Python 闭包、迭代器、生成器、装饰器
一、闭包
闭包:闭包就是内层函数对外层函数局部变量的引用。
def func():
a = "哈哈"
def func2():
print(a) # 引用了外层函数的局部变量a,闭包
func2()
func()
我们可以使用__closure__来查看是否是闭包。
def func():
a = "哈哈"
def func2():
print(a) # 引用了外层函数的局部变量a,闭包
func2()
print(func2.__closure__) # (<cell at 0x000001E506B074C8: str object at 0x000001E506ADCEA0>,)
func()
# 如果返回None就不是闭包,返回cell就是闭包。
如何在函数外边调用内部函数呢?
def func():
a = "哈哈"
def func2():
print(a)
func2
func()()
# 调用func()获得返回结果是func2这个变量,这个时候只需要再一次加()调用就可以调用内部函数func2了
闭包的好处有哪些呢?
由于我们在外界可以访问内部函数, 那这个时候内部函数访问的时间和时机就不⼀定了, 因为在外部, 我们可以选择在任意的时间去访问内部函数。 因为如果⼀个函数执⾏毕。则这个函数中的变量以及局部命名空间中的内容都将会被销毁。 在闭包中, 如果变量被销毁了, 那内部函数将不能正常执⾏。 所以, Python规定, 如果你在内部函数中访问了外层函数中的变量, 那么这个变量将不会消亡。将会常驻在内存中。 也就是说, 使⽤闭包, 可以保证外层函数中的变量在内存中常驻。
这样做有什么好处呢? 非常⼤的好处。 我们来看⼀个关于爬⾍的代码:
from urllib.request import urlopen
def but():
content = urlopen("http://www.xiaohua100.cn/index.html").read()
def get_content():
return content
return get_content
fn = but() # 这个时候就开始加载校花100的内容
# 后⾯需要⽤到这⾥⾯的内容就不需要在执⾏⾮常耗时的⽹络连接操作了
content = fn() # 获取内容
print(content)
content2 = fn() # 重新获取内容
print(content2)
闭包的好处:
- 数据常驻内存,方便反复读取
- 数据安全,函数外部无法修改闭包引用的变量
二、迭代器
1、可迭代对象
可迭代对象:遵循了可迭代协议的对象。比如:list,tuple,str,dict,set 都属于可迭代对象。
for i in 123:
print(i)
# TypeError: 'int' object is not iterable
# int不是可迭代对象
2、判断是否是可迭代对象
如何判断一个对象是否是可迭代对象呢?这时候我们要用到dir()这个内置函,它可以查看该数据类中定义的所有方法。
print(dir(str))
print(dir("哈哈哈"))
'''
['__add__', '__class__', '__contains__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getnewargs__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mod__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__rmod__', '__rmul__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'capitalize', 'casefold', 'center', 'count', 'encode', 'endswith', 'expandtabs', 'find', 'format', 'format_map', 'index', 'isalnum', 'isalpha', 'isdecimal', 'isdigit', 'isidentifier', 'islower', 'isnumeric', 'isprintable', 'isspace', 'istitle', 'isupper', 'join', 'ljust', 'lower', 'lstrip', 'maketrans', 'partition', 'replace', 'rfind', 'rindex', 'rjust', 'rpartition', 'rsplit', 'rstrip', 'split', 'splitlines', 'startswith', 'strip', 'swapcase', 'title', 'translate', 'upper', 'zfill']
'''
# 以上是字符串内部含有的所有方法,我们只需在其中找到__iter__()就能确定它是一个可迭代对象了。
以上是不是一大串看起来眼花缭乱?没关系,我们可以用简便操作来判断
print("__iter__" in dir(str)) # True
# 如果返回True则代表是可迭代对象,如果返回False则表示不是可迭代对象
我们还可以用isinstance()来查看是否是可迭代对象和是否是迭代器
from collections import Iterable # 可迭代对象
from collections import Iterator # 迭代器
l = [1,2,3]
l_iter = l.__iter__()
print(isinstance(l,Iterable)) #True
print(isinstance(l,Iterator)) #False
print(isinstance(l_iter,Iterator)) #True
print(isinstance(l_iter,Iterable)) #True
综上, 我们可以确定。 如果对象中有__iter__函数, 那么我们认为这个对象遵守了可迭代协议。就可以获取到相应的迭代器, 这⾥的__iter__是帮助我们获取到对象的迭代器。 我们使⽤迭代器中的___next__来获取到⼀个迭代器中的元素。
3、迭代器
迭代器中一定含有__iter__()方法和__next__()
lst = [1, 2, 3, 4]
print("__iter__" in dir(lst)) # True
print("__next__" in dir(lst)) # False
# lst只是可迭代对象,并不是迭代器
lst_iter = lst.__iter__()
print("__iter__" in dir(lst_iter)) # True
print("__next__" in dir(lst_iter)) # True
# lst_iter 是迭代器
总结:迭代器一定是可迭代对象,可迭代对象不一定是迭代器。
4、迭代器的取值
迭代器取值可以通过_next_()方法。
lst = [1, 2, 3, 4]
lst_iter = lst.__iter__()
lst_iter.__next__() # 1
lst_iter.__next__() # 2
lst_iter.__next__() # 3
lst_iter.__next__() # 4
# 每次__next__()取一次值,若是取完值继续__next__()呢?
lst_iter.__next__() # StopIteration
# 报错:StopIteration
5、模拟for循环
我们知道for循环可以对可迭对象进行取值,那么for循环内部的实现机制是怎样的呢?
# 先来原汁原味的for循环
lst = [1, 2, 3, 4]
for i in lst:
print(i)
# 1
# 2
# 3
# 4
# 再来我们自己手动写的“for循环”
lst = [1, 2, 3, 4]
lst_iter = lst.__iter__()
while 1:
try:
i = lst_iter.__next__()
print(i)
except StopIteration:
break
# 1
# 2
# 3
# 4
由以上结论可以得出for循环实际上是对迭代器进行了循环_next_()操作,最后通过捕捉StopIteration异常终止取值。
总结:1、 Iterable: 可迭代对象. 内部包含_iter_()函数
2、 Iterator: 迭代器. 内部包含_iter_() 同时包含_next_().
三、生成器
1、什么是生成器
生成器本质上就是迭代器
2、如何获取生成器
# 首先我们先看一个简单函数
def func():
print("约吗?")
return "叔叔我不约
ret = func()
print(ret)
# 约吗?
# 叔叔我不约
# 将函数中的return换成yield就是生成器
def func():
print("约吗?")
yield "叔叔我不约"
ret = func()
print(ret)
# <generator object func at 0x0000022CBD94CEB8>
运⾏的结果和上⾯不⼀样,为什么呢? 由于函数中存在了yield, 那么这个函数就是⼀个⽣成器函数。 这个时候, 我们再执⾏这个函数的时候, 就不再是函数的执⾏了。 ⽽是获取这个⽣成器。那么如何使⽤呢? 想想迭代器, ⽣成器的本质是迭代器。 所以, 我们可以直接执⾏_next_()来执⾏以下⽣成器。
def func():
print("约吗?")
yield "叔叔我不约"
ret = func()
print(ret.__next__())
# 约吗?
# 叔叔我不约
既然return和yield最后返回的结果都是一样,那它们之间有什么区别呢?我们再看下面代码
def func():
print("哈哈哈谁都不能阻止我打印...")
return "SB"
print("我还想接着打印,给个机会...")
ret = func()
print(ret)
# 哈哈哈谁都不能阻止我打印...
# SB
def func():
print("哈哈哈谁都不能阻止我打印...")
yield "SB"
print("你越这么说我越要打印哈哈哈...")
yield "S2B"
print("我就是要打印,你喊return来都没用哈哈哈")
# return "SB"
# print("爸爸给个机会!!!")
ret = func()
print(ret.__next__())
# 哈哈哈谁都不能阻止我打印...
# SB
print(ret.__next__())
# S2B
# 我就是要打印,你喊return来都没用哈哈哈
yield 和 return的区别:yield是分段来执行⼀个函数。 return直接停⽌执⾏函数。
当程序运⾏完最后⼀个yield, 那么后⾯继续进⾏__next__()程序会报错。
3、生成器的作用
由于生成器具有惰性机制,每次想要得到值都必须_next_()去取一次,所有生成器具有节省内存的优点。
打个比方:你需要很多个鸡蛋,但是如果把鸡蛋一下子全给你会很占家里的位置。这个时候,如果给你一只老母鸡,想要鸡蛋的时候就让它下,就能达到既需要很多鸡蛋也同时不占家里位置的情况。而生成器就充当着这里面的老母鸡的角色。
# 鸡蛋
def get_eggs():
eggs = []
for i in range(10000):
eggs.append(i)
return eggs
ret = get_eggs() # 10000个鸡蛋
# 老母鸡
def get_eggs():
for i in range(10000):
yield i
ret = get_eggs() # 老母鸡
print(ret.__next__()) # 老母鸡下1个蛋
print(ret.__next__()) # 老母鸡下2个蛋
4、特点总结:
-
节省内存
-
具有惰性机制
-
只能向下执行(只能__next__向下取值)
-
生成器中的send()
send和_next_()⼀样都可以让⽣成器执⾏到下⼀个yield。
def func(): print("我第一欧耶") a = yield "呵呵" print("我第二,by the way,楼上sb") print(a) b = yield "嘿嘿" print("我赵日天不服") print(b) yield "哈哈" ret = func() # 获取生成器 print(ret.__next__()) # 我第一欧耶 # 呵呵 print(ret.send("我是a")) # 我第二,by the way,楼上sb # 我是a # 嘿嘿 print(ret.send("我是b")) # 我赵日天不服 # 我是b # 哈哈分析函数执行步骤:
-
定义函数func()
-
调用函数获取生成器ret
-
对生成器执行print(_next_())
- 打印 “我第一欧耶”
- 打印yield返回值 “呵呵”
-
对生成器执行print(ret.send("我是a"))
- 将 “我是a” 赋值给 a 变量
- 打印 我第二,by the way,楼上sb
- 打印 ”我是a“
- 打印yield返回值 “嘿嘿”
-
对生成器执行print(ret.send("我是b"))
-
将 “我是a” 赋值给 b 变量打印
-
打印 我赵日天不服
-
打印 我是b
-
打印yield返回值 “哈哈”
-
send() 和 _next_()区别:
- send() 和 _next_() 都是让生成器向下走一次
- send()可以给上⼀个yield的位置传递值, 不能给最后⼀个yield发送值。 在第⼀次执⾏⽣成器代码的时候不能使⽤send(),因为没有yield可以接收。
-
四、装饰器
装饰器就是闭包函数的一种应用场景
1、为何要有装饰器
#开放封闭原则:对修改封闭,对扩展开放
2、什么是装饰器
装饰器他人的器具,本身可以是任意可调用对象,被装饰者也可以是任意可调用对象。
强调装饰器的原则:1 不修改被装饰对象的源代码 2 不修改被装饰对象的调用方式
装饰器的目标:在遵循1和2的前提下,为被装饰对象添加上新功能
3、装饰器的使用
-
无参装饰器
import time def timmer(func): def wrapper(*args,**kwargs): start_time=time.time() res=func(*args,**kwargs) stop_time=time.time() print('run time is %s' %(stop_time-start_time)) return res return wrapper @timmer def foo(): time.sleep(3) print('from foo') foo() -
有参装饰器
def auth(driver='file'): def auth2(func): def wrapper(*args,**kwargs): name=input("user: ") pwd=input("pwd: ") if driver == 'file': if name == 'egon' and pwd == '123': print('login successful') res=func(*args,**kwargs) return res elif driver == 'ldap': print('ldap') return wrapper return auth2 @auth(driver='file') def foo(name): print(name) foo('egon')
4、装饰器语法
被装饰函数的正上方,单独一行
@deco1
@deco2
@deco3
def foo():
pass
foo=deco1(deco2(deco3(foo)))
5、装饰器补充
from functools import wraps
def deco(func):
@wraps(func) #加在最内层函数正上方
def wrapper(*args,**kwargs):
return func(*args,**kwargs)
return wrapper
@deco
def index():
'''哈哈哈哈'''
print('from index')
print(index.__doc__)
6、叠加多个装饰器
# 叠加多个装饰器
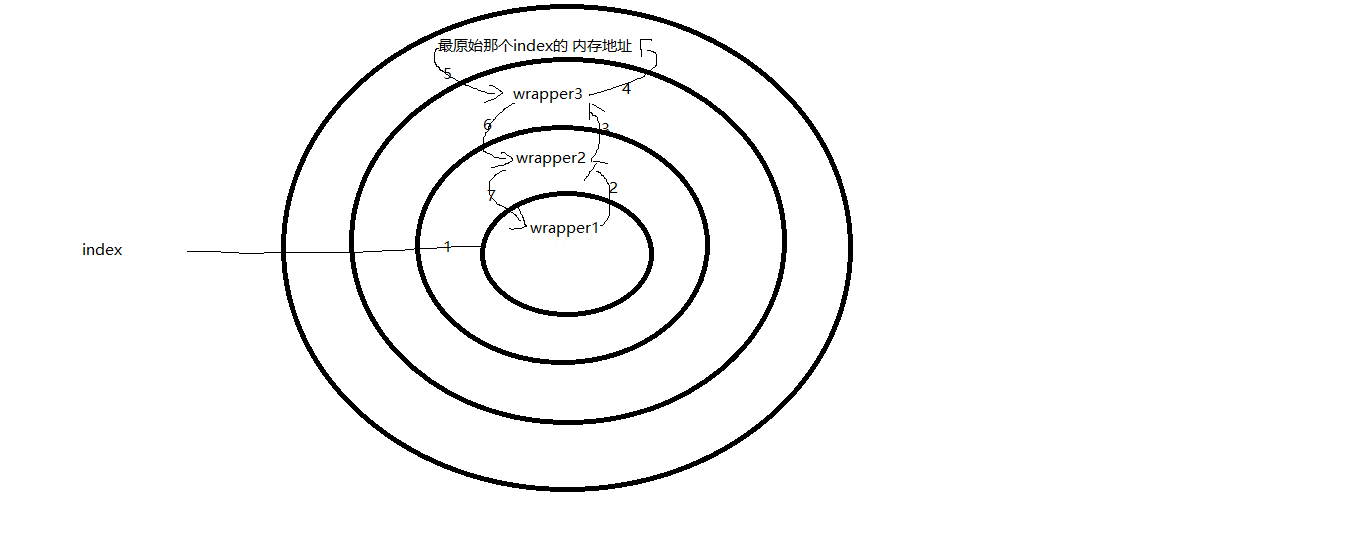
# 1. 加载顺序(outter函数的调用顺序):自下而上
# 2. 执行顺序(wrapper函数的执行顺序):自上而下
# 示例代码
def outter1(func1): #func1=wrapper2的内存地址
print('加载了outter1')
def wrapper1(*args,**kwargs):
print('执行了wrapper1')
res1=func1(*args,**kwargs)
return res1
return wrapper1
def outter2(func2): #func2=wrapper3的内存地址
print('加载了outter2')
def wrapper2(*args,**kwargs):
print('执行了wrapper2')
res2=func2(*args,**kwargs)
return res2
return wrapper2
def outter3(func3): # func3=最原始的那个index的内存地址
print('加载了outter3')
def wrapper3(*args,**kwargs):
print('执行了wrapper3')
res3=func3(*args,**kwargs)
return res3
return wrapper3
@outter1 # outter1(wrapper2的内存地址)======>index=wrapper1的内存地址
@outter2 # outter2(wrapper3的内存地址)======>wrapper2的内存地址
@outter3 # outter3(最原始的那个index的内存地址)===>wrapper3的内存地址
def index():
print('from index')
print('======================================================')
index()
示范代码
五、推导式
推导式:
- 列表推导式
- 字典推导式
- 集合推导式
1、列表推导式
语法:[ 结果 for 变量 in 可迭代对象 ]
# 假如我们要实现向一个列表中循环添加数据
lst = []
for i in range(100):
lst.append(i)
print(lst)
# 而我们使用列表推导式可以这样写
print([i for i in range(100)])
# 一行代码搞定,结果都是一样的
还可以进行筛选,筛选语法:[ 结果 for 变量 in 可迭代对象 if 条件 ]
# 比如将100之内的偶数放进一个空列表中
print([i for i in range(101) if i % 2 ==0])
2、生成器表达式
生成器表达式和列表推导式是一样的,只不过把[ ]换成了()
ret = (i for i in range(10))
print(ret)
# 获取到的ret是一个生成器对象
# 我们可以通过for循环遍历它
for i in ret:
print(i)
生成器也可以进行筛选
# 100以内的奇数
ret = (i for i in range(100) if i % 2 == 1)
print(list(ret))
# 一行代码实现寻找名字中带有两个e的⼈的名字
names = [['Tom', 'Billy', 'Jefferson', 'Andrew', 'Wesley', 'Steven','Joe'], ['Alice', 'Jill', 'Ana', 'Wendy', 'Jennifer', 'Sherry', 'Eva']]
print(list((name for name_list in names for name in name_list if name.count("e") == 2)))
# ['Jefferson', 'Wesley', 'Steven', 'Jennifer']
生成器表达式和列表推导式的区别:
- 列表推导式比较耗内存,一次性全部加载。而生成器表达式几乎不占用内存,使用的时候才分配内存。
- 得到的值不一样,生成器表达式得到的是一个生成器,而列表推导式得到的是一个列表。
- ⽣成器的惰性机制:⽣成器只有在访问的时候才取值。 说⽩了, 你找他要他才给你值。 不找他要, 他是不会执⾏的。
3、字典推导式
# 将字典中的key和value互换
dic = {"name": "dogfa", "age":18, "gender":"不男不女"}
new_dic = {dic[key]: key for key in dic}
print(new_dic)
# {'dogfa': 'name', 18: 'age', '不男不女': 'gender'}
4、集合推导式
集合推导式可以帮我们直接⽣成⼀个集合。 集合的特点: ⽆序, 不重复, 所以集合推导式⾃带去重功能。
ret = {i for i in [1,11,111,1,11,11111,111,1,111,111,1111]}
print(ret)
# {1, 11111, 11, 111, 1111}