论文地址
https://arxiv.org/pdf/1911.02549.pdf
官网地址
github
https://github.com/mlcommons/inference
MLPerf是什么?
Fair and useful benchmarks for measuring training and inference performance of ML hardware software and service
用于机器学习(大部分是深度学习)的性能测试基准
相关概念
LoadGenerator:负载生成器,MLPerf使用它生成不同的测试场景对inference进行测试
SUT:被测试系统
Sample:运行inference的单位,一个image或者一个sequence
query:一组进行推理的N个样本
Latency:LoadGenerator将query传递到SUT,到Inference完成并收到回复的时间
Tail-latency:论文中并没有对Tail-latency的明确解释,我在网上找到了一段解释,
Tail latency is the small percentage of response times from a system, out of all of responses to the input/output (I/O) requests it serves, that take the longest in comparison to the bulk of its response times
尾部延迟是指在一个系统提供的所有输入/输出(I/O)请求的响应中,与大部分响应时间相比,花费时间最长的那一小部分。
就是说如果在系统中引入实时监控,总会有少量响应的延迟高于均值,我们把这些响应称为尾延迟(Tail Latency)
这大概能说明了tail-latency所代表的含义,只不过结合论文来看,本文所提到的tail-latency并不是一个表示延迟的数据,而是百分比
latency是一个数字,表示时间,tail-latency是一个百分比,我认为是所有latency中的后百分之几,还有一点,sample与latency应该是一一对应的,一个sample就有一个latency
设计Benchmark面临的问题
1.模型选择
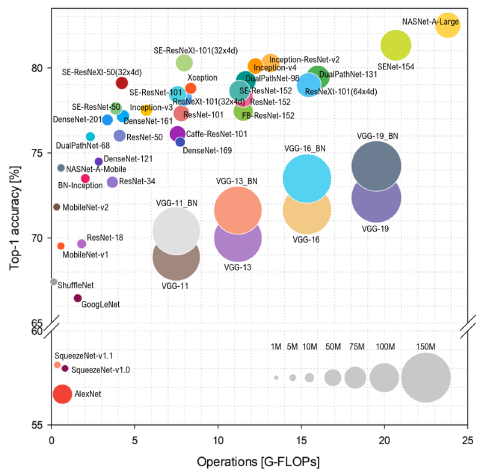
横坐标表示网络需要运算的次数,也就是模型的计算量(S表示gpu运算性能,s表示网络要运算的次数),纵坐标表示置信度最高的类的准确率,面积越大表示参数量越大,模型各有优缺点,需要在各种因素之间需要权衡
2.部署场景的多样性
对于offline场景,比如图片分类,要求将图片在内存中随时可用才能保证加速器达到峰值性能。但是在实时程序中如自动驾驶,模型要持续处理数据流而不是一口气载入全部数据,只有在设备上的推理延迟并不能满足实际应用的需求。
3.推理系统的多样性
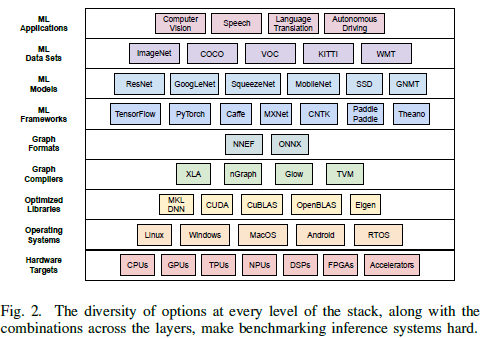
上层应用到底层设备的栈图,每一层都有多种组合,导致推理系统的基准很难确定
Benchmark设计
1.选取有代表性,泛用场景多的模型
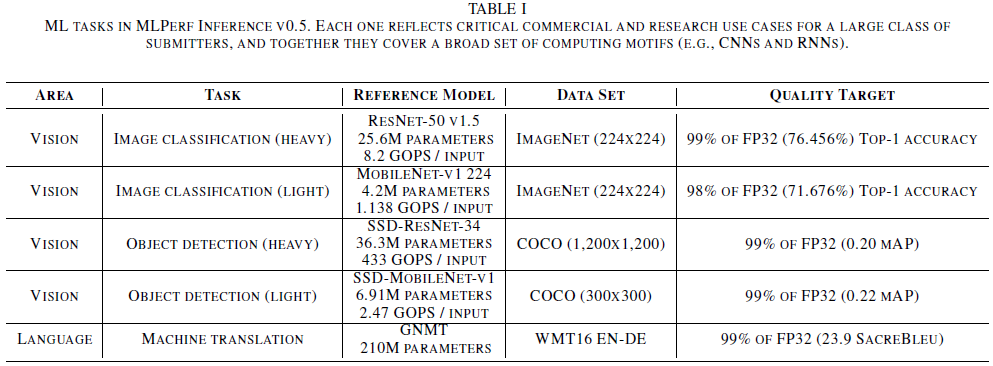
2.健全的质量目标
不同应用领域对于模型指标的要求不一样,有的侧重准确率,有的侧重吞吐量有的侧重延迟
3.终端应用场景
MLPerf提供了四种inference的场景,四种测试场景的主要区别在于请求是怎样发送和接收的
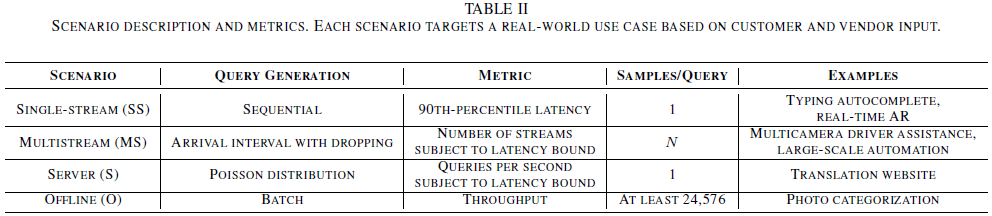
a.single-stream
一次查询送入系统一个样本,到上个请求的响应之前不会发送下一个请求,性能指标是90%的延迟.请求是串行送入系统的,当一个请求处理完后,记录下他的处理时间并传入下一个请求,假如有1000个样本,90th-percentile latency我认为是将1000个样本的延迟记录下来从小到大排列,第900个样本的处理时间就是这个系统的性能指标
b.multi-stream
以固定的时间间隔发送请求(这个时间间隔就作为Multi-stream场景中的延迟边界,一般为50~100ms),一个请求中含有N个样本,当所有查询的(latency)延时都在(论文说99%)延迟边界中时,这时每个请求中包含的样本数N就是系统的性能指标。如对图像分类任务,正好50ms内处理完所有(论文说99%)query,query中的样本个数N再大就处理不完了(有1%处理不完),那么这个N就是系统的性能指标
c.server
为了模拟现实生活中的随机事件,请求将以泊松分布送入被测试系统中。每个请求只有一个样本,系统的性能指标是在延迟边界(latency bound)内每秒查询次数(QPS)。
延迟边界内每秒请求次数:服务器应用场景的性能指标是泊松参数(期望?),即满足要求下的qps(每秒查询次数)值。
这个要求是对于机器视觉任务最多只能有1%的请求超时,对于翻译任务最多只能有3%的请求超时
怎样才算超时:根据任务的不同,延迟的边界在15~250ms
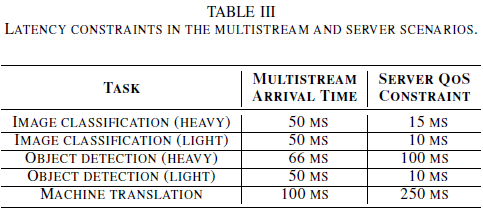
以轻量级框架的图像分类任务来举例,他的性能指标是QPS,怎样找到这个QPS呢,当QPS正好有99%的请求server可以在10ms内处理过来,有1%会超时来不及处理,QPS再大的话就会有超过1%的请求超时,这时这个QPS就是系统的性能指标
个人想法:server场景下的query之间时间间隔服从泊松分布,因此假设query的发送是均匀的,那么他的周期就是泊松分布的期望E,频率就是1/E,正好就是QPS,所以我猜想server的inference测试就是通过不断调整泊松分布的期望,来找到系统的真实负载
d.offline
一次请求将所有的测试样本送入到被测试系统中,被测试系统可以一次或多次以任何顺序返回测试结果,Offline场景的性能评判标准是每秒推理的样本数(论文中的原话是throughput measured in samples per second,单位时间的吞吐量,也就是吞吐率,所以我认为它指的是每秒处理的样本数)
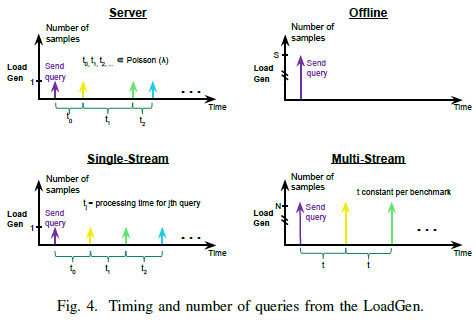
server场景和offline场景都是针对数据中心的,而single-stream和multi-stream是针对边缘计算和物联网的
统计学置信度上的尾部延迟边界
这段有什么用?其实就是根据tail-latency来计算出测试模型需要的最少样本数
按照统计学知识,通过置信区间和尾部延迟来得到满足系统的最小推理数量(要进行多少次inference)
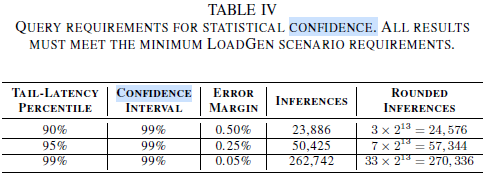
置信区间上的查询需求,所有结果必须满足系统对应应用场景的最小需求
置信区间我认为是latency的置信区间(99%,也就是latency的均值加减3倍标准差)
这个99%置信区间选取的有什么意义?我是这样认为的,系统存在一个性能指标(latency),这个性能指标是切实存在的,但是我们不知道,我们的目的就是通过测试来测出他,假设我们进行测试的样本的latency满足一个正态分布,那么根据区间估计,当取latency均值加减3倍标准差时,置信区间为99%,也就是说这个客观存在的性能指标有99%的概率在我们的数据中,换句话来说就是我们的测试结果有99%的置信度。

公式1,2求出了错误边缘和请求次数,他们之间的关系:直观理解就是自变量为tail-latency,因变量是error margin和numqueries
如当tail-latency从90%变为99%表示可以用来测试inference的sample变多了,不合格样本表少了,所以他的错误边界就变小了,同时可以用来测试的inference变多也表示numqueries变多
结合表4当tail-latency取值为90%时,用于测试inference的样本数为23886,近似估计为3x2^13,tail-latency渠道99%时,测试inference的样本数为262742,近似估计为33x2^13或者270k
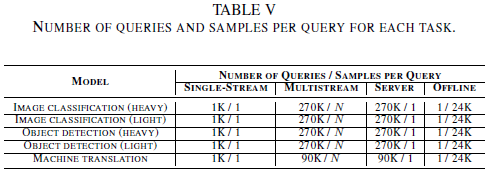
不同任务的请求数量和请求中的样本个数
最后一些其他要求:
multi-stream和server要测试多次,multi-stream的测试时间要在2.5~7h,server的测试结果要测五次取最小值
所有的benchmark运行时间最小是60s