基于物品的系统过滤
一、基础算法
算法原理:给用户推荐那些和他们之前喜欢的物品相似的物品。物品A和物品B具有很大的相似度是因为喜欢A的用户大都也喜欢物品B.
基于物品的协同算法主要分为两步:
1.计算物品之间的相似度:
使用下面的公式定义物品之间的相似度:
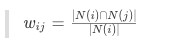
其中,|N(i)|是喜欢物品i的用户数,|N(j)|是喜欢物品j的用户数,$|N(i) cap N(j)|$是同时喜欢物品i和物品j的用户数。上述公式可以理解为喜欢物品i的用户中有多少比例的用户也喜欢j.
但是上述公式存在一个问题,如果j很热门,很多人都喜欢,那么$W_{ij}$就会很大,接近1。这样会造成任何物品都会和热门物品有很大的相似度,为了避免推荐出热门的物品,可以用下面的公式:
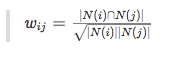
这个公式惩罚了物品j的权重,减轻了热门产品和很多物品相似的可能性。
从上面的定义看出,在协同过滤中两个物品产生相似度是因为它们共同被很多用户喜欢,两个物品共同被很多人喜欢,相似度越高,这里面蕴含着一个假设,就是假设每个用户的兴趣都局限在某几个方面,因此如果两个物品属于一个用户的兴趣列表,那么这两个物品可能就属于有限的几个领域,而如果两个物品属于很多用户的兴趣列表,那么它们就可能属于同一个领域,因而有很大的相似度。
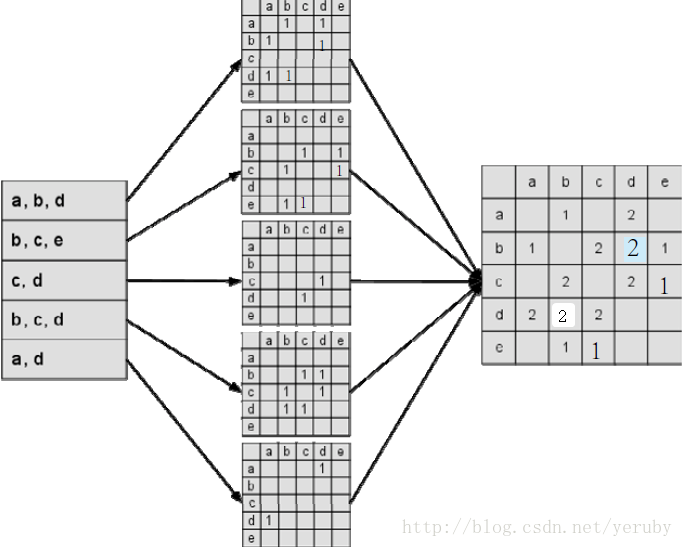
举例,用户A对物品a、b、d有过行为,用户B对物品b、c、e有过行为,等等;
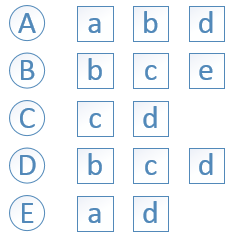
建立物品相似度矩阵C,其中C[i][j]记录了同时喜欢物品i和物品j的用户数,最后将C矩阵归一化可以得到物品之间的余弦相似度矩阵:
2.根据物品的相似度与用户的历史行为给用户生成推荐列表
ItemCF通过如下公式计算用户u对一个物品j的兴趣:

N(u)是用户喜欢物品的集合,S(j,K)是和物品j最相似的K个物品的集合,$w_{ji}$是物品i与物品j的相似度,$r_{ui}$是用户u对物品i的兴趣(隐式反馈数据如果用户u对i有行为可假设$r_{ui}=1$).
该公式的含义是:和用户历史上感兴趣的物品越相似的物品,越有可能在用户的推荐列表中获得比较高的排名。
一个例子:
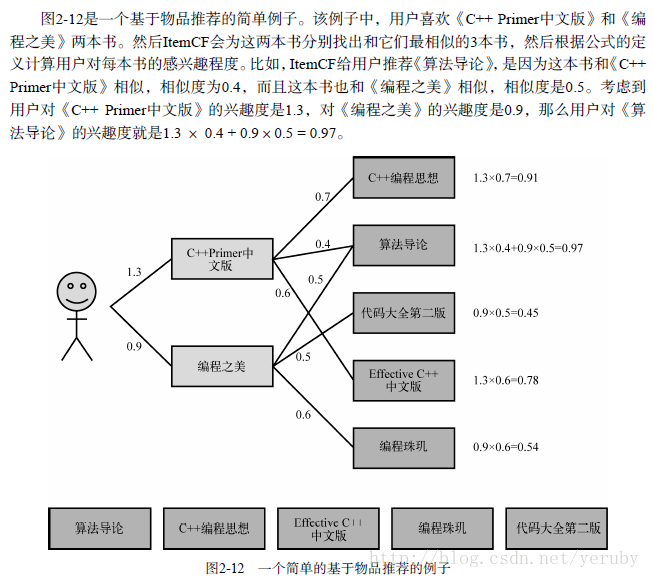
二、算法的优化
1.用户活跃度对物品相似度的影响(ItemCF-IUF)
认为活跃用户对物品相似度的贡献应该小于不活跃的用户,所以增加一个IUF(Inverse User Frequence)参数来修正物品相似度的计算公式:
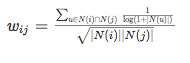
2.物品相似度的归一化(ItemCF-Norm)
Karypis在研究中发现如果将ItemCF的相似度矩阵按最大值归一化,可以提高推荐的准确度。其研究表明,如果已经得到了物品相似度矩阵w,那么可用如下公式得到归一化之后的相似度矩阵w':
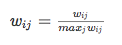
最终结果表明,归一化的好处不仅仅在于增加推荐的准确度,它还可以提高推荐的覆盖率和多样性。
用这种相似度计算的ItemCF被记为ItemCF-Norm。
《推荐系统实践》读书笔记,部分图片来自网络。