An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling
Original time: 2018-05-16 16:09:15
Updated on 2019-09-27 10:26:42
Paper: https://arxiv.org/pdf/1803.01271.pdf
Code:http://github.com/locuslab/TCN
1. Background and Motivation:
一提到时序建模,大部分人第一反应是 RNN, LSTM;而最近有些工作表明,CNN 在某些时序任务上也取得了顶尖的实验效果。那么,问题来了,这个序列 CNN 模型,是只对某些特定的任务有效,还是对很多任务都可以建模呢?本着这个动机,作者进行了充分的实验,并且结合最新的一些 CNN 方面的技巧,重新设计了 sequential CNN 模型,提出了 TCN, 网络结构,用卷积的方式进行序列数据的处理,并且取得了和更加复杂的 RNN、LSTM、GRU 等模型相当的精度。作者在文中提到:sequence modeling 和 recurrent networks 之间的常规联系,应该被重新认识。TCN 的网络结构不但比 LSTM GRU 等取得了更好的效果,并且结构也更加简单,明了。对于后续的序列建模问题,可能是一个新的起点。
Temporal Convolutional Networks :
TCNs 的特点有:
1). the convolutions in the architecture are casual, meaning that there is no information "leakage" from future to past;
2). the architecture can take a sequence of any length and map it to an output sequence of the same length, just as with an RNN.
3). we emphasize how to build very long effective history size using a combination of very deep networks and dilated convolutions.
1. Sequence Modeling :
输入是一个序列,如:x0, ... , xT;对应输出的 label 是 y0, ... , yT。而序列模型就是要学习这么一个映射函数,从输入到输出,即:
![]()
但是,这种方法以 autoregressive prediction 为核心,但是,不能直接捕获下面的 domain:machine translation, or sequence to sequence prediction,因为:在这些情况下,整个的输入可以被用来预测每一个输出(since in these cases the entire input sentence can be used to predict each output)。
2. Casual Convlutions :
TCNs 是基于两个原则的:
(1)the fact that the network produces an output of the same length as the input(输入和输出保持一致),
(2)the fact that there can be no leakage from the future into the past(从未来到过去,没做信息泄露).
为了满足第一点,TCNs 采用全卷积网络结构。每一个 hidden layer 和 input layer 是相同的,and zero padding of length (kernel size -1) is added to keep subsequent layers the same length as previous ones.
为了满足第二点,TCNs 采用 casual convolutions, where an output at time t is convolved only with elements from time t and earlier in the previous layer.
那么,TCNs 就是:TCN = 1D FCN + casual convolutions.
这种基本的设计方法的主要不足之处在于:为了得到一个较长的历史尺寸,我们需要一个非常深的网络 或者 非常大的 filters。
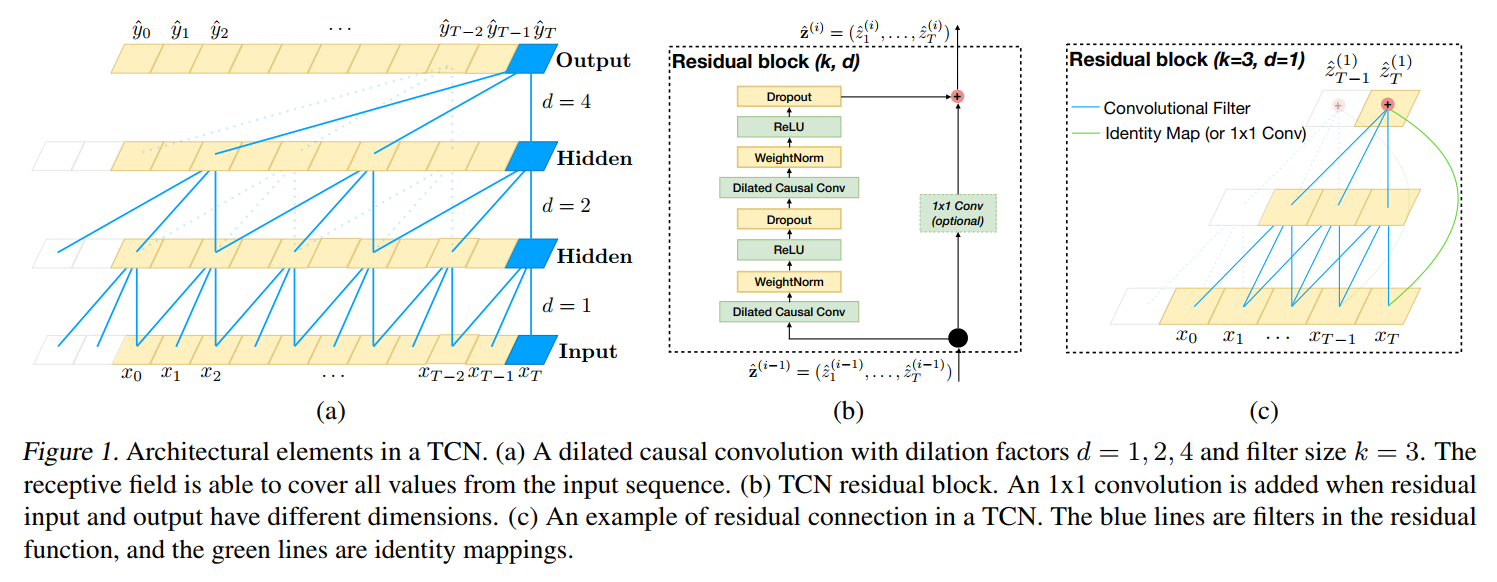
3. Dilated Convolutions :
为了使得 filter size 尽可能大,我们采用 dilated convolutions,that enable an exponentially large receptive field.
正式的,对于 1-D sequence input x , 以及 a filter f , 空洞卷积操作 F 在输入序列中元素 s 可以定义为:
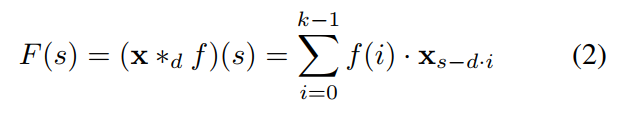
其中,d 是空洞系数,k 是filter size,s-di accounts for the direction of the past.
Using larger dilation enables an output at the top level to represent a wider range of inputs, thus effectively expanding the receptive field of a ConvNet.
这给我们增加 TCN 的感受野,提供了两个思路:
(1). choosing larger filter sizes k ;
(2). increasing the dilation factor d, where the effective history of one such layer is (k-1)d.
4. Residual Connnections :
此处的残差连接,就是借鉴了何凯明的 residual network,即:将之前的信息和转换后的信息,都作为当前的输入,从而使得网络层数非常深的时候,仍然能够得到不错的效果:
![]()
This effectively allows layers to learn modifications to the identity mapping rather than the entire transformation, which has repeatly been shown to benefit very deep networks.
5. Discussion :
本小结总结了 TCN 用于 sequence modeling 的几个优势和劣势:
(1)Parallelilsm RNN 的预测总是需要上一个时刻完毕后,才可以进行。但是 CNN 的则没有这个约束,因为 the same filter is used in each layer.
(2)Flexible receptive field size TCN 可以在不同的 layer 采用不同的 receptive field size。
(3)Stable gradients 不同于 RNN 结构,TCN has a backpropagation path different from the temporal direction of the sequence. 所以 TCN 就没有 RNN 结构中梯度消失或者梯度爆炸的情况。
(4)Low memory requirement for training LSTM or GRU 由于需要存储很多 cell gates 的信息,所以需要很大的内存,但是由于 filter 是共享的,内存的利用仅仅依赖于网络的深度。而作者也发现:gated RNNs likely to use up to a multiplicative factor more memory than TCNs.
(5)Variable length inputs TCNs can also take in inputs of arbitrary length by sliding the 1D convolutional kernels.
两个明显的劣势在于:
(1)Data storage during evalution.
(2)Potential parameter change for a transfer of domain.