1.如何判断垃圾对象
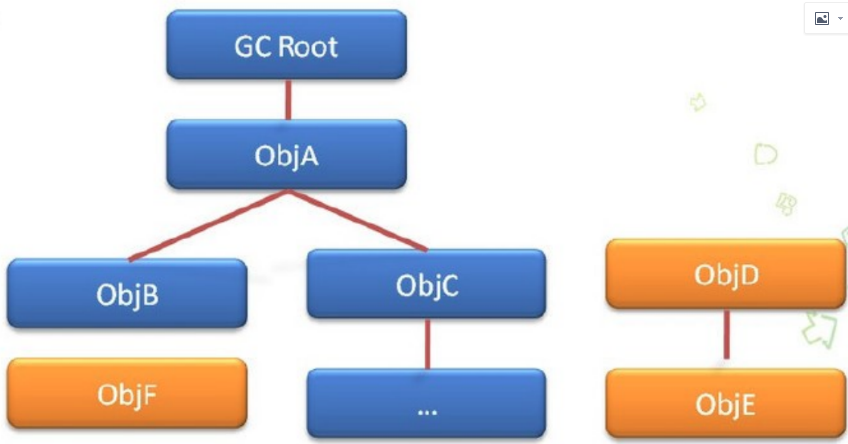
可达性分析算法
也叫根搜索算法,Java语言采用这种分析算法去判断垃圾对象。
可作GCRoot的对象
虚拟机栈(栈帧中的本地变量表)中的引用的对象。
方法区中的类静态属性引用的对象。
方法区中的常量引用的对象。
本地方法栈中JNl(即一般说的Native方法)的引用的对象。
2.常见的垃圾回收算法
2.1复制回收算法(Mark-Sweep)
来回收新生代
Hotspot的新生代:
Eden
Survivor(from)
Survivor(to)
正常对象内存分配的时候,只会使用Eden区和Survivor其中的一块区域。
使用复制算法的垃圾回收步骤:
1. 当Eden区发生垃圾回收之后,会将Eden区和Survivor其中的一块区域中的对象,复制到另一块Survivor区域
2. 然后将将Eden区和Survivor其中的一块区域中的对象完全清理掉。
缺点:内存分配时会浪费新生代的10%的空间
2.2.标记清除算法(Mark-Sweep)
最基本的算法,主要分为标记和清除2个阶段。首先标记出所有需要回收的对象,在标记完成后统一回收掉所有被标记的对象
缺点:1. 效率不高。2. 产生空间碎片。会产生大量不连续的内存碎片,会导致大对象可能无法分配,提前触发GC 。
2.3标记整理算法(Mark-Compact)
标记过程仍然与“标记-清除”算法一样,然后让所有存活的对象都向一端移动,然后直接清理掉端边界以外的内存。
新生代,每次垃圾回收都有大量对象失去,选择复制算法。
老年代,对象存活率高,无人进行分配担保,就必须采用标记清除或者标记整理算法。
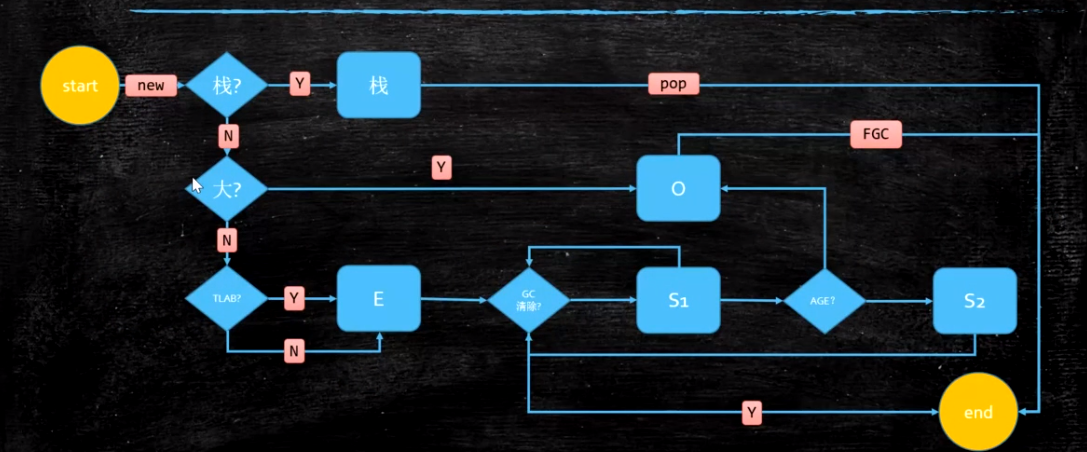
3.对象的分配
一个对象产生之后 首先判断能不能在栈上分配(逃逸分析或者是大的对象),如果栈上不能分配 进行线程本地分配(占用eden 默认1%,这块空间是线程私有的,避免多线程争抢。)
如果分配不了,在Eden分配,经过15次GC还存活(cms 6次)进入Old区,若在GC的时候,会将存活的对象copy到S0区,若超过S区的一半的内存时 把GC年纪最大的直接放到Old区。
4.垃圾回收器
常用的垃圾回收器: Serial、ParNew、Parallel Scavenge、Serial Old、Parallel Old、CMS、G1、ZGC
常用组合:
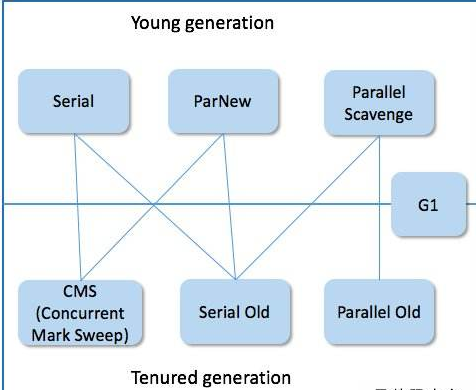
1.Serial和Serial Old
Serial 使用单线程进行垃圾回收,并且会停止所有工作线程(STW),停顿时间长,故现在用的很少(用于回收新生代) 。Serial Old 用于老年代,使用标记清理算法,也是单线程。
2.Parallel Scavenge和 Parallel Old
若JVM没有做任何调优,就是默认的这一组。PS 使用多线程清理垃圾,用于新生代。 PO使用整理算法。
3.ParNew和CMS
ParNew 跟PS没有区别
CMS:
1.基于"标记-清除"算法(不进行压缩操作,产生内存碎片);
2.以获取最短回收停顿时间为目标;
3.并发收集、低停顿;
是HotSpot在JDK1.5推出的第一款真正意义上的并发(Concurrent)收集器;第一次实现了让垃圾收集线程与用户线程(基本上)同时工作;
CMS产生的阶段:
1.初始标记STW开始标记。
2.并发标记和应用程序同时运行。
3.重新标记STW,在并发标记中产生的新垃圾在重新标记.
4.并发清理。
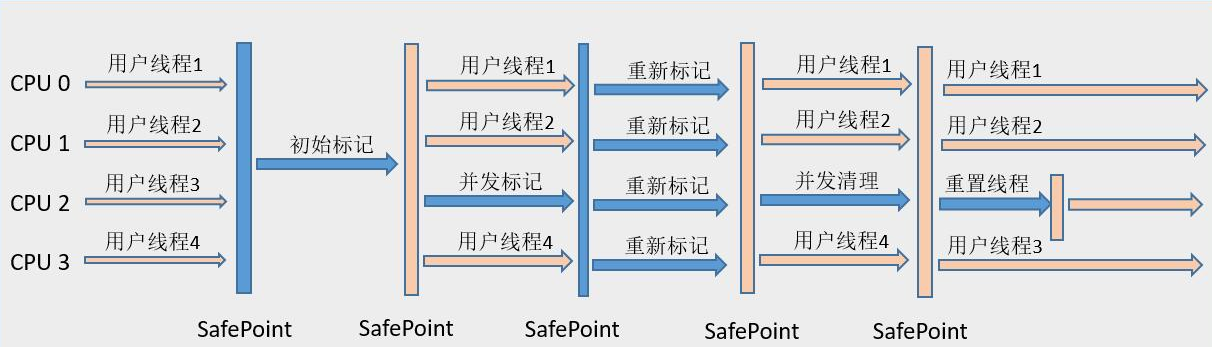
CMS缺点:1.产生内存碎片. 2.产生浮动垃圾。在并发清理中还会产生垃圾。
4.G1
G1是一种服务端应用使用的垃圾回收器,目标是用在多核,大内存的机器上,它在大多数情况上可以实现指定的GC暂停世界,同时还能保持较高的吞吐量.
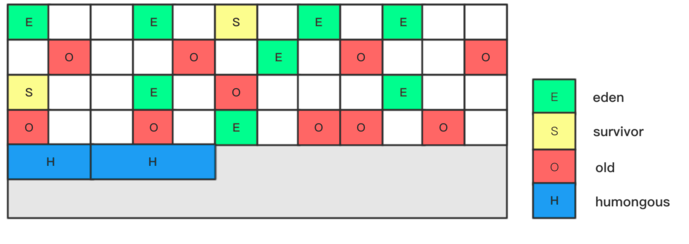
G1将内存划分成了多个大小相等的Region(默认是512K),Region逻辑上连续,物理内存地址不连续。同时每个Region被标记成E、S、O、H,分别表示Eden、Survivor、Old、Humongous。其中E、S属于年轻代,O与H属于老年代。
H表示Humongous。从字面上就可以理解表示大的对象(下面简称H对象)。
当分配的对象大于等于Region大小的一半的时候就会被认为是巨型对象。H对象默认分配在老年代,可以防止GC的时候大对象的内存拷贝。通过如果发现堆内存容不下H对象的时候,会触发一次GC操作。
在进行Young GC的时候,Young区的对象可能还存在Old区的引用, 这就是跨代引用的问题。
为了解决Young GC的时候扫描整个老年代,G1引入了Card Table 和Remember Set的概念,基本思想就是用空间换时间。这两个数据结构是专门用来处理Old区到Young区的引用。Young区到Old区的引用则不需要单独处理,因为Young区中的对象本身变化比较大,没必要浪费空间去记录下来。
RSet:全称Remembered Sets, 用来记录外部指向本Region的所有引用,每个Region维护一个RSet。RSet的价值在于使得垃圾回收器不需要扫描整个堆 找到谁引用了当前分区中的对象,只需要扫描RSet即可.
Card Table:如果Old区中的对象指向了Young区,就将它设为Dirty(脏的),下次扫描时,只需要扫描Dirty Card,在结果上Card Table使用了Bitmap.
4.1 G1 GC主要可以分为两个阶段
4.1.1 全局并发标记(global concurrent marking)
全局并发标记又可以进一步细分成下面几个步骤:
- 初始标记(initial mark,STW)。它标记了从GC Root开始直接可达的对象。初始标记阶段借用young GC的暂停,因而没有额外的、单独的暂停阶段。
- 并发标记(Concurrent Marking)。这个阶段从GC Root开始对heap中的对象标记,标记线程与应用程序线程并行执行,并且收集各个Region的存活对象信息。过程中还会扫描上文中提到的SATB write barrier所记录下的引用。
- 最终标记(Remark,STW)。标记那些在并发标记阶段发生变化的对象,将被回收。
- 清除垃圾(Cleanup,部分STW)。这个阶段如果发现完全没有活对象的region就会将其整体回收到可分配region列表中。 清除空Region。
4.1.2 拷贝存活对象(Evacuation)
Evacuation阶段是全暂停的。它负责把一部分region里的活对象拷贝到空region里去(并行拷贝),然后回收原本的region的空间。
Evacuation阶段可以自由选择任意多个region来独立收集构成收集集合(collection set,简称CSet),CSet集合中Region的选定依赖于上文中提到的停顿预测模型,该阶段并不evacuate所有有活对象的region,
只选择收益高的少量region来evacuate,这种暂停的开销就可以(在一定范围内)可控。
4.2 G1在并发标记中的算法
并发标记算法:三色标记
把对象分为三种颜色:黑色(自身和成员表里都已经标记),灰色(自身被标记,成员表里未被标记),白色(未被标记的对象).
如下图,比如一个对象A,它所引用的对象B和C都已经标记完成,自己就变成黑色.B对象还有一个引用指向白色对象没有被标记这个时候B是灰色.
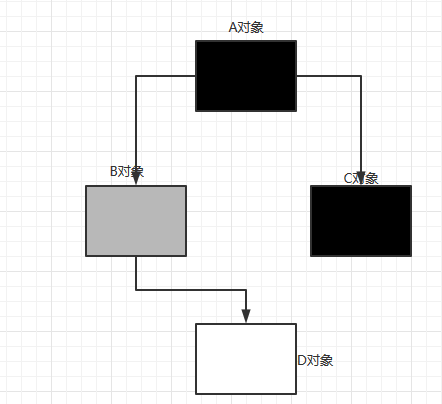
漏标:当黑色对象A指向白色对象D,灰色对象B指向白色没了.如下图,这样会产生漏标,遍历不到。必须具备两个两个条件:黑色指向白色对象,灰色指向白色对象的引用消失.

CMS和G1的核心就在于并发标记的线程和工作线程同时进行,只有这个阶段会产生漏标.
两种解决方案:
1.增量更新,关注引用的增加,把黑色A对象变成灰色,下次需要重新扫描属性.(CMS使用).
2.STAB 关注引用的删除。当B指向D的引用消失时,把这个引用推到GC的堆栈,保证D还能被扫描到,下次扫描直接能扫白色,不会产生漏标(G1使用).
当灰色到白色引用消失时,由于有RSet存在,不需要扫描整个堆去查找指向白色的引用,效率比较高.