(继续贴一篇之前写的经验案例)
elastic-job lite 编程实战经验
其实这是一次失败的项目,虽然最后还是做出来了,但是付出了很大代价。并且需要较深入的踩坑改造elastic-job,导致代码的可读性,可维护性也很差。
事实证明 elastic-job lite 并不适合用于做 需要长时间运行(可能几小时或几天不停止)的作业调度。
一、 elastic-job 简介
Elastic-Job是当当推出的一个开源分布式调度解决方案,由两个相互独立的子项目Elastic-Job-Lite和Elastic-Job-Cloud组成。Elastic-Job-Lite定位为轻量级无中心化解决方案。
详见官网介绍,传送门http://elasticjob.io/docs/elastic-job-lite/00-overview/intro/
本文从编程踩坑和大量测试中提炼,讲解目的在于帮助有基础的开发者理解elastic-job真实的运行逻辑,解答编程中官方文档未提及的疑惑,避免重复踩坑。基础的概念和高深的主从节点选举失效转移不是本文要讲的内容,请移步官方文档,本文更专注于怎么用对。
二、 elastic-job 与 zookeeper
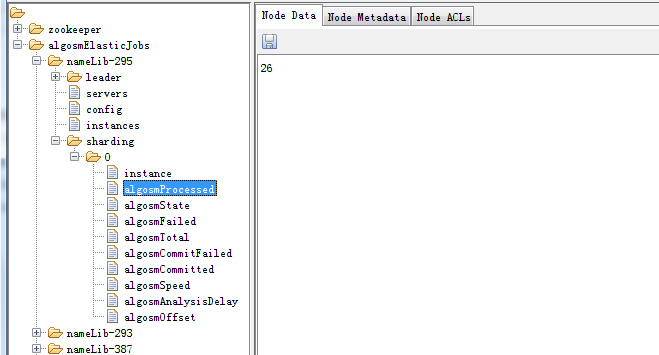
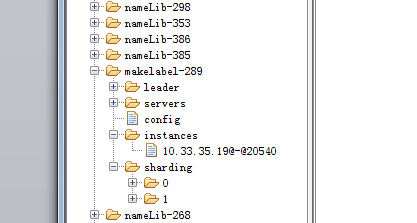
elastic-job 基于zk实现分布式协调,重要的作业信息都被存储在了zk上,如图:
algosmElasticJobs 节点是自定义的命名空间的名称。
nameLib-295是作业名
servers 通过子节点记录作业在哪几台机器上正在运行,一个机器对应一个子节点,运行结束后,servers子节点会被删除。
instances 记录了job实例与机器的关系
config 存储作业的配置信息
sharding 展开 是作业的分片信息,及每个分片运行在哪个机器上,与运行状态。
每个作业对应命名空间algosmElasticJobs下的一个子节点(节点名称为作业名)


三、 elastic-job 作业、分片与线程
作业运行起来后,服务器、实例、线程、分片的关系图:
(2台服务器,每台运行2个作业,每个作业4个分片)
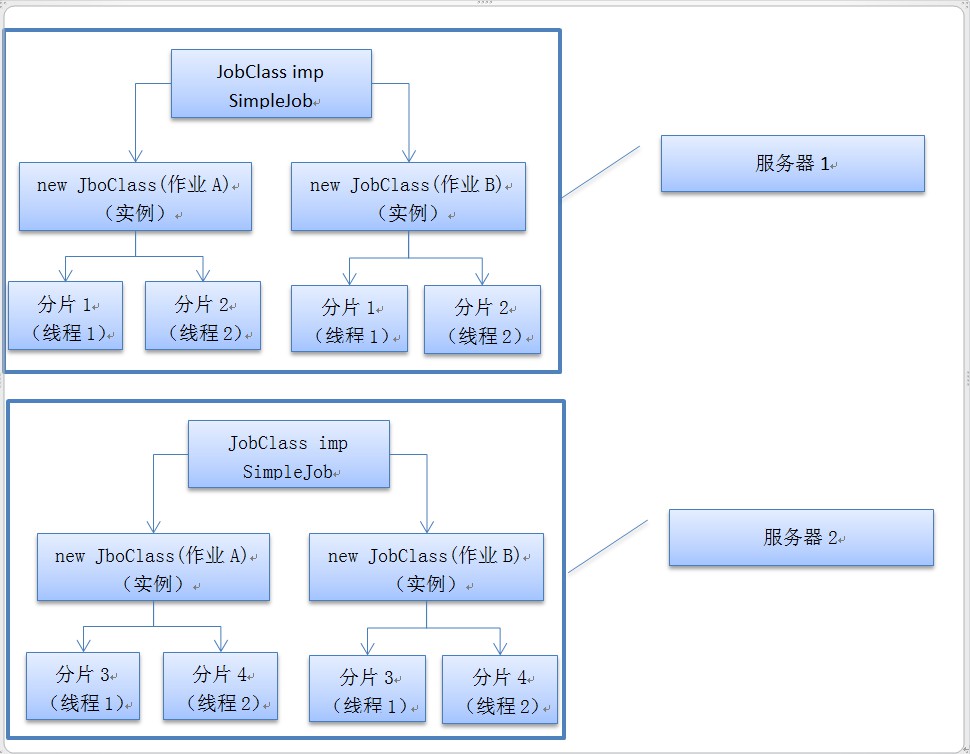
1)作业 job : 实现作业逻辑的class类,需重写execute(ShardingContext shardingContext) 方法。
elastic-job创建一个作业时,会在当前服务器上拉起一个作业class的实例,并需要为该实例指定唯一的作业名称。(如下图所示作业名称各不相同)
同一个class可以创建多个实例,从而生成多个作业(各个作业的名称不同,作业自定义配置也可设置的不一样)。
如下图 nameLib 开头的是由ClassA 生成, makelabel是由ClassB生成。
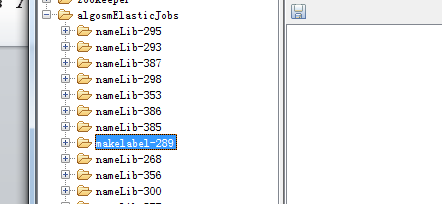
2)分片 sharding:
创建作业时,需要设置这个作业有多少个分片来执行,如果作业A在机器1上获得了两个分片,那么这两个分片实际上是两个线程(注意是一台机器上获得两个分片,每台机器上装一个elastic-job 服务的情况下),这两个线程共用的是同一个class实例,也就是说这两个分片 会共享 此class实例的成员变量。分片1修改了实例的成员变量,就会被分片2读到,从而影响分片2的作业逻辑。
如果想要为每个分片设置独享的变量,从而不受到其他分片影响,那么就需要用到线程变量。
方法是,在该class中定义线程变量,用法如下:
/**
* 与线程相关的变量, key 线程号
*/
private Map<Long,JobBaseParam> threadParam = new ConcurrentHashMap<>();
//初始化线程变量
private void initParam(ShardingContext shardingContext){
//elasticJob 单实例多线程,每次拉起需要清理线程上次残留的状态
JobBaseParam jobBaseParam = new JobBaseParam();
jobBaseParam.setShardingItem(shardingContext.getShardingItem());
jobBaseParam.setCompletedActive(false);
jobBaseParam.setOver(true);
jobBaseParam.setReceiveOver(false);
threadParam.put(Thread.currentThread().getId(),jobBaseParam);
jobName = shardingContext.getJobName();
}
//使用线程变量
threadParam.get(Thread.currentThread().getId()).setCompletedActive(true);
threadParam.get(masterThreadId).getReceiveOver()
线程变量使用时,需小心:在哪个线程里threadParam.put的变量,就需要在哪个线程里threadParam.get,例如在主线程里put变量,然后在子线程里get变量,就会get不到,产生逻辑错误。
关于作业Class中的静态变量,该静态变量将会被由改class new出来的所有作业分片读到,作用域范围最大。
jobClass不同变量作用域:
|
变量类型 |
静态变量 |
成员变量 |
线程变量 |
|
作用域 |
所有作业实例、所有分片 |
当前作业实例的所有分片 |
当前分片 |
如果想要长久保留分片要用的变量,每次分片拉起时自动从上一次状态继续,可以将与分片相关的变量存储到zk上,作业对应的分片节点下面,类似:
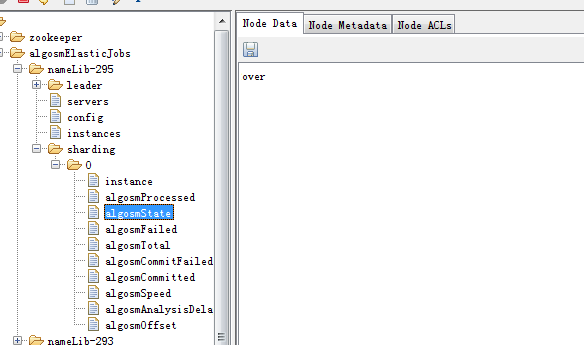
algosm是自定义的前缀标识,以与elastic-job管理的节点区分。注意分片下加自定义节点,是不会影响elastic-job运行的,也不会被elastic-job 清除,是可行的方案。
四、 elastic-job 分片与失效转移
想要作业A失效转移生效,前提是每台服务器上都要在运行着作业A。
分片序号从0开始,当服务器1同时获得两个分片,分片1执行完毕,分片2未结束的情况下,分片1不会被再次触发,一直要等到分片2结束。
经典模式,正常运行时,会随机分片,导致作业分片在不同机器上切换。
作业的两个分片在同一台服务器上时,分片1与分片2用的是同一实例,不同线程,若有状态残留在实例的成员变量中,需要小心,建议分片每次运行都要初始化一次状态。
五、 elastic-job 作业重启恢复
elastic-job 如果发生重启,是不会自动将作业拉起的,虽然其作业配置存储到了zk上,需要自行实现重启,拉起作业功能。
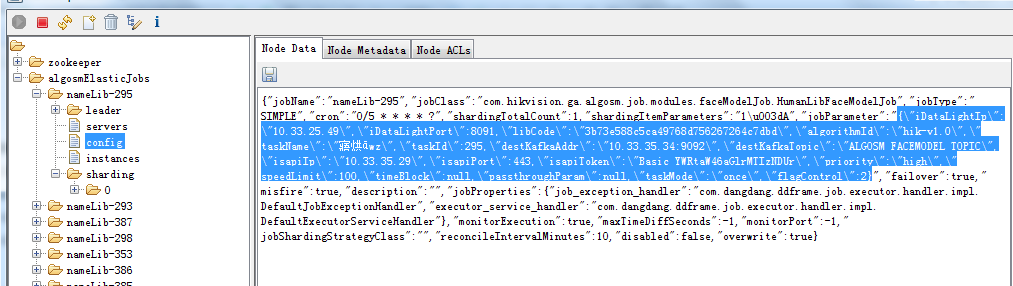
实现要点,是要判断作业是否为异常结束,非正常销毁的作业,会在servers节点下残留子节点,如果servers的子节点不为空,说明是异常停止,需要被拉起
config节点中存储了作业的配置信息
实战代码如下:
(代码中jobPool是自行实现的一个作业池用来管理作业的实例,jobPoolLock是自行实现的细粒度锁)
@Override
public Boolean loadPreJob(){
try {
String rootPath = "/"+algosmJobConfig.getRegCenterNamespace();
if(!zkClient.exists(rootPath)){
logger.info("初次运行,未发现{}",rootPath);
return true;
}
List<String> zkJobList = zkClient.getChildren(rootPath);
if(!CollectionUtils.isEmpty(zkJobList)){
for(String jobName : zkJobList){
try{
String jobPath = rootPath+"/"+jobName;
//只要servers 不是空的,就说明作业非正常终止,需要将作业拉起来
if(!CollectionUtils.isEmpty(zkClient.getChildren(jobPath+"/servers"))){
//说明是非正常结束的job,需要拉起
String jobConfig = zkClient.readData(jobPath+"/config",true);
if(StringUtils.isEmpty(jobConfig)){
logger.warn("job=[{}] config为空",jobName);
}else{
//取出参数
JsonNode jobNode = jsonTool.readTree(jobConfig);
String jobParam = jobNode.get("jobParameter").textValue();
//创建任务
String[] jobInfo = jobName.split("-");
if(jobInfo.length != 2 || AlgosmJobType.trans(jobInfo[0])==null){
logger.warn("jobName={} 命名非法",jobName);
}else{
jobPoolLock.lock(jobName);
try{
logger.info("初始化-加载job {}",jobName);
if(jobPool.containsKey(jobName)){
logger.warn("job={}已存在,跳过!",jobName);
}else{
JobEntityConfig jobEntityConfig = jobControl.createJob(jobName,AlgosmJobType.trans(jobInfo[0]),jobParam);
JobScheduler jobScheduler = new SpringJobScheduler(jobEntityConfig.getJobEntity(),
zookeeperRegistryCenter, jobEntityConfig.getJobConfiguration(), new AlgosmElasticJobListener());
jobScheduler.init();
jobPool.put(jobName,jobEntityConfig.getJobEntity());
logger.info("加载job={}成功! param={}",jobName,jobParam);
}
}finally {
jobPoolLock.unlock(jobName);
}
}
}
}
}catch (Exception e){
logger.error("加载作业失败!jobName={}",jobName,e);
continue;
}
}
}
}catch (Exception e){
logger.error("初始化加载作业失败!",e);
return false;
}
return true;
}
六、 elastic-job 分布式作业控制与任务状态统计
如何控制所有机器上作业的启停,如何获取当前作业的运行状态,考虑到作业是运行在多台机器上的,所以挂了一台,作业并不算停止。作业运行也并非所有机器都在跑就算运行,作业跑在不同机器上,每个机器上又可能不止一个分片所有分片的任务统计数据叠加,才算是作业准确的统计数据。
这块是需要自行实现的,elastic-job是不支持的。笔者已实现该部分功能,限于篇幅与时间限制,等下篇再讲述。(卖个关子,从下图分片中的自定义节点命名可看出一二)。