
2.2.7 大数据量查询优化
按月建表
T-1天数据汇总 + T日实时查询数据
三范式 --> 二范
3 数据仓库维度建模
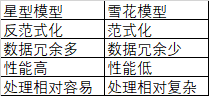
星型模型
事实表 & 维度表
事实表:度量 & 键值
维度表:维度 & 属性
星型模型 vs 三范式建模
星型模型的优势
星型模型的应用-OLAP分析系统
雪花模型
雪花模型 vs 星型模型
3.1 星型模型
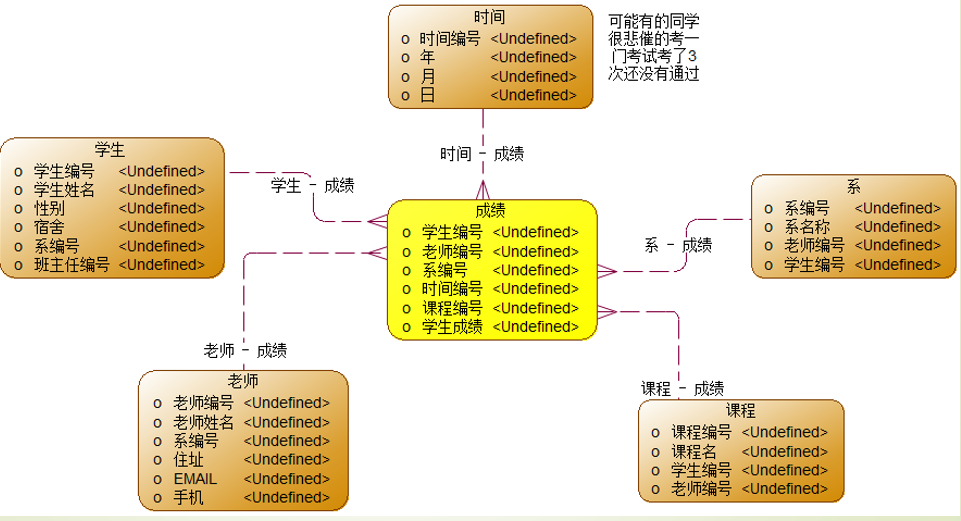
3.2 优势劣势
优势:查询方便、性能提高
劣势:空间换时间、数据移动、非实时
3.3 星型模型的应用
数据仓库、OLAP分析查询系统数据模型
3.4 雪花模型

3.5 星型模型 VS 雪花模型
4 数据仓库体系架构
4.1 数据仓库概念
对数据仓库所下的定义:数据仓库是面向主题的、集成的、稳定的、反应历史变化 的数据集合,用以支持管理决策。
面向主题:销售、财务、人力资源、物流
集成的:用友、金蝶、excel、EAI…
稳定的:不会实时改变,定期批量更新,查询为主
反映历史变化的:有时间戳,变化内容有记录
支持决策:销售分析、业绩排序等
4.2 数据仓库体系架构
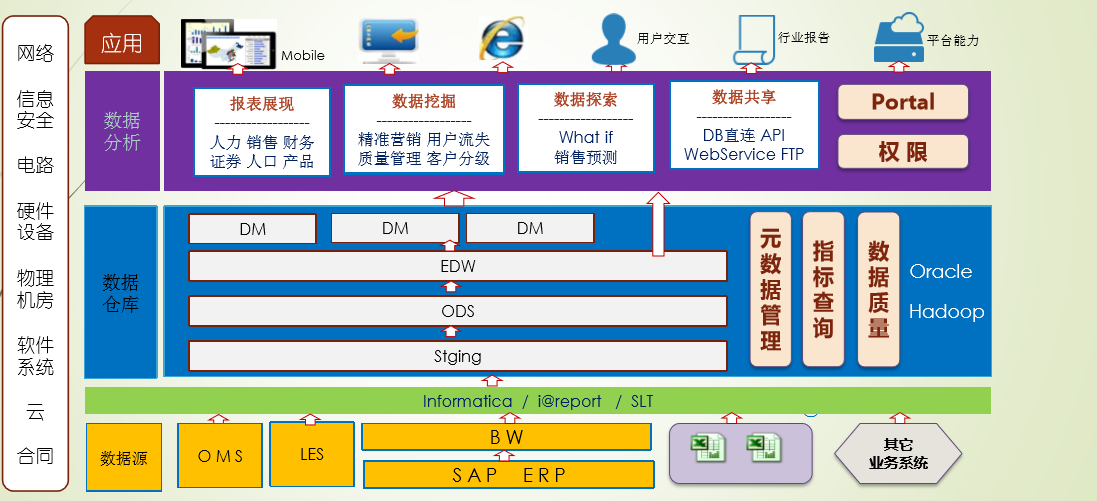
4.3 Staging, ODS, DW, Data Mart4
Staging:数据直抽,与源系隔离
ODS:(Operational Data Storage)
数据清洗、整合
近期明细数据查询
DW:统一、集成、稳定、反应历史变化,支持决策
明细数据
Mini Batch
T-1天数据+实时数据
分布式系统架构
Data Mart:个性化数据应用
4.4 数据仓库应用相关概念
4.4.1 ETL
Extract, Transformation, Load,包括:数据抽取(Data extract)、数据转换 (Data Transformation)、数据清洗(Data cleaning)和数据装载(Data Load)
1 Extract数据抽取:
数据仓库按照主题组织数据,只抽取系统分析需要的数据(多个数据源、按照系统抽取、添加 源系统标志、抽取时间)
1.抽取特定的数据、不影响业务系统的性能(方式、时机、频率)
2.增量抽取、全量抽取
3.oracle、xml、txt、csv、dbf、excel
2 Transform数据转换
1. 不同字段类型、格式等需要统一
2. 数据计算、汇总、内容转换
3. 添加新的属性数据等
3 Cleansing数据清洗:
将错误的、不一致的数据在进入数据仓库之前予以更正或删除,以免影 响系统决策的正确性。
4 数据加载:
负责将数据按照物理数据模型定义的表结构装入数据仓库。
增量加载(交易记录)
全量覆盖(员工权限表)
更新追加(客户收益信息)
5 维度
多维数据集的结构性特性。
它们是事实数据表中用来描述数据的分类的有组织层次结构(级别)。这些分类和级别描述了一 些相似的成员集合,用户将基于这些成员集合进行分析。
6 粒度
级别
是维度层次结构的一个元素。级别描述了数据的层次结构,从数据的最高(汇总程度 最大)级别直到最低(最详细)级别
7 事实表
通过外键与维度表进行关联
很多时候没有单一主键,而是使用外键组合作为事实表的联合主键
外键上通常需要建索引,加快查询速度
包含大量的行
主要特点是包含度量,且这些度量可以汇总
理论上讲事实表不应该包含描述性信息,也不应该包含除数字度量字段及使事实与纬度表中对 应项的相关索引字段之外的任何数据
8 指标、度量
在多维数据集中,度量值是一组值,这些值基于多维数据集的事实数据表中的一列,而且通常 为数字。
度量值是所分析的多维数据集的中心值。即,度量值是最终用户浏览多维数据集时重点查看的 数字数据。您所选择的度量值取决于最终用户所请求的信息类型。常见度量值有 sales、cost、 expenditures
事实表当中的度量大多数情况下都不会超过十个 同一个粒度的数据不一定就会放在同一张表当中(实时交易价格 / 最终收盘价格)
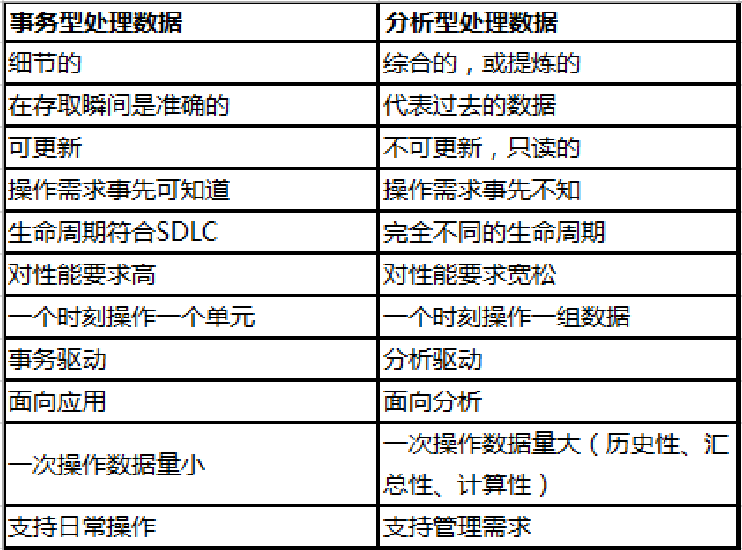
5 OLAP的特点
用于管理人员的决策分析,例如DSS、 EIS和多维分析等。
它帮助决策者分析数据以察看趋向、判断问题。
分析型处理经常要访问大量的历史数据,支持复杂的查询。
在分析型处理中,并不是对从事务型处理环境中得到的细节数据进行分析。细节数据量太大, 会严重影响分析的效率,而且太多的细节数据不利于分析人员将注意力集中于有用的信息。
分析型处理过程中经常用到外部数据,这部分数据不是由事务型处理系统产生的,而是来自于 其他外部数据源。
6 OLAP VS OLTP
7 数据仓库建模代理健
7.1 代理健
定义::当资料表中的候选键都不适合当主键时,(例如资料太长,或是意义层面太多,就会用 一个attribute来当代理主键)来代替可辨识唯一值的主键。
-OLTP流水号
-DW 一般是指维度中使用顺序分配的整数值作为主键
7.2 代理键的作用与好处
-对OLTP系统当中相同业务含义,对不同表示方法的数据进行整合。
-提升性能
1.整型数字通常比业务主键小,提升IO读取效率
2.事实表与维度表关联效率提高
-用于处理缓慢变化维
-可以将一个模型套用在多个类似的项目当中
7.3 代理健的缺点
-增加数据加载的复杂度
-无法通过事实表看到相关维度的业务含义
7.4 代理健的实现方法
-oracle序列
-ETL工具当中的序列
-配一张代理键表,记录下一个代理键的值,然后结合开发程序使用
1.代替序列记录没一张表的最大代理键的值,使用时,通过查询此值后 使用变量为每一个 新增记录分配连续的不断增大的代理键。
2.好处:数据库迁移或更换ETL工具时无需担心seq出问题的情况
3.坏处:难度提高,使用复杂
8 缓慢变化维的概念及产生原因
8.1 缓慢变化维 Slowly Changing Dimensions SCD
8.2 产生原因: 维度的属性并不是静态的,它会随着时间的流失发生缓慢的变化
8.3 缓慢变化维—Type1直接覆盖
-优点:实现容易
-缺点:无法分析历史变化
-处理方法:根据维度表的业务主键直接更新
-使用场景:无需保留历史信息,只需要保存当前信息时使用
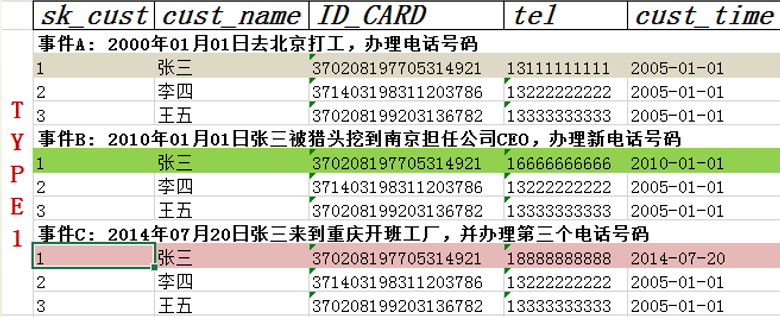
8.4 缓慢变化维—Type2 产生维度变化时添加新记录
-特点:需要代理键的支持
-处理方法:当维度属性发生变化时生成一条新的维度记录
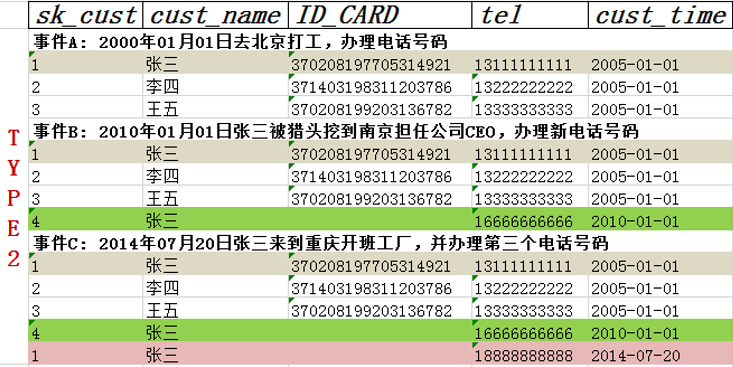
8.5 缓慢变化维—Type3
-Type 3:通过添加属性记录最新的维度属性以及之前一条的维度属性
1.特点:对需要分析的历史信息添加属性
2.优点:同时分析单签及上一次变化的属性值
3.缺点:只保留了最后一次变化信息
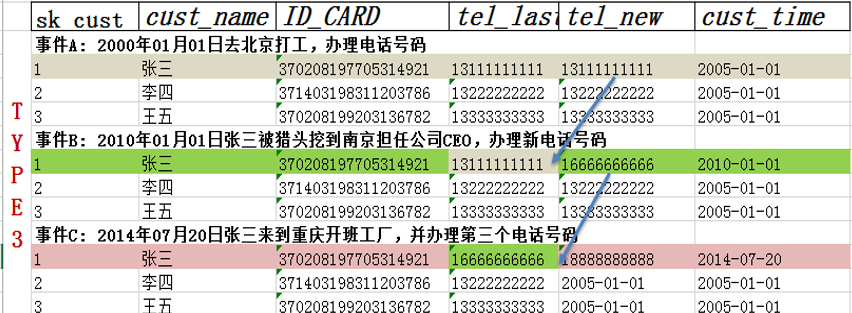
8.6 缓慢变化维—Type6
-结合了Type1的更新
-结合了Type2的新插入数据
-结合了Type3的保留上一次记录
-衍生出保留全部历史记录
