(译) 强化学习 第一部分:Q-Learning 以及相关探索
Q-Learning review:
Q-Learning 的基础要点是:有一个关于环境状态S的表达式,这些状态中可能的动作 a,然后你学习这些状态下他们action的值。直观的讲,这个值,Q,是 状态-动作值(state-action value.) 所以,在Q-Leaning中,你设置初始 状态-动作值为0,然后你去附近溜溜并且探索 状态-动作空间。在你试了一个状态下的某一动作之后,你会评价将会转向哪一个状态。如果该动作将导致一个不想要的输出,你减小在那个状态下,那个动作的Q值,才能使得其他动作将会得到一个较大的值,这样在下一次你处于当前状态下时,才可能被选中,从而替换掉这次所执行的那个动作。同样的,如果你执行的那个动作得到了奖励,那么在那个状态下,该动作的权重将会被增加,所以当你在那个状态下时,你可能会再一次的选择该行动。重要的是,当你更新Q的时候,你也在更新之前的 状态-动作组合。只有你看到结果的时候,你才能更新Q。
让我们首先看一个 “猫抓耗子” (cat vs mouse) 的例子,当然了,你是老鼠。一只猫就在你的眼前,你选择直走,就会碰到猫,然后被吃掉,身为耗子,当前不希望自己就这样JJ了,所以,你必须减小在那个情况下,选择那个动作的权重,所以,当你再一次的出现在猫眼前时,你就会选择从一侧闪过或者往后倒退(除非你有重生技能,那就不用担心被吃的问题了)。注意到,当没有猫在你面前时,你并不会减小前进的权重,我们要前进搜索食物啊,所以,除非有猫站在你面前,否则都不会影响你前进的步伐。相反的情况下,当你面前有奶酪的时候,你选择了前进,那么你就会得到奖励。当下一次,有奶酪出现在你眼前,你就会很有可能选择“Move Forward”,因为你上次执行该操作得到了奖励。
假设我们又是老鼠了,我们当前的状态是:奶酪就在我们面前一步,但是我们还没有学习任何事情,(action box 中的空白代表 0)。所以我们随机的选择一个动作,并且假设我们恰巧选择了“Move Forward”。如下图所示:
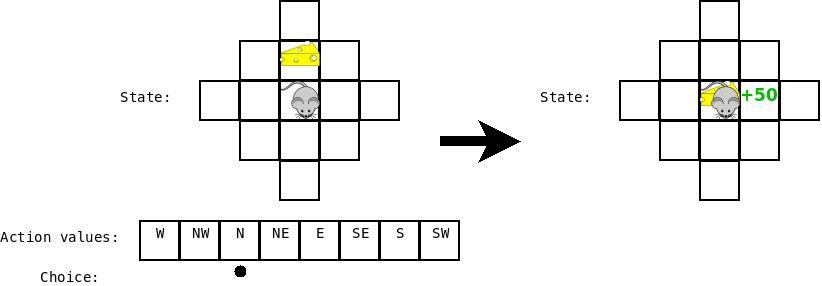
那么,在这种情况下,我们就得到了奖励,所以我们就可以返回来更新对应“Cheese is one step ahead”以及动作“Move Forward”的Q值,然后增加那个状态下对应“Move Forward”的值。
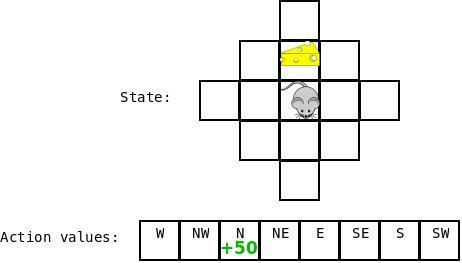
然后假设现在奶酪被移动了,然后我们又要四处移动了,现在我们的状态是:“cheese is two steps ahead”,然后我们做出移动,达到的目的是:“cheese is one step ahead”。
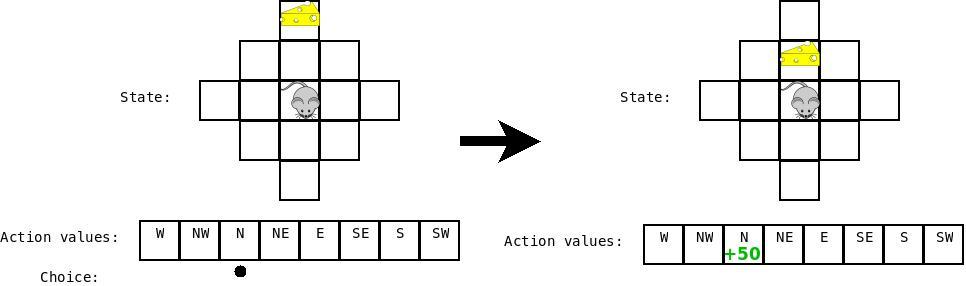
当我们要更新上一次 state-action combination 的Q值时,我们考虑状态“cheese is one step ahead”的所有Q值。我们看到他们这些值中有一个是非常高的(对应于动作“Move Forward”) 并且该值结合到上一次 state-action combination 的更新之中去。

特别地,我们更新利用公式:$Q(s, a) = alpha * (reward(s, a) + max(Q(s')) - Q(s, a))$ 其中,s是之前的状态,a是之前的行动,$s'$ 是当前的状态,$alpha$ 是衰减因子(此处设置为 0.5)。
直观上来看,为了执行状态s下的动作s而改变Q值 和 实际的奖励 $(reward(s, a) + max(Q(s'))$与期望的奖励 $Q(s, a)$乘以一个学习率 $alpha$ 不同的。你可以将此想象成一种PD control(我想问,什么是PD control ?),驱使你的系统朝向目标,也就是这种情况下的正确的Q值。
此处,我们评价向前移动的奖励,当奶酪在前方两步的时候,由于移动到那个状态(0)的奖励,加上从那个状态得来的最好的行动带来的奖励(moving into the cheese +50),减去 那个状态下(0)期望的值,乘以我们的学习率(0.5) = +25.
Exploration:
最直观的运行Q-Learning,state-action values 被存贮在一个查找表当中。所以,我们有一个巨大的表格,大小为:$N*M$,其中N是不同可能状态的个数,M是不同可能动作的个数。所以,当做决定的时候,我们简单的浏览下表格,寻找那个状态的对应的动作值,选择最大的:
- def choose_action(self, state)
- q = [self.getQ(state, a) for a in self.actions]
- maxQ = max(q)
- action = self.actions[maxQ]
- return action
还有一些额外的东西需要添加。
首先,我们需要处理存在多个动作具有相同值的情况。为了处理这种情况,我们随机的挑选一个值进行处理:
- def choose_action(self, state):
- q = [self.getQ(state, a) for a in self.actions]
- maxQ = max(q)
- count = q.count(maxQ)
- if count > 1:
- best = [i for i in range(len(self.actions)) if q[i] == maxQ]
- i = random.choice(best)
- else:
- i = q.index(maxQ)
- action = self.actions[i]
- return action
这就可以让我们摆脱那种情况的影响,但是如果我们曾经恰巧碰到一个不错的选择,我们将总是选择这个,即使存在一个更好的选择。为了克服这种问题,我们将引入一个额外的项目,$epsilon$。我们接着随机的产生一个值,如果那个值小于 $epsilon$,然后就随机的选择一个动作,而不是跟随我们选择最大Q值的常规策略:
- def choose_action(self, state):
- if random.random() < self.epsilon: # exploration action = random.choice
- best = [i for i in range(len(self.actions)) if q[i] == maxQ]
- i = random.choice(best)
- else:
- i = q.index(maxQ)
- action = self.actions[i]
- return action
a