SalGAN: Visual saliency prediction with generative adversarial networks
2017-03-17
Paper: https://arxiv.org/abs/1701.01081
Official Theano Code: https://github.com/imatge-upc/salgan [Poster]
Unofficial PyTorch Code: https://github.com/batsa003/salgan/
摘要:本文引入了对抗网络的对抗训练机制来进行显著性物体的预测。显著性可以作为 soft-attention,来引导其他计算机视觉任务的进行,也可以直接引导 marketing 领域。
本文区别于其他方法最显著的地方在于:the usage of generatvie adversarial networks。本文将训练分为两个阶段:
1. 产生器产生一个服从训练集合的伪造的样本;
2. 判别器就是用于判断给定的样本是 真实的 还是 伪造的。
本文中谈到的 data distribution 意思是:实际的图像 和 对应的显著性图。
本文总结的贡献点是:
1. 探索了 GAN 在显著性物体检测上的应用,在某些数据集上取得了不错的效果;
2. 在训练 DCNN 时,应用 二元交叉熵损失函数 和 下采样显著性图 是可以提升效果的。
本文的网络框架设计如图所示:
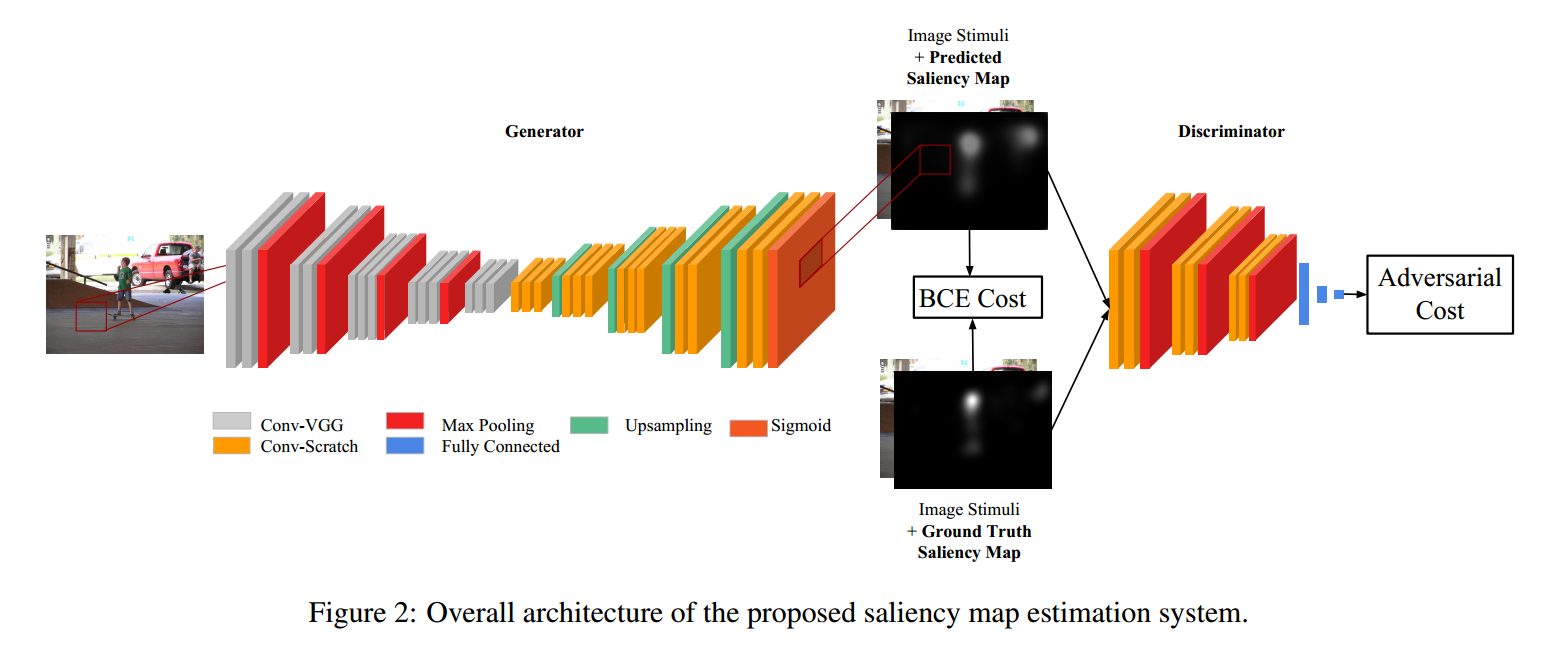
网络结构分析:
1. 产生器:
Convolutional encoder-decoder architecture
2. 判别器:
就是一个 CNN 结构。
训练(Training):
1. Content Loss
由于 产生器 部分的输出是 saliency map,要计算的这部分就是:输出的 saliency map 和 gt saliency map 之间均方差 loss 。
用的就是 两个 map 之间的欧式距离:

本文中 MSE 就是用来作为 baseline 的,因为大部分显著性检测的方法都是基于这个 loss function。GT saliency maps 被归一化到 0-1 之间。
这里用到了 二元交叉熵损失函数:

2. 对抗损失
关于 GAN 这里就不在介绍了,那么显著性检测和 gan 有什么不同呢?
1. 首先,目标是拟合一个 决策函数 来产生实际的 saliency values,而不是从随机的 noise 中得到 真实的图像;
这样的话,输入给产生器的东西就不再是 随机的 noise,而是一张图像;
2. 其次,显著性所对应的图 是衡量质量的;
所以我们将图像和 saliency map 作为输入给产生器
3. 最后,在 GAN 产生图像的时候,没有 gt 进行对比,属于无监督学习;
但是,在显著性检测的时候,我们是有现有的 gt 作为对比的。
我们发现产生器函数更新的时候,我们发现 利用判别器的loss 和 对比gt得到的交叉熵损失函数,可以显著地提升对抗训练的稳定性和收敛速度。
最终的 loss function 可以定义为:

实验结果:
