项目参考唐老师手写识别项目及数据集。
数据集是:mnist-demo.csv
具体的实验步骤:
1.读取数据集文件,shape为:(10000, 785),样式为:

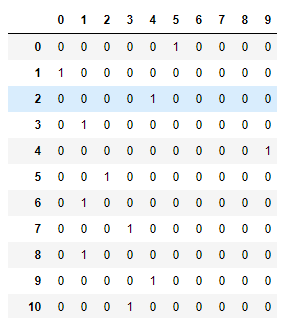
进行one-hot编码,将Label转化成 :
import pandas as pd import numpy as np data=pd.read_csv("mnist-demo.csv") label=pd.get_dummies(data["label"]) X=data.iloc[0:,1:] Y=label
2.使用Keras进行训练测试
from tensorflow import keras from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense,Dropout,Flatten,Conv2D,MaxPool2D from tensorflow.keras import Input from sklearn.model_selection import train_test_split from sklearn.utils import shuffle from tensorflow.keras.regularizers import l1
model = Sequential() # 第一个卷积层,32个卷积核,大小5x5,卷积模式SAME,激活函数relu,输入张量的大小 # model.add(Conv2D(filters= 6, kernel_size=(3,3), padding='valid',kernel_regularizer=l1(0.1),activation='tanh',input_shape=(128,128,3))) # # model.add(Conv2D(filters= 32, kernel_size=(3,3), padding='valid', activation='relu')) # # 池化层,池化核大小2x2 # model.add(MaxPool2D(pool_size=(2,2))) # # 随机丢弃四分之一的网络连接,防止过拟合 # model.add(Dropout(0.5)) # model.add(Conv2D(filters= 6, kernel_size=(3,3), padding='Same', activation='tanh')) # # model.add(Conv2D(filters= 6, kernel_size=(3,3), padding='Same', activation='tanh')) # model.add(MaxPool2D(pool_size=(2,2), strides=(2,2))) # model.add(Dropout(0.5)) # # 全连接层,展开操作, # model.add(Flatten()) # 添加隐藏层神经元的数量和激活函数 model.add(Dense(120, activation='tanh',input_shape=(784,))) model.add(Dense(84, activation='tanh')) # 输出层 model.add(Dense(10, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.fit(X,Y,validation_split=0.2,batch_size=100,epochs=50)
训练结果如下:
