DM-GAN: Dynamic Memory Generative Adversarial Networks for Text-to-Image Synthesis
2019-10-12 16:22:38
Paper: https://arxiv.org/abs/1904.01310
Code: https://github.com/MinfengZhu/DM-GAN
1. Background and Motivation:
最近用 GAN 的方法来生成图像的工作开始已经井喷了,其中有一类方法是 Coarse-to-fine 的思路,即先生成低分辨率的初始图像,在优化得到高分辨率的版本。但是这些方法有如下的两个问题:1). 生成的结果严重依赖于初始图像的质量。如果初始图像生成的很差,那么后续的优化也无法得到高质量的图像。2). 输入句子中的单词扮演了不同角色的作用,使得优化过程并不是那么有效。图像的信息应该被考虑用于决定每一个单词的重要性。
所以,作者在本文中提出了 Dynamic Memory Generative Adversarial Network (DM-GAN) 来解决上述问题。对于第一个问题,作者提出添加一个记忆机制来处理 badly-generated initial images。最近的工作也表明记忆网络可以用于编码 knowledge source。受到该工作的启发,作者提出添加 key-value memory structure 到 GAN 的框架中来。模糊的初始图像特征被看做是 queries 来从 memory module 中读取特征。记忆的读取被用于优化初始图像。为了处理第二个问题,作者引入一个 memory writing gate 来动态的选择和产生图像相关的单词。这就使得产生的图像和文本描述能够很好地匹配上。所以,memory component 在每一个图像优化中都可以根据初始图像和文本信息动态的进行写入和读取。此外,并非直接组合图像和记忆,作者用一个响应 gate 来自适应的接收来自 image 和 memory 的信息。

作者总结了其贡献:
1). 提出一个新颖的 GNA model 组合了 dynamic memory component 来产生高质量的图像,即使初始图像很差;
2). 提出一个 memory writing gate 来根据初始图像,选择相关的单词;
3). 提出 response gate 来自适应的融合来自图像和记忆中的信息;
4). 实验结果顶尖;
2. DM-GAN:

如图 2 所示,本文所提出的 DM-GAN model 主要包含两个部分:一个是 initial image generation;另外一个就是 dynamic memory based image refinement。
在第一个阶段,也就是初始图像生成,也是常规套路了。首先用句子编码器将输入的文本描述转换为一种中间的表示(即 sentence feature s 和 多个单词向量 w)。然后,利用深度卷积产生器来得到一个初始图像 x0,该图像可以得到大致的形状和一些细节。
在 dynamic memory-based image refinement stage,更多细粒度的视觉内容被添加到 fuzzy initial image 中,以得到照片级别的图像 xi。该优化阶段,可以重复多次,以得到更好的图像。基于动态记忆的图像优化阶段,主要包含如下四个部分:memory written,key addressing, value reading, and response。
记忆写入操作将 text information 存入到一个 key-value 结构化的记忆单元中,用于后续的检索;
Key Addressing 和 Value Reading 操作被用于从记忆模块中读取特征来优化低质量图像的视觉特征。
Response 操作被用于控制图像特征的融合和记忆的读取。
作者提出 memory writing gate 在基于写入的步骤中,根据图像内容突出重要的单词信息。此外,作者还提出利用 response gate 来自适应的融合从内存和图像特征上得到的信息。
2.1. Dynamic Memory:
假设给定了输入单词的表示 W,图像 x 以及 图像的特征 Ri:

其中,T 是单词的个数,Nw 代表单词特征的维度,N 是图像像素的个数,Nr 是图像像素特征的维度。本文尝试去学习一个模型来更加有效地进行文本和图像信息的融合(通过 nontrivial transforms between key and value memory)来优化生成的图像。优化阶段包含如下四个步骤:
1). Memory Written:
编码先验知识是动态记忆的一个重要部分,这确保了从文本中恢复高质量图像。一种 naive 的做法是仅仅考虑部分文本信息进行记忆的读写:
![]()
其中,M(*) 代表了 1*1 卷积操作,将单词特征映射为 Nm 维的记忆特征空间。
2). Key Addressing:
在这个步骤中,作者利用 key memory 来检测相关记忆。作者将 memory slot mi 和 图像特征 rj 之间的相似概率作为每一个 memory slot 的权重:
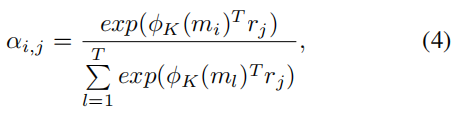
其中,$alpha_{i, j}$ 是第 i 个 memory 和 第 j 个图像特征之间的相似概率,![]() 是 key memory access process,可以将 memory features 映射为 Nr 维,利用的是 1*1 的卷积来实现。
是 key memory access process,可以将 memory features 映射为 Nr 维,利用的是 1*1 的卷积来实现。
3). Value Reading:
输出的记忆表示定义为:根据相似性概率得到的 value memories 的加权求和。

其中,![]() 是 value memory access process,将 memory features 映射为 Nr 维的特征,也是用 1*1 的卷积实现的。
是 value memory access process,将 memory features 映射为 Nr 维的特征,也是用 1*1 的卷积实现的。
4). Response:
在接收到输出记忆后,作者组合了当前图像和输出表示来提供一个新的图像特征。一种 naive 的方法是:直接将图像特征和输出表示进行 concatenate,得到新的图像特征:
![]()
其中, [*, *] 代表 concatenate operation。然后,就可以利用上采样模块和几个残差模块来增强图像的尺寸,以得到更高分辨率的图像。上采样模块包含一个最近邻上采样层 以及 3*3 卷积。最终,优化后的图像 x 可以从新的图像特征中利用 3*3 卷积得到。
2.2. Gated Memory Writing:
并非仅仅利用公式 3 考虑部分 text information,memory writing gate 允许 DM-GAN model 选择相关的单词来优化初始图像。memory writing gate 组合了 图像特征 Ri 和 单词特征 W 来计算每一个单词的重要性:
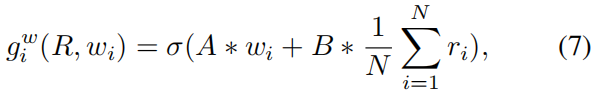
其中,A 是一个 1*Nw 的矩阵,B 是 1*Nr 的矩阵。然后,memory slot 可以通过组合图像和单词特征进行写入:
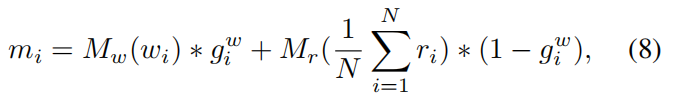
其中,Mw(*) 和 Mr(*) 表示的是 1*1 的卷积操作。这两个操作将 图像和单词特征映射为同一个特征空间,维度为 Nm。
2.3. Gated Response:
作者利用自适应gating 机制来动态的控制信息流动和更新图像特征:

其中, $g_i^r$ 代表用于信息融合的响应门,W 和 b 是参数矩阵和偏置项。
2.4. Objective Function:
产生器网络的目标函数可以定义为:
![]()
其中,$lambda_1$ 和 $lambda_2$ 是权重参数。
Adversarial Loss:
对于 G1 来说的对抗损失可定义为:
![]()
其中,第一项表示 unconditional loss 使得产生的图像尽可能的逼真,第二项表示的 conditional loss 可以使得图像和输入的句子内容保持一致。每一个判别器 Di 的对抗损失为:

其中,unconditional loss 被设计用于判别给定图像是否来自真实图像,conditional loss 决定是否图像和输入到句子相匹配。
Conditioning Augmentation Loss:
Conditional Augmentation technique 被设计用于增广训练数据,并且通过 resampling 来避免过拟合。所以,CA loss 被定义为 标准的高斯分布和训练数据的高斯分布之间的 Kullback-Leibler diversity:
![]()
其中,![]() 是句子特征的均值和协方差矩阵,本文利用 fc layer 来计算这两个指标。
是句子特征的均值和协方差矩阵,本文利用 fc layer 来计算这两个指标。
DAMSM Loss:
本文利用 DAMSM loss 来衡量图像和文本描述的匹配程度。
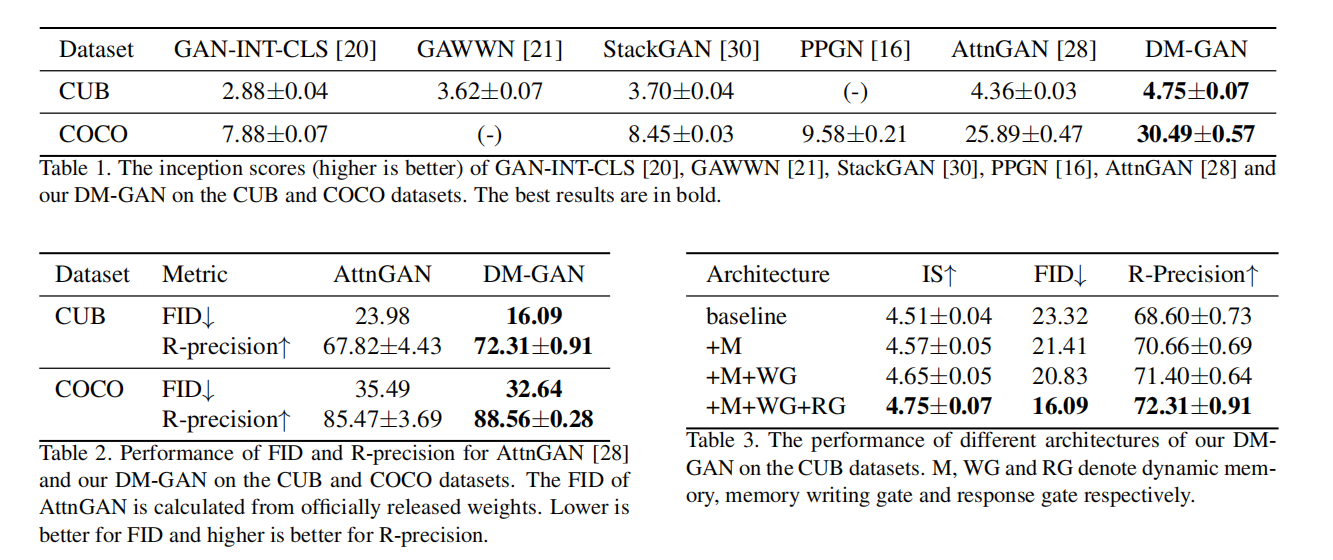
3. Experiments: