Weakly-Supervised Spatio-Temporally Grounding Natural Sentence in Video
2020-03-08 14:29:35
Paper: https://arxiv.org/pdf/1906.02549.pdf
Code: https://github.com/JeffCHEN2017/WSSTG.git
1. Background and Motivation:

本文提出一个新的数据集,做了一个新的任务:根据语言文本,在视频中定位出想要的目标物体。与现有的弱监督视频定位问题,本文所提出的 WSSTG task 有如下的挑战和优势:
1). 本文目标是根据一个句子进行定位,而不是一个名词或者代词,这样会使得目标表达更加充分和灵活。但是如何的挖掘句子中的语义含义,来实现准确的定位,是该任务的一个重要的挑战之一;
2). 与单张图像中用一个 BBox 表示相比较,spatio-temporal tube 提供了 “dog” (如图1所示)时序上的运动,可以刻画其视觉动态,可以在语义上和给定的句子进行匹配。然而,如何探索和建模时空特性以及他们复杂的关系,也是一个较大的挑战。
为了解决上述的挑战,本文在多示例学习的框架下提出了一种新颖的模型。首先,从给定的视频中提取出一系列的 instance proposals。instance proposal 的特征和语句都用 attentive interactor 进行编码,并且探索出其细粒度的关系来产生语义上的匹配行为。最后,本文提出一种 diversity loss,将其和 ranking loss 一起来训练整个模型。在测试阶段,instance proposal 中和给定的句子具有最强的语义匹配得分的示例,会被作为定位的结果。
2. Method:
本文提出一种基于多示例学习的方法,如图 2 所示,该方法主要包括两个部分,一个是 instance generator,另外一个是 attentive interactor。
2.1. Instance Extraction:
Instance Generation:
如图 2 所示,本文方法的第一步是产生 instance proposal。用的方法是 faster RCNN,得到 frame-level bounding boxes,并且带有置信度得分,然后将这些 instance 连接起来得到 spatio-temporal tubes。假设在时刻 t 和 t+1,有两个 BBox $b_t$ 和 $b_{t+1}$。本文定义了这两个 BBox 之间的连接得分 $s_l$:
![]()
这样的话,一个 instance proposal $p^n$ 可以被看做是整个视频序列上的路径:
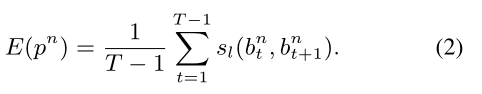
作者用 Viterbi algorithm 得到带有最大能量的 instance proposal。作者将识别出的 instance proposal 保存,然后移除与之相关的其他BBox。将上述过程重复直到没有 BBox 剩余了。这样就可以得到一组 instance proposals P。
Feature Representation:
由于一个 instance proposal 是由连续的视频帧中的 BBox 构成的,本文利用 I3D 模型和 faster RCNN 来产生 RGB feature I3D-RGB,the flow sequence feature I3D-Flow, 以及 frame-level RoI pooled feature。作者平均的将 instance proposal 划分为 $t_p$ 个 segments,并且在每一个 segments 中平均化特征。作者将这三种 feature 组合起来,然后输入到接下来的 attentive interactor 中。将每一个 segment 当做是一个时刻,每一个 proposal p 被表示为 $F_p$,这是一个维度为 $d_p$ 的视觉特征。
2.2. Attentive Interactor:
从视频和给定的句子得到的 instance proposals,作者提出一种 attentive interactor 来刻画不同 proposal 和 sentence 之间的匹配关系。所提出的 attentive interactor 包含两个连接的成分,分别是 interaction 和 matching behavior characteristic,如图 3 所示。
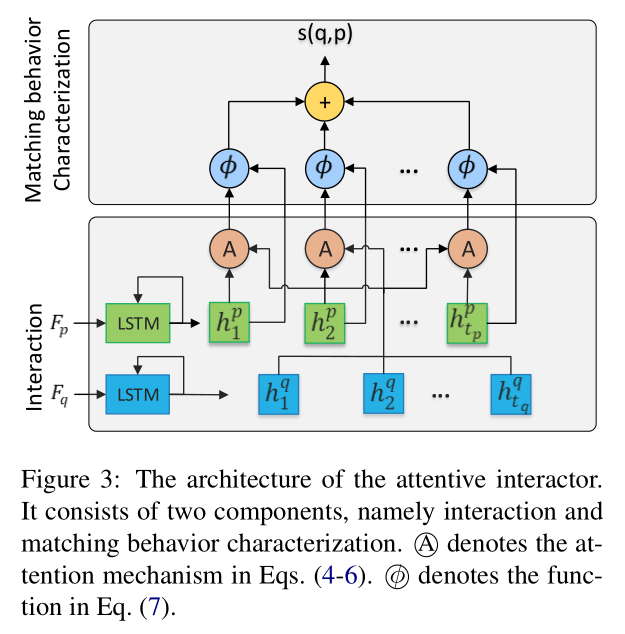
在进入到 interactor 的细节之前,我们首先引入 query sentence q 的表达。首先用 word2vec 得到每一个单词的映射,即 300维的向量,并且忽略字典中未出现的单词。按照这种方法,每一个句子 q 可以被表达为 Fq。
2.2.1. Interaction:
作者用两个 LSTM 网络来编码 instance proposal 和 sentence,即:

其中,$f^p_t$, $f^q_t$ 是 Fp 和 Fq 中第 t 行的表示。此外,作者引入 attention 机制将图像和文本之间进行交互:

2.2.2. Matching Behavior Characterization:
在得到一组由视觉引导的句子特征后,作者将 visual feature 和 sentence feature 进行细粒度的匹配。具体来说,第 i 个 visual 和 sentence feature 之间的匹配行为可以定义为: ![]()
这其中最最要的函数,本文实验采用的是 cosine similarity。最终,作者定义了 instance proposal p 和 sentence q 之间的匹配行为如下:
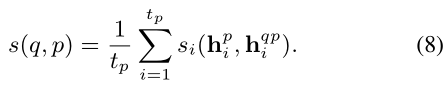
2.3. Loss Function:
本文的优化目标是:ranking loss + diversity loss。
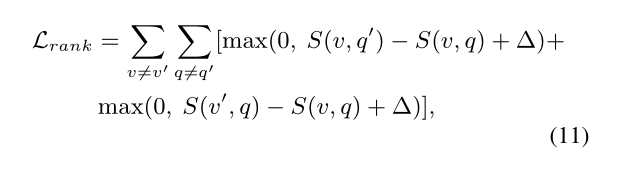

在测试阶段,给定 language 和 video,直接提取他们的 feature,然后选择和 language feature 最匹配的 instance proposal 当做是定位的结果。
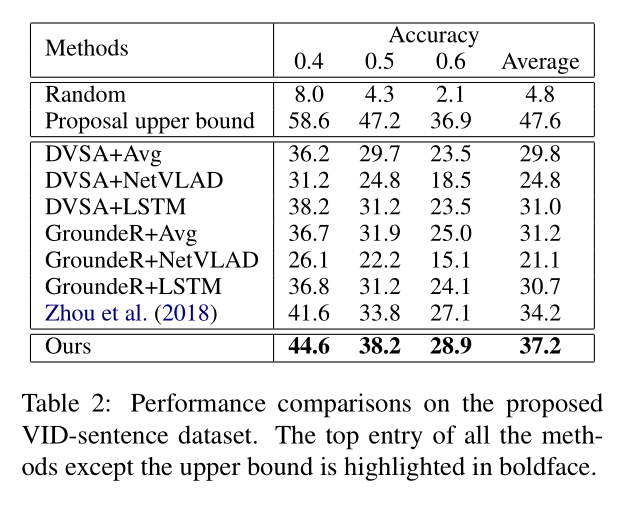
3. Experiment: