ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware
2019-03-19 16:13:18
Paper:https://openreview.net/forum?id=HylVB3AqYm
Code:https://github.com/MIT-HAN-LAB/ProxylessNAS
1. Background and Motivation:
先来看看算法的名字:ProxylessNAS,将其拆分之后是这么个意思: Proxy(代理)Less(扣除)NAS(神经结构搜索),难么很自然的就可以读懂了:不用代理的神经网络搜索。那么问题来了,什么是代理呢?这就要提到本文的动机:NAS 可以自动设计有效的网络结构,但是由于前期所提出算法计算量太大,难以在大型任务上执行搜索。于是,出现了可微分的NAS,大大的降低了 GPU 的运算时间,但是也有一个需要较大 GPU memory 消耗的问题(grow linearly w.r.t. candidate set size)。所以,这些算法就只能在 proxy task 上,例如在较小的数据集上训练,或者仅用几个 blocks 进行学习,或者仅仅训练几个 epoch。这就可能引出如下的问题,算法在小数据上的搜索出来的模型,可能在 target task 上并不是最优的。所以,本文就提出 ProxylessNAS 来直接在 large-scale target tasks 或者 目标硬件平台上进行结构的学习。

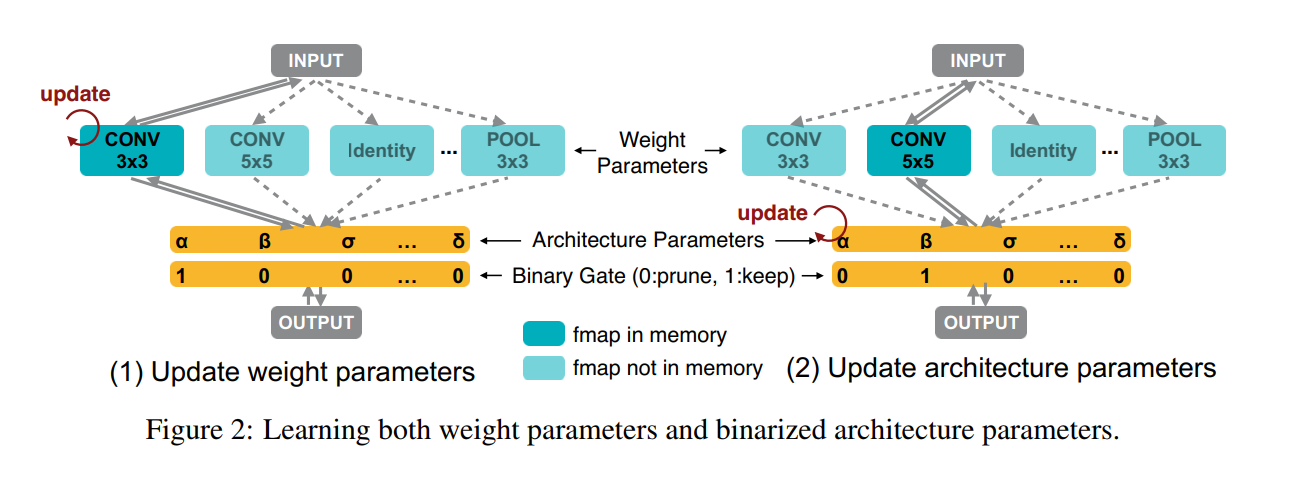
本文作者将 NAS 看做是 path-level pruning process,特别的,我们直接训练一个 over-parameterized network,其包含所有的候选路径(如图 2 所示)。在训练过程中,我们显示的引入结构化参数来学习哪条路径是冗余的,这些冗余的分支在训练的最后,都被移除,以得到一个紧凑的优化结构。通过这种方式,在结构搜索过程中,我们仅仅需要训练一条网络,而不需要任何其他的 meta-controller (or hypernetwork)。
但是简单的将所有的候选路径都包含进来,又会引起 GPU 显存的爆炸,因为显存的消耗是和 选择的个数,呈现线性增长的关系。所以,GPU memory-wise,我们将结构参数进行二值化(1 或者 0),并且强制仅仅有一条路径,在运行时,可以被激活。这样就将显存需求将为了与训练一个紧凑的模型相当的级别。我们提出一种基于 BinaryConnect 的基于梯度的方法来训练二值化参数。此外,为了处理不可微分的硬件目标,如 latency,在特定的硬件上,来学习特定的网络结构。我们将 network latency 建模成连续的函数,并且将其作为正则化损失来进行优化。另外,我们也提出 REINFORCE-based algorithm 作为另外一种策略来处理硬件度量。
2. Method:
作者首先描述了 over-parameterized network 的构建,然后引入如何利用 binarized architecture parameters 来降低显存消耗。然后提出一种基于梯度的方法,来训练这些 binarized architecture parameters。最终,提出两种基础来处理不可微分的目标(e.g. latency),使其可以在特定的硬件上处理特定的神经网络。
2.1 Construction of Over-Parameterized Network:
==