Unsupervised Image-to-Image Translation Networks --- Reading Writing
2017.03.03
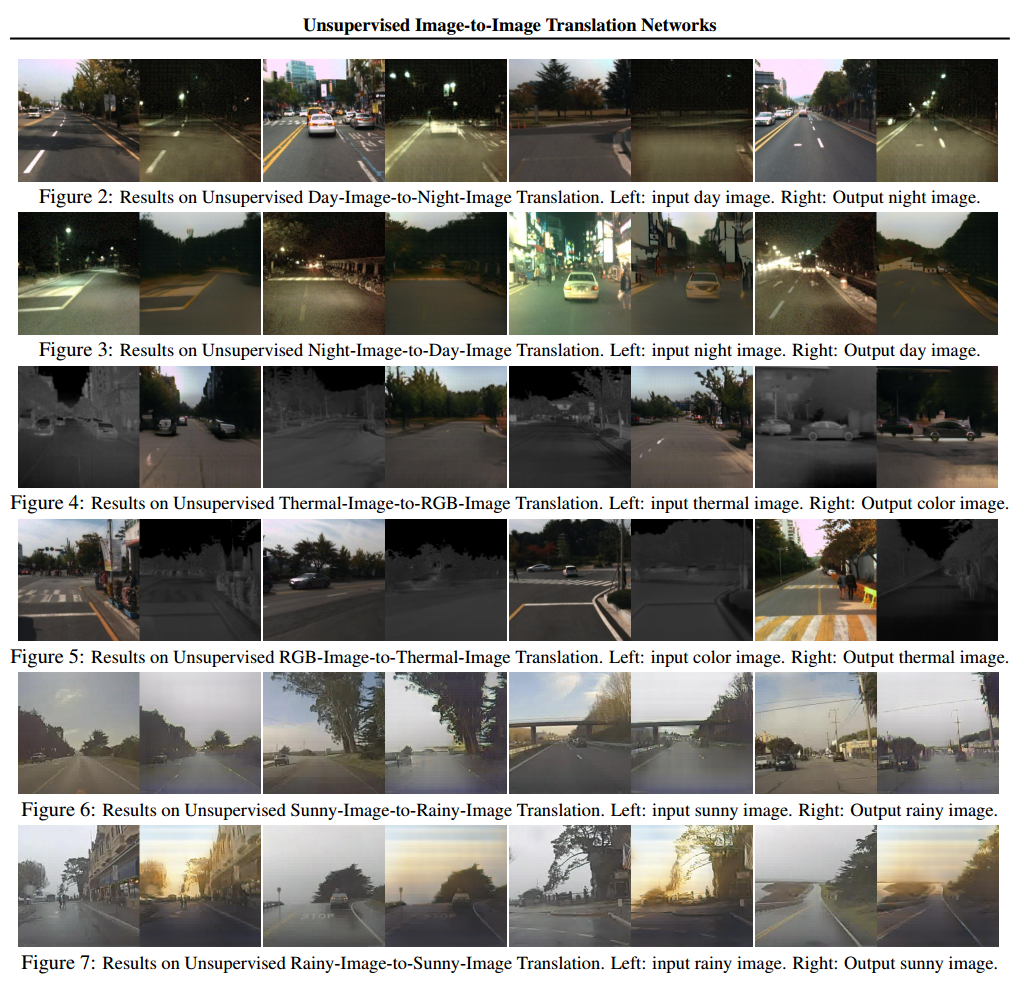
Motivations: most existing image to image translation algorithms are all need image pairs as training data for deep neural network, such as CGANs or VAEs. But in some cases, it is rather difficult to collect such training data. For example, the night and day image pairs, the perfect aligned thermal RGB image pairs, or sunning rainning, fogging, et al, which provide us a new challenging problem:
How to do image to image translation in a unsupervised fashion which do not need aligned image pairs ?
This paper proposed the UNIT framework (UNsupervised Image-to-image Translation network) to deal with this problem which combine VAE and GANs. The whole framework can be described as the following figures which seems complex but rather easy to understand.

There are two most important assumptions about the proposed framework:
1. we assume that the relationship between X1 and X2 does not only exist at the image level but also at the level of local patches or regions.
2. for any given images x1 and x2, there exists a common underlying representation z, such that we can cover both images from this underlying representation from each of the two input images.
VAEs: the encoder-generator pair {E1, G1} constitutes a VAE for the X1 domain, termed VAE1. Another pair of {E2, G2} constitutes a VAE for the X2 domain VAE2.
Weight-sharing : we enforce a weight-sharing constraint to relate the representations in the two VAEs.
GANs : two GANs are used to output the two domains.



Experiments: