一.分页优化技术
代码参看: php/classic.php
把50331651记录进行分页,每页显示2条记录,于是我们用传统php编码方式,编写分页代码如下:
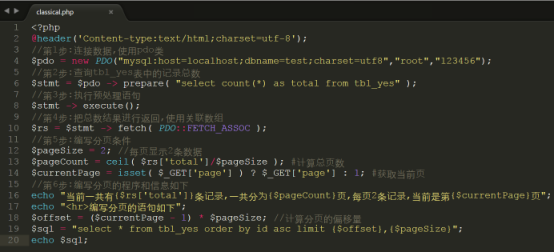
上传到/var/www/html下进行测试,结果如下:
如果访问第1页和第4页,返回语句:


使用explain执行计划查询比较靠前的页数,发觉速度很快因为可以使用上索引:


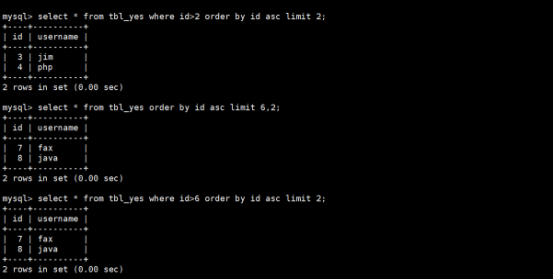
如果访问第4100000页,返回语句:

使用explain分析结果如下:


发觉这时如果分页到了中间的页数,这时我们既需要排序又要分页检索数据的时候,就会出现Using filesort的选项,这选项的出现导致分页在中间页面的时候使用不上索引,因此出现全表扫描的过程,所以这个语句的查询效率就大大的降低了,我们在工作中如果遇到ALL的全表扫描我们就必须优化这条语句,优化语句必须遵循一个理念:让慢语句使用上索引,使得ALL消失,但功能不能发生改变,这时我们应该如何优化,这时我们可以把分页语句调整如下优化:
分页传统的公式如下: order by id asc + limit 偏移量,长度
分页优化的公式如下: where id>偏移量 + order by id asc+ limit 长度
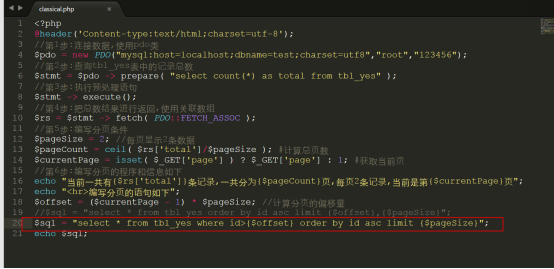
查询第4100000页得到的结果如下:

经过优化后的算法,使用explain进行分析,可以得到如下结果:
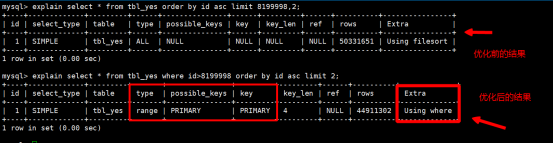
发觉Using filesort被修改为Using Where因此分页优化得到提升,所以我们将来在开发的过程中如果需要分页的数据达到千万的级别时,我们就需要使用以下优化分页公式:
分页优化的公式如下: where id>偏移量 + order by id asc + limit 长度
但是什么还要知道当前的算法查询的记录是否准确:
二.MyISAM的表锁和库存优化
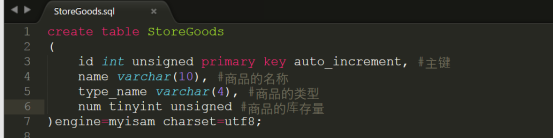
在现实开发当中,电子商务网站会有一个抢购的活动,如果有一个id=4并且库存量只有1的商品给用户进行抢购,那么这时有可能当所有的用户同时进行抢购的时候就会发生一种叫做并发的行为,这时会导致很多的用户同时抢购一个商品成功,为了防止这个情况,确保只能有一个人抢购成功,我们就需要使用Myisam中的表锁,建立表结构和数据如下:
代码参考: code/StoreGoods.sql
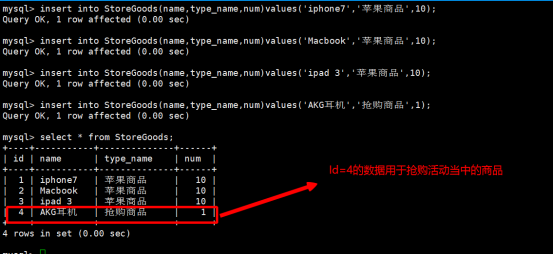
插入相关的测试数据如下:
于是我们传统编写的抢购代码如下所示:
代码参考: code/goods.php
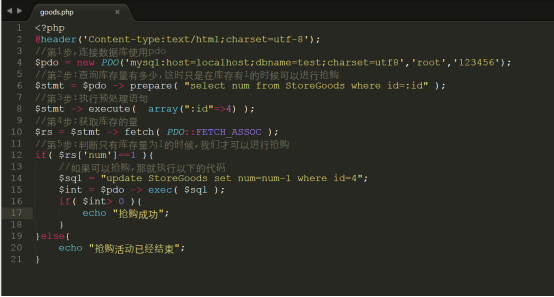
问题来了:如果这时发生了并非的行为,那么其实有可能有大部分的用户,可以进入抢购的update代码当中,那么这时有可能发生多人抢购成功,并且库存变为负数的情况,这时如果需要避免这个结果的产生,我们需要加上表锁,把代码修改如下:
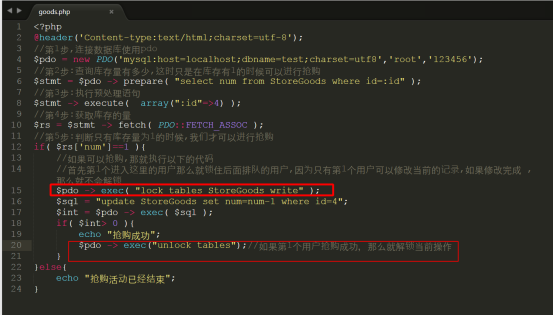
把代码上传到/var/www/html下,测试如下:

如果成功抢购,那么继续刷新就会提示以下结果:
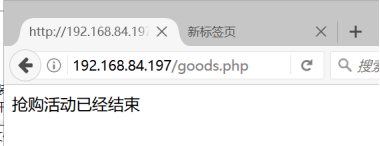
三.数据的列(字段)数据类型的正确选择
1.数值数据类型
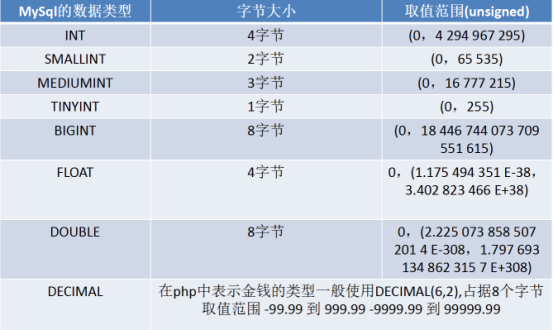
在表的建立中数值数据选取原则
人的年龄可以选择:
人一般很难超过139岁,如果你选择int类型来存储就是占用4个字节,如果1000条记录的大小就是4*1000=4000字节,如果你选择tinyint就只有1个字节,1000条记录只有1000字节的大小比原来int节约了4倍的存储空间,因此人的年龄选择tinyint
乌龟的年龄可以选择:
乌龟最短年龄也可以超过500年,所以tinyint无法存储乌龟的年龄,因此我们可以选择smallint来存储,这时其实理论上可以保存万年神龟的年龄
主键可以选择:
假设是一个小学生的博客系统,那么其实主键id选择tinyint即可,因为小学生很难写超过100篇文章,如果是技术人员的技术博客都属于一些个人的笔记,所以我们选择smallint作为主键的id就够了,因为一般人很难写超过2000篇文章,就算是金庸写的博客也很难超过,假设你个人开发了一个商城网站,专卖手机产品,那么应该选择smallint,如果是一个间小公司的电子商务(中山壹加壹连锁超市)可以选择MEDIUMINT,如果你开发是京东商城那么请选择int做主键
金钱可以选择:
如果遇到存储货币或者金钱类型的字段,想都不用想使用DECIMAL(6,2)
2.时间和日期数据类型的大小
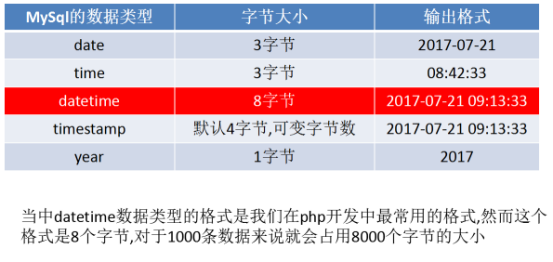
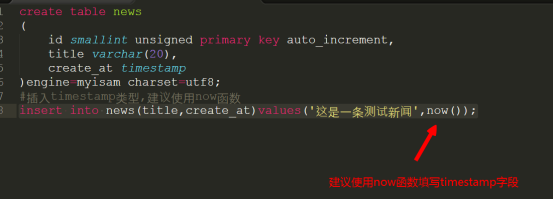
如果将来还需要用到时间的字段,建议直接使用timestamp,如果你使用int虽然也是4个字节,然而int存储的是Unix时间戳,那么就意味你有一个php代码的转化过程,非常的麻烦,而timestamp依然是4个字节但这个字段不需要你做任何的转化,只需要使用一个mysql中的数据库函数叫now()就可以完成.
对mysql的timestamp字段插入数据,会发觉存在2个问题:
代码参考: code/timestamp.sql
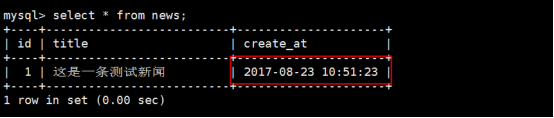
这时以上的时间有可能不对的,因为在linux当中我们安装时候,安装一般是系统时间,在linux修改时间需要同时修改系统时间和硬件时间,修改Linux的时间,需要使用以下两个命令:
假设我们需要把Linux的时间修改为2017-08-22 08:13:52秒
1)使用date命令

date在没有任何的选项的时候,是用于查询系统时间,发觉这个时间不是我们想要的时间,因此我们可以使用date -s来进行时间的设置,-s是修改系统时间的选项


CST的意思是中国沿海时间的时区,一般在linux当中我们使用中国时区都使用CST
2)使用clock --show命令显示linux硬件时间
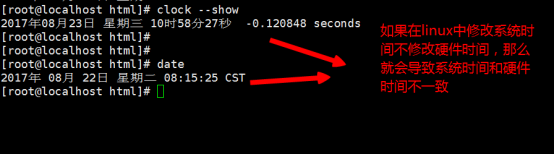
以上问题,可以会在开发当中获取的时间产生bug,因此我们需要同步系统和硬件时间为一致的时间,使用clock --systohc同步,--systohc就是把系统时间和硬件时间进行同步的选项:
执行命令,如下 :

这时再次对比系统时间和硬件时间如下:

如果我们把字段的时间类型修改为timestamp也同时调整了Linux系统时间和硬件时间,那么这时我们如果使用php进行该字段的插入,那么我们在php中应该怎么做呢?
代码参考:php/news.php
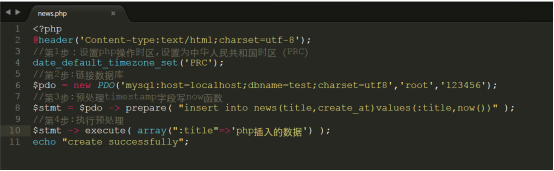
上传到/var/www/html下,测试效果如下:
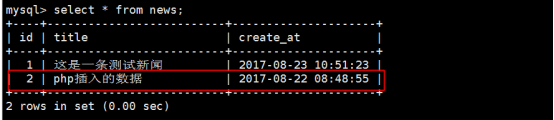
上述代码必须设置 时区,now()不要进行预处理
3.字符数据类型
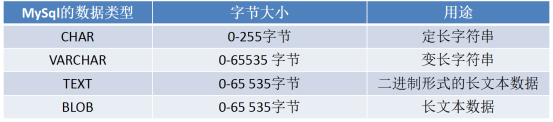
如果你做博客或者新闻发布信息的系统,标题字段选择varchar,内容选择text,这个进本上是一种常见的应用,BLOB的数据一般可能会产生一些乱码的情况所以建议不要使用在中文内容当中.
在php开发我们经常需要做时间字段的优化还有日志记录系统当中Ip字段的优化.
255.255.255.255 = 15字节(varhcar(15))
192.168.1.1 = 15字节(varchar(15)) = 15 * 1000 = 15000 字节
ip字段其实可以优化成为4个字节进行存储,那么就是4*1000=4000字节
所以如果使用varchar(15)或者char(15)来存储ip的时候,你就有优化ip字段存储的必要性了,如果希望把ip地址优化成为4个字节的大小,我们应该选择int数据类型对ip进行存储,但是如果把ip转化成为int呢,那么这时我们要学习两个函数:
4.IP数据存储
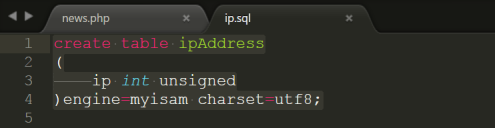
①为ip字段选择的数据类型(ip2long)
根据转换的结果可以使用以下在设计表时来选择Ip字段的数据类型选择Int
代码详细请参考:code/ip.sql
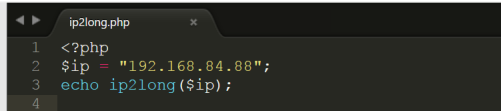
编写php代码如下:
代码详细请参考:php/ip2long.php
在默认情况下,ip2long函数会把ip转化成有签名整型,因此我们在php当中会获取到负数的情况,如下所示:
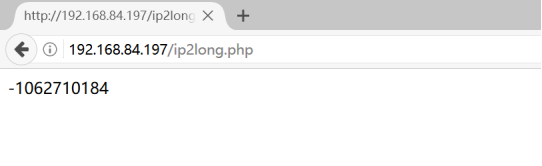
ip如果为负数的转化是属于失败的转化,那我们就需要把ip转成无签名整型获取正整数
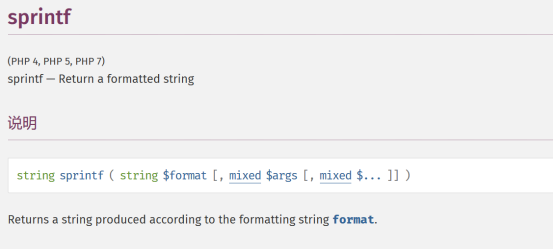
我们就需要使用sprintf函数,函数描述如下:
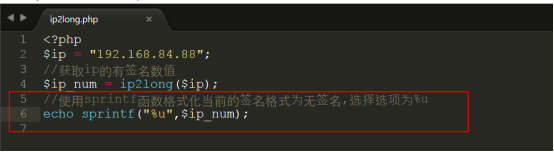
编写修改代码如下:
上传到/var/www/html下测试结果如下所示:
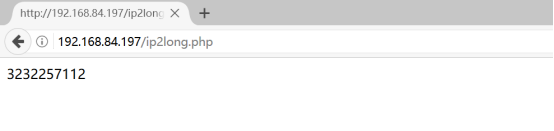
获取了ip转化无符号的结果,这时如果你希望直到当前的整数是否转化成功,那么就需要把整型转化为ip地址来进行验证,使用long2ip
②long2ip函数(把整型转换为ip地址)
php代码参看:php/long2ip.php(该代码需要上传到linux的/var/www/html下测试)
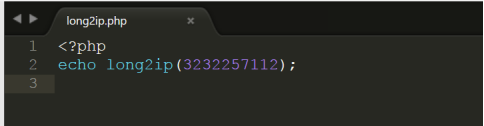
执行结果如下:
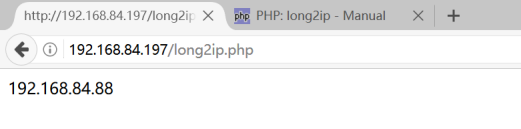
⑥ip优化的综合实例,把ip为192.168.84.88插入的数据表ipAddress当中,并且把插入的数在该表当中读取出来,代码如下所示:
php代码参看:php/caseIp.php(该代码需要上传到linux的/var/www/html下测试)
第1步:先完成pdo对ip地址转化为整型数据插入工作,代码如下:
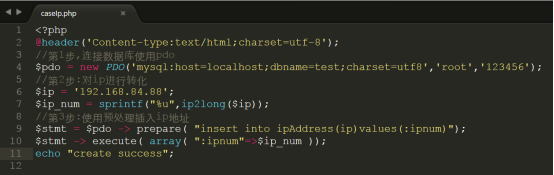
执行结果如下所示:

第2步:把ip地址从数据库读取出来并且把整型转化成为ip地址,代码如下:

执行结果如下所示:
四.物理垂直分表和数据库三范式
1.物理分表的概念
物理分表又称为手工分表,故名思议物理分表的工作是靠自己手动进行完成的,它的目的是把数据进行拆分管理.在物理分表中主要的分表思想有垂直分表和水平分表两种,这种分表是一种数据库的优化思想,所以需要引入数据库范式的概念进行支持.
2.数据库的三范式
在现实开发当中我们一般是针对需求来满足需求,于是如果有以下需求我们如果你看到眼前而不考虑长远,我们可以把需求分析和设计做出以下决定,如下图所示:

这样的表设计自然能够满足需求1,然而它有利于长远的发展吗?如果你想知道是否适合长远的发展最好就是继续提出一个新的需求看看是否容易拓展或者直接满足,继续提出需求如下:
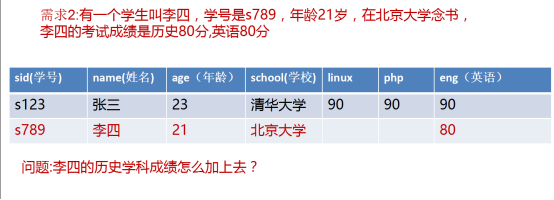
要解决需求2如果你只看到眼前,那么你可能会做出以下解决的,就是增加一个字段来添加历史学科的成绩:

这时又一个新的需求提出,这时问题就再次出现了,如下图所示:

因为不断字段去满足需求就会导致字段不断增加,造成数据的冗余,如果你希望解决以上这些问题的出现就需要使用物理垂直分表进行解决,然而垂直分表一般发生开发者开发项目和设计阶段出现较多,所以与垂直分表相关的又一个叫做数据库范式的理论进行支持,范式理论如下:
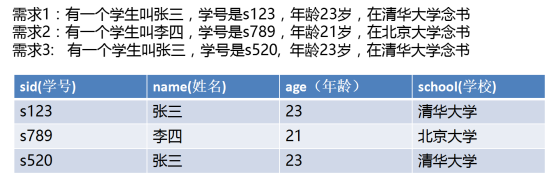
数据库第1范式:把数据合理的进行拆分让他们的共同点形成一个整体,并且形成后没有继续拆分必要 性,那么就证明该整体一个合理的整体成为符合数据库第1范式(1NF),如上述问题,解决方案符合第1范式如下:
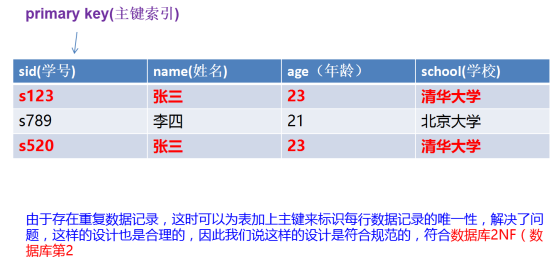
数据库第2范式:由于数据表又可能会存在相同并且重复的记录可能,我们需要解决整个问题就是加入主键,如上述问题,符合数据库第2范式如下:
数据库第3范式:由于我们把数据分别成为了一个整体,那么就需要把整体进行联合,我们把拥有主键的整体部分成为主表,把关联主表的整体部分成为附属表,那么关联他们的标识就是数据库的第3方式的核心也就是外键,所以可以认为认为数据库第3范式的核心就是关联性,如上述问题,符合第3范式设计如下:
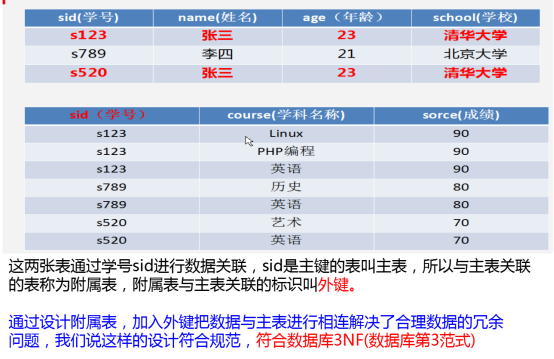
数据库三范式一般人也有把理解为物理垂直分表的标准,只要符合数据库三范式所有的规则,那么都是垂直分表的过程而整个过程一般是我们手动完成,因此物理垂直分表也称为手工垂直分表。
3.垂直分表的概念
分表时候,每一张表都是结构独立的,表与表之间通过外键的形式把数据链接在一起进行查询。只要符合数据库三范式的设计都属于垂直分表的思想.
代码详细请参考:code/students.sql
1)业务需求

2)根据三范式设计表的结构
首先满足1NF和2NF,设计表结构如下:
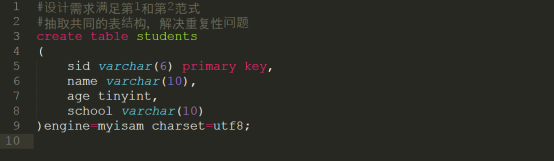
然而满足3NF,设置关联和外键,设计表结构如下:
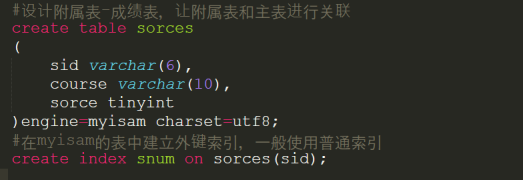
3)为表插入对应的数据
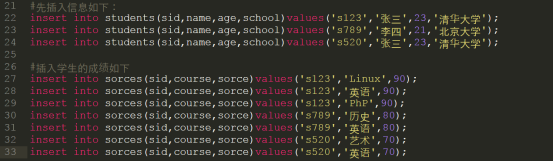
4)使用连表查询获得数据
如果希望查找学号为s123的人我们就需要把学号字段进行主表和附属表的关联,原理如下:
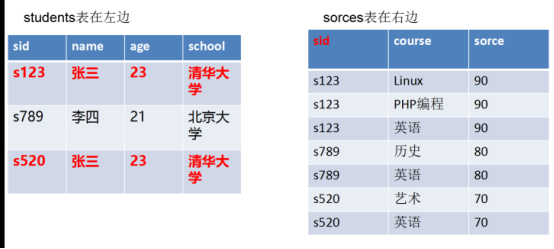
编写以下查询语句连表查询操作:

执行结果如下所示:

5)使用explain执行计划查看索引使用情况

执行结果发觉,垂直分表可以使用到索引,因为符合数据库3范式的设计就一定能够使用上索引。
4.数据库的逆范式
逆范式化指的是通过增加冗余或重复的数据来提高数据库的读性能.逆范式通俗的理解其实就是通过违反数据库三范式的定义达到某种合理的设计的一种应用.其中水平分表就是一种逆范式的应用
五.物理水平分表实验(37游戏报团实验)
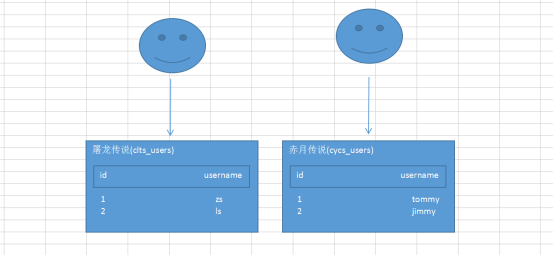
在早期的网页游戏当中有一种叫组团攻城的活动,每一个游戏的玩家可以在某一游戏中进行报名组建其他的玩家一起玩游戏,有时候可能不是只有一个游戏开展攻城的活动,而是多个游戏开展攻城的活动,这时为了更好地维护游戏,这时我们就可以使用到水平分表,其原理图如下所示:
我们可以把案例,按照如下步骤,部署到Linux当中
第1步:把代码通过ftp上传/var/www/html
第2步:建立一个名为37games的数据如下:

第3步:切换到/var/www/html下执行数据库表的安装,执行install_db.php文件
在执行脚本之前先确认数据库链接的用户名和密码以及数据库名称,打开db.php文件,内容如下,可以根据自己喜欢修改:
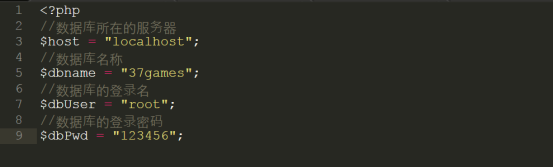
确认无误后,就在/var/www/html下使用php命令执行install_db.php文件,如下图所示:

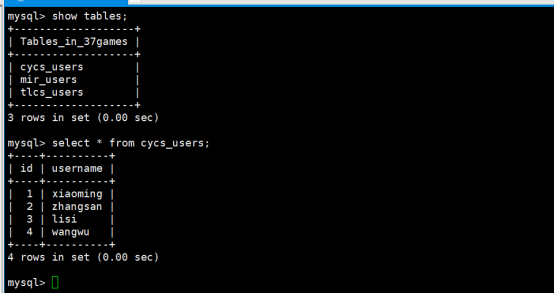
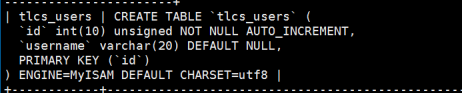
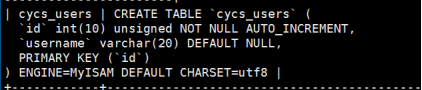
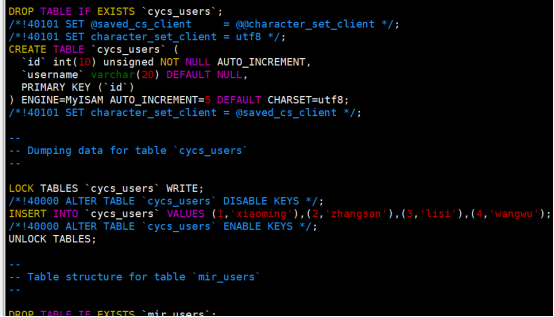
查看数据库37games当中发觉有2张表分别:tlcs_users和cycs_users

2张表的字段都是一样的,只是表名不一样
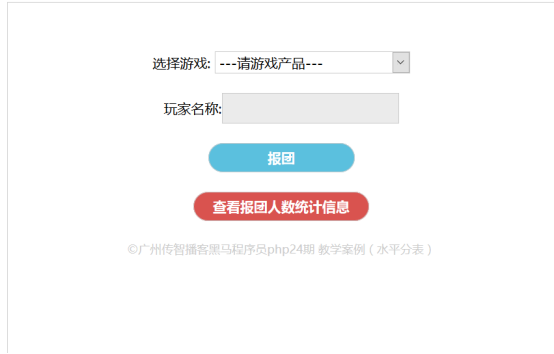
第4步:在浏览中访问linux中ip地址,出现以下界面,代表案例部署成功
第5步:分析案例的目录和文件如下:
js目录 : 放置javascript库文件的,jq.js是一个jquery框架
smarty目录:用于放置smarty类库的目录
templates:是html模板的目录
templates_c:是smarty编译模板后的目录
common.php : 一个数据库链接,smarty实例化,游戏产品列表数据引导的核心文件
count.php : 统计报团攻城的人数信息的文件
db.php : 数据库的链接配置文件
games.php:游戏产品的数组文件
index.php:网站报团首页文件
install_db.php : linux安装时执行的脚本文件
register.php: 报团插入数据库的php文件
第6步:分析首页可知,页面点机报团按钮后,会把以下表单信息传至register.php页面
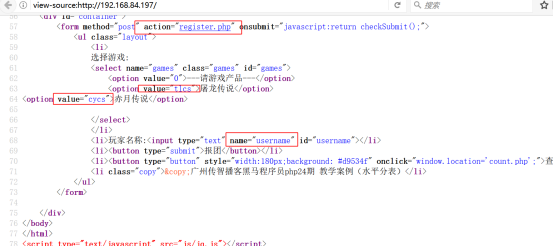
第7步:在register.php代码当中编写如下代码,获取信息并插入数据库当中
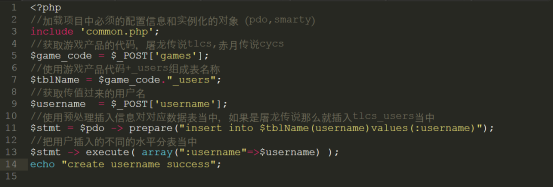
如果用户报的屠龙传说游戏,那么就会在tlcs_users当中添加数据:
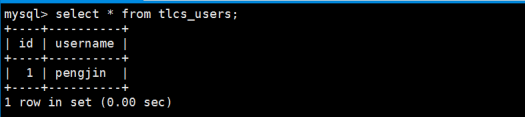
如果用户报的赤月传说游戏,那么就会在cycs_users当中添加数据:
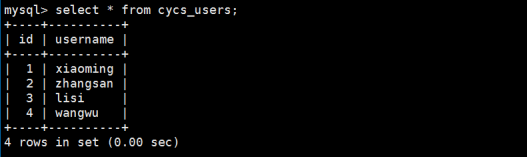
第8步:实现水平分表的统计,我们需要在count.php文件中编写代码如下:
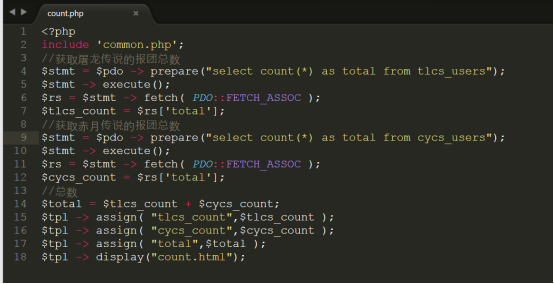
测试结果如下:

这时问题来了,如果这时老板提出一个新的需求,把一个叫做传奇霸业的游戏(mir)也进行攻城活动,那么我们就需要修改代码如下:
第9步:在games.php文件中加入对应游戏代码和游戏名称

在首页就会显示多一个游戏

同时我们还需要建立一张名为mir_users的水平分表,来存储传奇霸业的用户信息,使用命令如下:
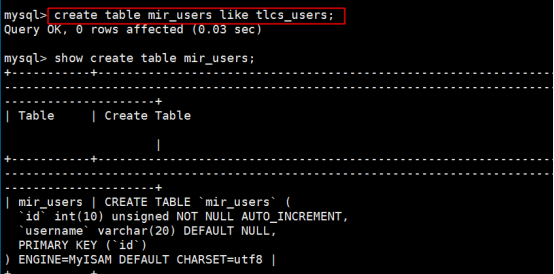
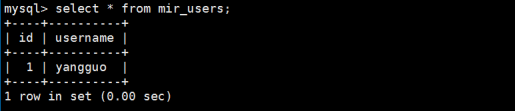
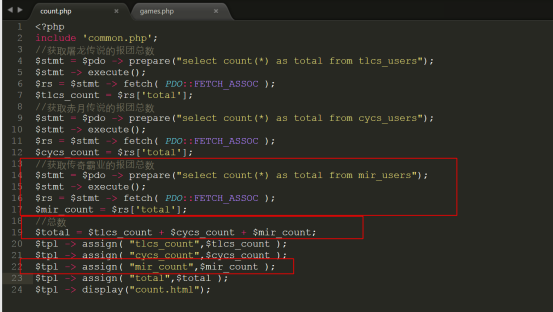
第10步:修改count.php的统计报表数据,代码如下所示:
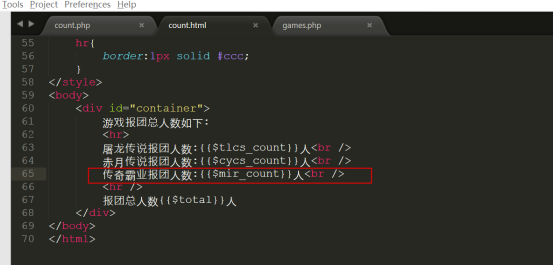
第11步:修改smarty的模板文件templates/count.html,代码如下:
测试如下:

物理水平分表自定义和拆分大数据的能力虽然非常的强,然而它有一个缺点就是由于我们造成数据的冗余分布,导致数据的统计变得麻烦,只能不同不断修改代码来满足需求,因此物理水平分表有优点也有缺点,因此水平分表的物理优化我们要付出一定的php逻辑编写的时间代价,有没有更好取代这种分表的,让我们的统计变得简单的方法呢?在mysql5.1之后,其官方开发者提供了一种叫逻辑水平分表的手段
六. MySql的逻辑水平分表
物理水平分表的好处在于自定义能力很强,但物理分表不利于数据的统计,因此MySql为了解决物理水平分表的缺陷提出了逻辑水平分表的概念,逻辑水平分表是MySql自带功能,它的好处就是分表的过程是系统自动完成的,而我们写的代码不会像物理水平分表那样疲于应对需求,逻辑水平分表主要有两种。一种称为Range分表,一种称为List分表。
业界有些说法也叫Range分区和List分区。
1.使用Range形式的逻辑分表(切蛋糕)
RANGE分表其实好比生活中的切蛋糕中的概念,是基于范围的数据切分,RANGE主要是基于整数的分表。一般按主键进行范围分表,假设当前主键的最大值为5000,有时希望用一个范围对数据进行拆分,比如把数据拆分为5个等份:
1-1000:是5000的第1个范围,把该范围的数据作为一张表
1001-2000:是5000的第2个范围,把该范围的数据作为一张表
2001-3000:是5000的第3个范围,把该范围的数据作为一张表
3001-4000:是5000的第3个范围,把该范围的数据作为一张表
4001-5000:是5000的第4个范围,把该范围的数据作为一张表
如果有以上的需求,那么就可以使用MySql的range分表技术,其原理图如下:
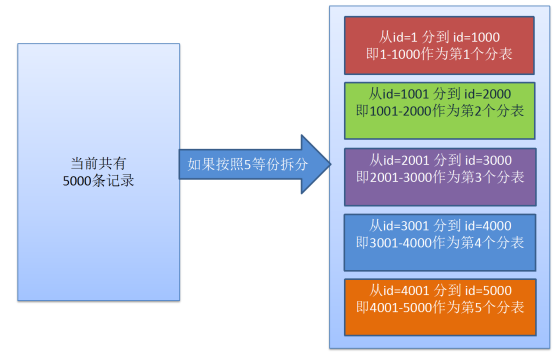
如果把5000条记录看成蛋糕,那么拆分的数据就是把蛋糕切成了5等份
①创建表的时候指定range分表的范围
代码详细请参考:code/range.sql
语法规则:
partition by range (字段)(
partition 分表名称 values less than (范围)
)
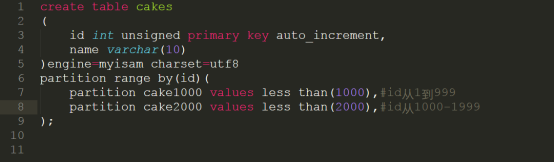
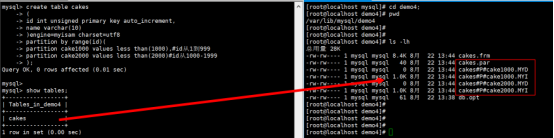
发觉系统自动帮我们产生2个分表的区域
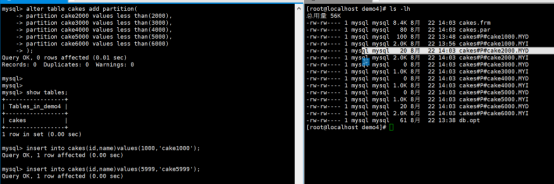
假设我希望有一张一些数据处于cake1000这张分表当中,那么我应该如何插入?
分析可知:由于这个分表是从id的范围来分,如果id的范围是1-999那么就会处于cake1000当中,所以我们插入数据如下:
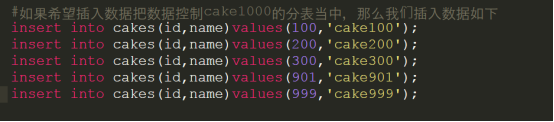
执行结果如下:
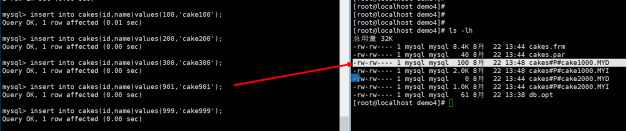
发觉你插入数据其实可以有效控制范围


假设我们插入的数据的id=2001,那么会出现怎么样的情况呢?

然而我们的数据是分布在不同的分表当中,如果我们使用select count(*) from cakes能整成统计出记录总数吗?
这个答案是肯定的,因为逻辑分表的功能和算法是开发者帮您实现的

假设我们删除了cake2000这个分表,那么统计会改变吗?也就是说数据会丢失吗?
②删除range分表
代码详细请参考:code/del_range.sql
语法规则:alter table 表名 drop partition 分表名称;
如果我们删除cake2000这个分表,那么我们查询id=1000是可以查出来的
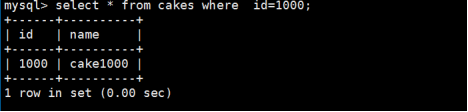
如果执行分表删除,如下;

执行结果如下:
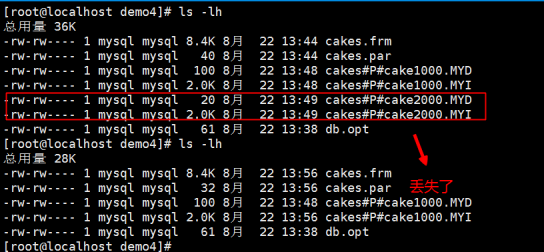
如果使用select count(*)进行统计查询会发觉数据丢失了
注意:分表删除数据会丢失
③添加range分表
代码详细请参考:code/add_range.sql
如果我们添加一个数据超过了分表范围,那么就会报错

语法规则:
alter table 表名 add partition (
partition 分表名称 values less than (范围)
)
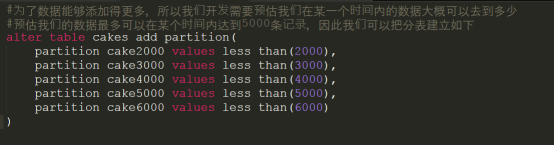
执行的结果如下所示:
2.使用List形式的逻辑分表(分季度)
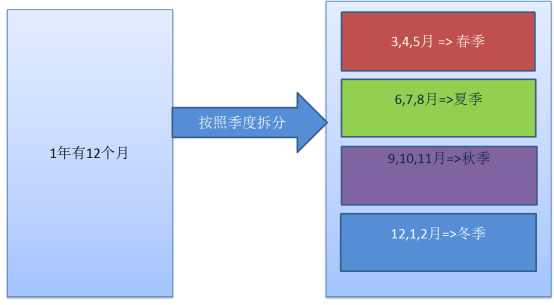
List分表其实简单地理解为把一年按季度的进行分表的应用即可,因为实际开发当中List分表主要用于年度季度报表的应用比较多,List分表也是按范围的分表技术。假设当前要把1年的数据进行季度拆分,那么1年可以分为4个季度:
3,4,5月分为春季
6,7,8月分为夏季
9,10,11月分为秋季
12,1,2月份分为冬季
这时range分表其实无法达到这个功能,如果需要满足当前这个需求则可以选择List分表技术,其原理图如下:
list分表一般用于财务报表的统计系统当中
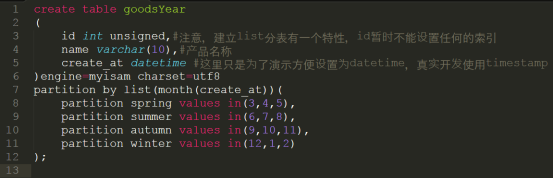
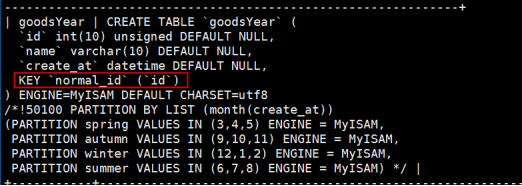
①创建表的时候指定list分表的范围
代码详细请参考:code/list.sql
语法规则:
partition by list (条件语句)(
partition 分表名称 values in (范围)
)
执行结果如下:
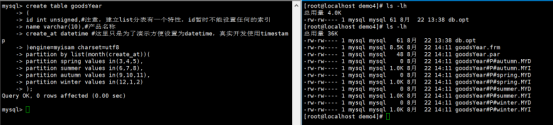
②尝试插入数据到夏季的分表当中

执行结果如下:

④删除list分表
代码详细请参考:code/del_list.sql
语法规则:alter table 表名 drop partition 分表名称;

执行结果会发觉,数据跟range一样会丢失:
注意:分表删除数据会丢失,list分表最好不要删除分表,因为list的分表应用多数用于财务系统,财务系统的数据一般不建议删除,所以最好不要删除list分表种的分表
⑤添加list分表
代码详细请参考:code/add_list.sql
语法规则:
alter table 表名 add partition (
partition 分表名称 values in (范围)
)

执行结果如下:

list分表有1个特点,就是在mysql5.1.73版本,建议id字段设置为普通索引,因为唯一性索引和主键在list分表当中不起作用,且无法添加



这时我们如果建立的是普通索引,那么就不会出错了

执行结果如下:
七.数据库的备份和导入
①备份命令mysqldump
命令格式: mysqldump -uroot -p123456 [数据库名称] > 保存文件的路径和名称

在/root/桌面就会存在37wan.sql这个文件,内容如下:
这时假设我们删除了37games这个数据库,那么就可以利用备份的文件进行导入恢复


使用导入37wan.sql的方法进行数据库恢复,步骤如下:
①建立37games的数据库

退出mysql
②执行导入