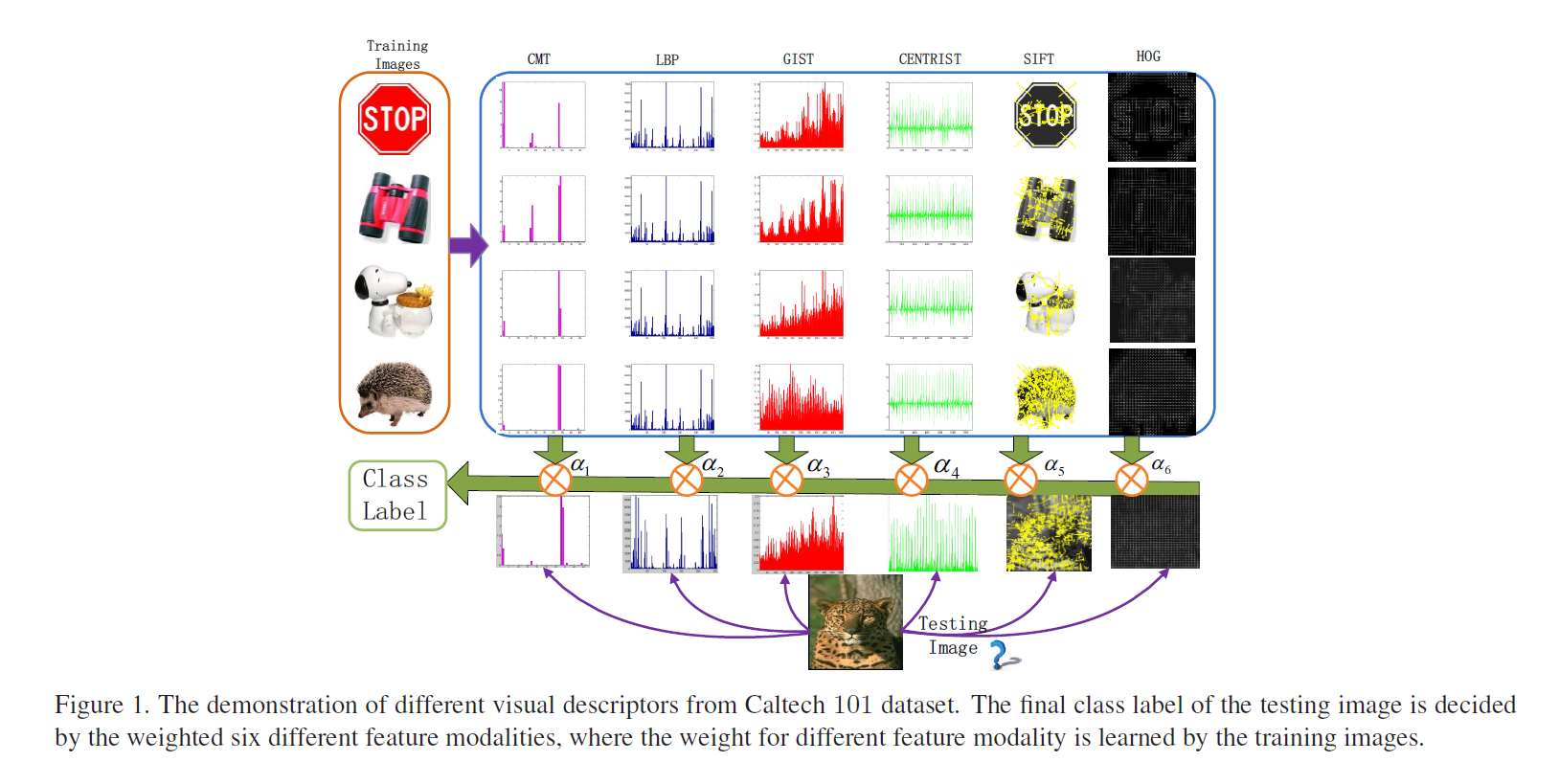
Heterogeneous Image Features Integration via Multi-Modal Semi-Supervised Learning Model
ICCV 2013
Paper:http://www.escience.cn/system/file?fileId=72247
Code:http://www.escience.cn/people/fpnie/papers.html
本文提出了一种结合多种传统手工设计 feature 的多模态方法,在 label propagation 的基础上进行标签传递,进行半监督学习,综合利用各种 feature 的优势,自适应的对各种feature 的效果进行加权,即:对于判别性较好的 feature给予较高的权重,较差的 feature 给予较低的权重,然后将整个流程融合在一个框架中进行学习。
关于基于 Graph 的标签传递的基础知识,请参考具体论文,或者本博客的博文“Dynamic Label Propagation for Semi-supervised Multi-class Multi-label Classification”。
下面的公式即为所提出的 general 的 framework:
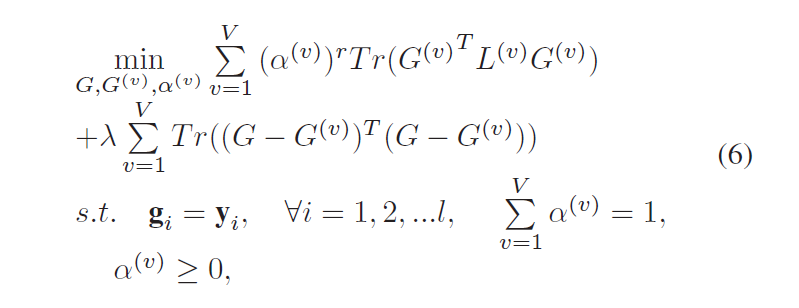
其中,这个公式主要有 3个成分,即:各个feature 所占的权重 $alpha^{(v)}$,V 是所有feature类别总数,$G^{(v)}$ 是第 v 个特征对应的类别标签矩阵 (class label matrix),$G$ 是我们所感兴趣的 比较趋于一致的 类别标签矩阵。通过求解该公式,同时得到 $G^{(v)}$, $G$, $alpha^{(v)}$。
由于该框架并非凸的,那么无法直接对其进行求解,那么我们要做的就是将其拆分为 3个 步骤,分别进行求解,即:
Step 1: 固定 $G^{(v)}$, $G$, 然后先求解 $alpha^{(v)}$:
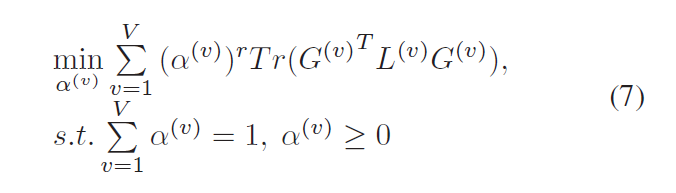
然后这个子问题,就可以利用拉格朗日乘数法进行求解,因为这是一个带有约束的最小值问题。
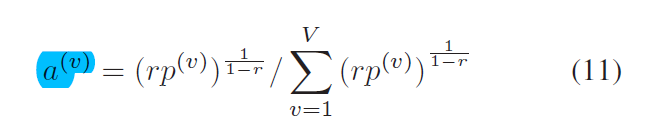
然后可以求解得到公式(11),即为各个模态的权重,但是 蓝色加深字体,可能是作者笔误,我认为这里应该是 $alpha^{(v)}$才对,因为求得就是这个,不知道为何弄出一个 $a^{(v)}$出来。额。。。
Step 2. 就是固定已经求出的 $alpha^{(v)}$ 以及 $G$,然后去求解 $G^{(v)}$:
将上述问题转换为:
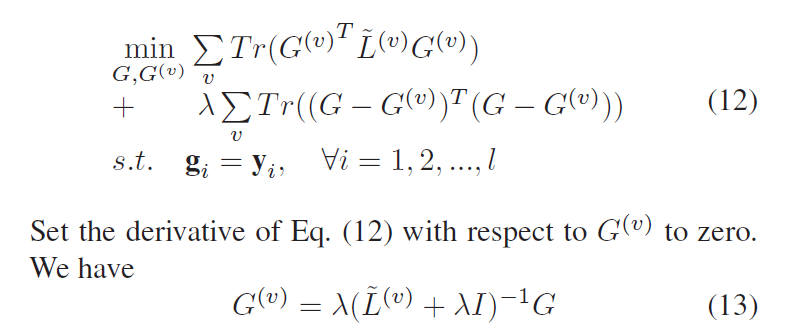
可以得到公式(13),即为所求。
Step 3. 固定已经求出的 $alpha^{(v)}$ 以及 $G^{(v)}$,然后去求解 $G$:
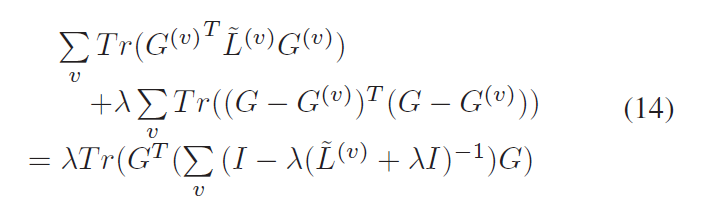
由此可以得到:
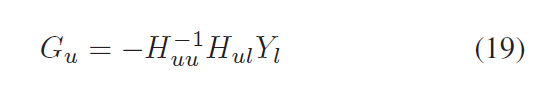
迭代的进行上述三个步骤,直至收敛。
最后一步,就是将所得到的标签向量取最大值,作为对应样本的标签,即:

完整的算法流程如下:

本文的实验部分,做的比较充分,在 4个数据集上进行了验证。本文所要验证的主要问题就是,这种方式自适应加权的 feature 组合可以得到更好的标签传递效果。