转自【http://www.cnblogs.com/mouse-coder/p/3451243.html】
最近在做一个小项目,使用到XML文件解析技术,通过对该技术的了解和使用,总结了以下内容。
1 XML文件解析的4种方法
通常解析XML文件有四种经典的方法。基本的解析方式有两种,一种叫SAX,另一种叫DOM。SAX是基于事件流的解析,DOM是基于XML文档树结构的解析。在此基础上,为了减少DOM、SAX的编码量,出现了JDOM,其优点是,20-80原则(帕累托法则),极大减少了代码量。通常情况下JDOM使用时满足要实现的功能简单,如解析、创建等要求。但在底层,JDOM还是使用SAX(最常用)、DOM、Xanan文档。另外一种是DOM4J,是一个非常非常优秀的Java XML API,具有性能优异、功能强大和极端易用的特点,同时它也是一个开放源代码的软件。如今你可以看到越来越多的 Java 软件都在使用 DOM4J 来读写 XML,特别值得一提的是连 Sun 的 JAXM 也在用 DOM4J。具体四种方法的使用,百度一下,会有众多详细的介绍。可以参考SMCwwh对以上技术的详细介绍,http://blog.csdn.net/smcwwh/article/details/7183869#part3。
2 XPath简单介绍
XPath 是一门在 XML 文档中查找信息的语言。XPath 用于在 XML 文档中通过元素和属性进行导航,并对元素和属性进行遍历。XPath 是 W3C XSLT 标准的主要元素,并且 XQuery 和 XPointer 同时被构建于 XPath 表达之上。因此,对 XPath 的理解是很多高级 XML 应用的基础。XPath非常类似对数据库操作的SQL语言,或者说JQuery,它可以方便开发者抓起文档中需要的东西。其中DOM4J也支持XPath的使用。XPath的具体使用教程可以参考http://www.w3school.com.cn/xpath/index.asp。
3 DOM4J使用XPath
DOM4J使用XPath解析XML文档是,首先需要在项目中引用两个JAR包:
dom4j-1.6.1.jar:DOM4J软件包,下载地址http://sourceforge.net/projects/dom4j/;
jaxen-xx.xx.jar:通常不添加此包,会引发异常(java.lang.NoClassDefFoundError: org/jaxen/JaxenException),下载地址http://www.jaxen.org/releases.html。
3.1 命名空间(namespace)的干扰
在处理由excel文件或其他格式文件转换的xml文件时,通常会遇到通过XPath解析得不到结果的情况。这种情况通常是由于命名空间的存在导致的。以下述内容的XML文件为例,通过XPath=" // Workbook/ Worksheet / Table / Row[1]/ Cell[1]/Data[1] "进行简单的检索,通常是没有结果出现的。这就是由于命名空间namespace(xmlns="urn:schemas-microsoft-com:office:spreadsheet")导致的。

<Workbook xmlns="urn:schemas-microsoft-com:office:spreadsheet" xmlns:o="urn:schemas-microsoft-com:office:office" xmlns:x="urn:schemas-microsoft-com:office:excel" xmlns:ss="urn:schemas-microsoft-com:office:spreadsheet" xmlns:html="http://www.w3.org/TR/REC-html40">
<Worksheet ss:Name="Sheet1">
<Table ss:ExpandedColumnCount="81" ss:ExpandedRowCount="687" x:FullColumns="1" x:FullRows="1" ss:DefaultColumnWidth="52.5" ss:DefaultRowHeight="15.5625">
<Row ss:AutoFitHeight="0">
<Cell>
<Data ss:Type="String">敲代码的耗子</Data>
</Cell>
</Row>
<Row ss:AutoFitHeight="0">
<Cell>
<Data ss:Type="String">Sunny</Data>
</Cell>
</Row>
</Table>
</Worksheet>
</Workbook>
3.2 XPath对带有命名空间的xml文件解析
第一种方法(read1()函数):使用XPath语法中自带的local-name() 和 namespace-uri() 指定你要使用的节点名和命名空间。 XPath表达式书写较为麻烦。
第二种方法(read2()函数):设置XPath的命名空间,利用setNamespaceURIs()函数。
第三种方法(read3()函数):设置DocumentFactory()的命名空间 ,使用的函数是setXPathNamespaceURIs()。二和三两种方法的XPath表达式书写相对简单。
第四种方法(read4()函数):方法和第三种一样,但是XPath表达式不同(程序具体体现),主要是为了检验XPath表达式的不同,主要指完整程度,是否会对检索效率产生影响。
(以上四种方法均通过DOM4J结合XPath对XML文件进行解析)
第五种方法(read5()函数):使用DOM结合XPath对XML文件进行解析,主要是为了检验性能差异。
没有什么能够比代码更能说明问题的了!果断上代码!
1 package XPath;
2 import java.io.IOException;
3 import java.io.InputStream;
4 import java.util.HashMap;
5 import java.util.List;
6 import java.util.Map;
7
8 import javax.xml.parsers.DocumentBuilder;
9 import javax.xml.parsers.DocumentBuilderFactory;
10 import javax.xml.parsers.ParserConfigurationException;
11 import javax.xml.xpath.XPathConstants;
12 import javax.xml.xpath.XPathExpression;
13 import javax.xml.xpath.XPathExpressionException;
14 import javax.xml.xpath.XPathFactory;
15
16 import org.dom4j.Document;
17 import org.dom4j.DocumentException;
18 import org.dom4j.Element;
19 import org.dom4j.XPath;
20 import org.dom4j.io.SAXReader;
21 import org.w3c.dom.NodeList;
22 import org.xml.sax.SAXException;
23
24 /**
25 * DOM4J DOM XML XPath
26 * @author hao
27 */
28 public class TestDom4jXpath {
29 public static void main(String[] args) {
30 read1();
31 read2();
32 read3();
33 read4();//read3()方法一样,但是XPath表达式不同
34 read5();
35 }
36
37 public static void read1() {
38 /*
39 * use local-name() and namespace-uri() in XPath
40 */
41 try {
42 long startTime=System.currentTimeMillis();
43 SAXReader reader = new SAXReader();
44 InputStream in = TestDom4jXpath.class.getClassLoader().getResourceAsStream("XPath\XXX.xml");
45 Document doc = reader.read(in);
46 /*String xpath ="//*[local-name()='Workbook' and namespace-uri()='urn:schemas-microsoft-com:office:spreadsheet']"
47 + "/*[local-name()='Worksheet']"
48 + "/*[local-name()='Table']"
49 + "/*[local-name()='Row'][4]"
50 + "/*[local-name()='Cell'][3]"
51 + "/*[local-name()='Data'][1]";*/
52 String xpath ="//*[local-name()='Row'][4]/*[local-name()='Cell'][3]/*[local-name()='Data'][1]";
53 System.err.println("=====use local-name() and namespace-uri() in XPath====");
54 System.err.println("XPath:" + xpath);
55 @SuppressWarnings("unchecked")
56 List<Element> list = doc.selectNodes(xpath);
57 for(Object o:list){
58 Element e = (Element) o;
59 String show=e.getStringValue();
60 System.out.println("show = " + show);
61 long endTime=System.currentTimeMillis();
62 System.out.println("程序运行时间: "+(endTime-startTime)+"ms");
63 }
64 } catch (DocumentException e) {
65 e.printStackTrace();
66 }
67 }
68
69 public static void read2() {
70 /*
71 * set xpath namespace(setNamespaceURIs)
72 */
73 try {
74 long startTime=System.currentTimeMillis();
75 Map map = new HashMap();
76 map.put("Workbook","urn:schemas-microsoft-com:office:spreadsheet");
77 SAXReader reader = new SAXReader();
78 InputStream in = TestDom4jXpath.class.getClassLoader().getResourceAsStream("XPath\XXX.xml");
79 Document doc = reader.read(in);
80 String xpath ="//Workbook:Row[4]/Workbook:Cell[3]/Workbook:Data[1]";
81 System.err.println("=====use setNamespaceURIs() to set xpath namespace====");
82 System.err.println("XPath:" + xpath);
83 XPath x = doc.createXPath(xpath);
84 x.setNamespaceURIs(map);
85 @SuppressWarnings("unchecked")
86 List<Element> list = x.selectNodes(doc);
87 for(Object o:list){
88 Element e = (Element) o;
89 String show=e.getStringValue();
90 System.out.println("show = " + show);
91 long endTime=System.currentTimeMillis();
92 System.out.println("程序运行时间: "+(endTime-startTime)+"ms");
93 }
94 } catch (DocumentException e) {
95 e.printStackTrace();
96 }
97 }
98
99 public static void read3() {
100 /*
101 * set DocumentFactory() namespace(setXPathNamespaceURIs)
102 */
103 try {
104 long startTime=System.currentTimeMillis();
105 Map map = new HashMap();
106 map.put("Workbook","urn:schemas-microsoft-com:office:spreadsheet");
107 SAXReader reader = new SAXReader();
108 InputStream in = TestDom4jXpath.class.getClassLoader().getResourceAsStream("XPath\XXX.xml");
109 reader.getDocumentFactory().setXPathNamespaceURIs(map);
110 Document doc = reader.read(in);
111 String xpath ="//Workbook:Row[4]/Workbook:Cell[3]/Workbook:Data[1]";
112 System.err.println("=====use setXPathNamespaceURIs() to set DocumentFactory() namespace====");
113 System.err.println("XPath:" + xpath);
114 @SuppressWarnings("unchecked")
115 List<Element> list = doc.selectNodes(xpath);
116 for(Object o:list){
117 Element e = (Element) o;
118 String show=e.getStringValue();
119 System.out.println("show = " + show);
120 long endTime=System.currentTimeMillis();
121 System.out.println("程序运行时间: "+(endTime-startTime)+"ms");
122 }
123 } catch (DocumentException e) {
124 e.printStackTrace();
125 }
126 }
127
128 public static void read4() {
129 /*
130 * 同read3()方法一样,但是XPath表达式不同
131 */
132 try {
133 long startTime=System.currentTimeMillis();
134 Map map = new HashMap();
135 map.put("Workbook","urn:schemas-microsoft-com:office:spreadsheet");
136 SAXReader reader = new SAXReader();
137 InputStream in = TestDom4jXpath.class.getClassLoader().getResourceAsStream("XPath\XXX.xml");
138 reader.getDocumentFactory().setXPathNamespaceURIs(map);
139 Document doc = reader.read(in);
140 String xpath ="//Workbook:Worksheet/Workbook:Table/Workbook:Row[4]/Workbook:Cell[3]/Workbook:Data[1]";
141 System.err.println("=====use setXPathNamespaceURIs() to set DocumentFactory() namespace====");
142 System.err.println("XPath:" + xpath);
143 @SuppressWarnings("unchecked")
144 List<Element> list = doc.selectNodes(xpath);
145 for(Object o:list){
146 Element e = (Element) o;
147 String show=e.getStringValue();
148 System.out.println("show = " + show);
149 long endTime=System.currentTimeMillis();
150 System.out.println("程序运行时间: "+(endTime-startTime)+"ms");
151 }
152 } catch (DocumentException e) {
153 e.printStackTrace();
154 }
155 }
156
157 public static void read5() {
158 /*
159 * DOM and XPath
160 */
161 try {
162 long startTime=System.currentTimeMillis();
163 DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
164 dbf.setNamespaceAware(false);
165 DocumentBuilder builder = dbf.newDocumentBuilder();
166 InputStream in = TestDom4jXpath.class.getClassLoader().getResourceAsStream("XPath\XXX.xml");
167 org.w3c.dom.Document doc = builder.parse(in);
168 XPathFactory factory = XPathFactory.newInstance();
169 javax.xml.xpath.XPath x = factory.newXPath();
170 //选取所有class元素的name属性
171 String xpath = "//Workbook/Worksheet/Table/Row[4]/Cell[3]/Data[1]";
172 System.err.println("=====Dom XPath====");
173 System.err.println("XPath:" + xpath);
174 XPathExpression expr = x.compile(xpath);
175 NodeList nodes = (NodeList)expr.evaluate(doc, XPathConstants.NODE);
176 for(int i = 0; i<nodes.getLength();i++) {
177 System.out.println("show = " + nodes.item(i).getNodeValue());
178 long endTime=System.currentTimeMillis();
179 System.out.println("程序运行时间: "+(endTime-startTime)+"ms");
180 }
181 } catch(XPathExpressionException e) {
182 e.printStackTrace();
183 } catch(ParserConfigurationException e) {
184 e.printStackTrace();
185 } catch(SAXException e) {
186 e.printStackTrace();
187 } catch(IOException e) {
188 e.printStackTrace();
189 }
190 }
191 }
3.3 不同方法的性能比较
为了比较几种方法的解析性能,实验过程中使用了6M以上大小,7万行以上的XML文件(XXX.xml)进行10轮测试,如下所述:
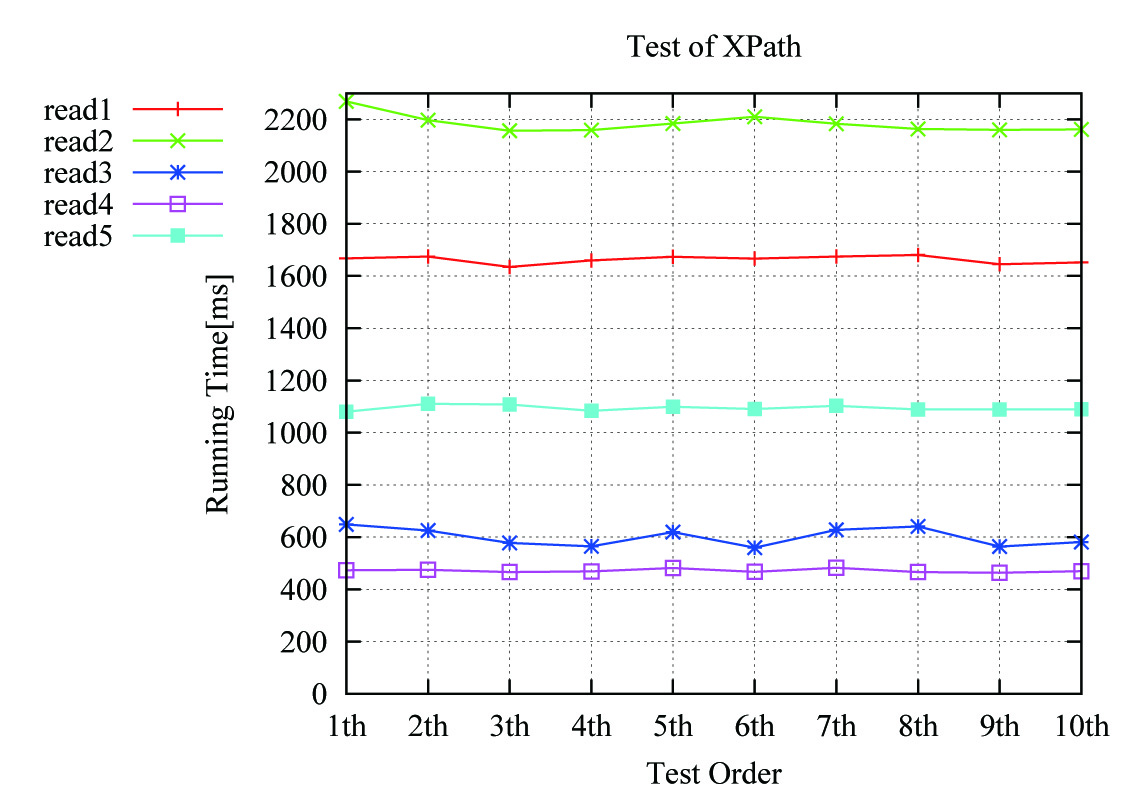
图1 XPath使用性能对比
|
方法名称 |
平均运行时间 |
XPath表达式 |
|
read1() |
1663ms |
//*[local-name()='Row'][4]/*[local-name()='Cell'][3]/*[local-name()='Data'][1] |
|
read2() |
2184ms |
//Workbook:Row[4]/Workbook:Cell[3]/Workbook:Data[1] |
|
read3() |
601ms |
//Workbook:Row[4]/Workbook:Cell[3]/Workbook:Data[1] |
|
read4() |
472ms |
//Workbook:Worksheet/Workbook:Table/Workbook:Row[4]/Workbook:Cell[3]/Workbook:Data[1] |
|
read5() |
1094ms |
//Workbook/Worksheet/Table/Row[4]/Cell[3]/Data[1] |
表1 平均性能统计
由以上性能对比可知:
1、read4()方法运行时间最短,即运用DOM4J方法调用全路径(从根节点出发)XPath表达式解析XML文件耗时最短;
2、运用DOM解析方法所使用的XPath表达式最为简单(可以写作//Row[4]/Cell[3]/Data[1]),因DOM中可以通过setNamespaceAware(false)方法使命名空间失效。